
Troubleshooting AWS Batch And Minimizing Costs
ACM.338 Trying to Make AWS Batch work with custom roles and minimal resources ~ and rethinking my strategy
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
⚙️ Check out my series on Automating Cybersecurity Metrics | Code.
🔒 Related Stories: AWS Security | Secure Code | Batch | IAM
💻 Free Content on Jobs in Cybersecurity | ✉️ Sign up for the Email List
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
In the last post I created AWS Batch roles and policies with CloudFormation.
What is strange is that I basically copied the policies from the AWS IAM console that the AWS Batch and ECS documentation claims it uses and I’m getting errors.
The only two permissions I took out was the ability to create new Service-Linked roles and the ability to call a Chinese service endpoint. The latter should not be required since the US-based or other regional endpoints should work for whatever reason that endpoint exists in the documentation. The error messages do not relate to Service Linked Roles as far as I can tell.
I also removed some Conditions which CloudFormation would not let me deploy. That should increase, not decrease what the roles can do. I might try to lock the policies down further in some way to prevent whatever that is supposed to prevent.
I was manually testing my roles in the last post when I got errors. I created a Compute Environment, Job Queue, Job Definition, and Job.
Let’s troubleshoot the errors one by one and see what we discover.
Refresh the Jobs list if you don’t see your jobs.
First of all, I figured out that there seems to be an error in the Batch Jobs list. I wrote about that here. I can’t see my jobs until I refresh. One problem solved.
Can’t delete compute environments
I wrote about not being able to delete compute environments here and discovered that it was due to a missing permission.
Why is this not related to the user who is deleting the resource instead? Not sure. Here’s the message:
assumed-role/BatchComputeEnvironmentRole/aws-batch is not authorized to perform: ecs:DeleteCluster on resource:
Problem: Not only does this role apparently not have the correct permissions, I was able to delete the role even though it is in use by AWS Batch.
Solution: Even though this is not a Service-Linked role, it seems like restrictions should exist to prevent deletion of roles in IAM when other resources are still using them. That restriction should be in place for any resource, role and service, because this same issue causes weird problems in KMS policies.
OK, let’s try to fix it. I’m going to manually recreate the role and grant it the permission.
Problem: I can’t delete a compute environment because the role is missing.
Solution: Create the role with the appropriate service and policy.
I create a role for the AWS Batch service:
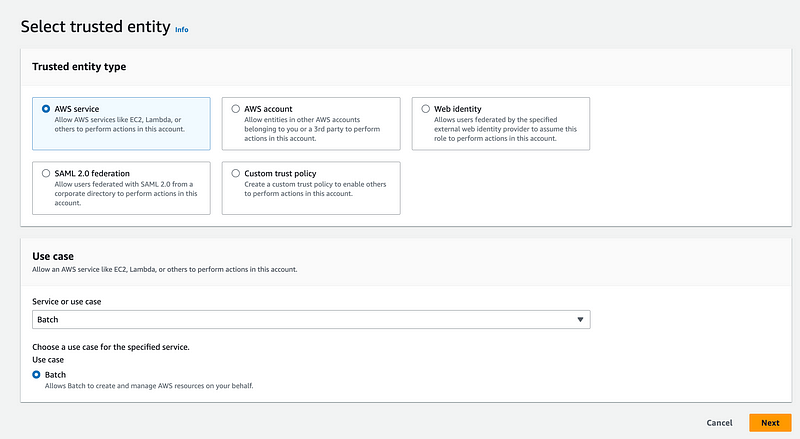
I name the role the name in the error message:
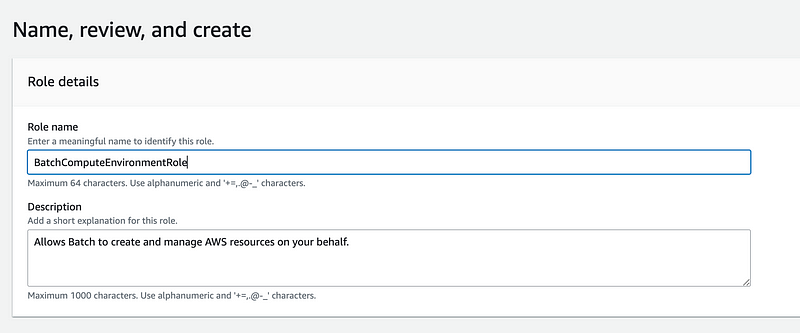
Interestingly enough, it automatically picks up the Batch service policy referenced in the documentation with the ability to create new Service Linked roles and includes the Chinese Endpoint. I’m going to go ahead and let it have that policy for now.
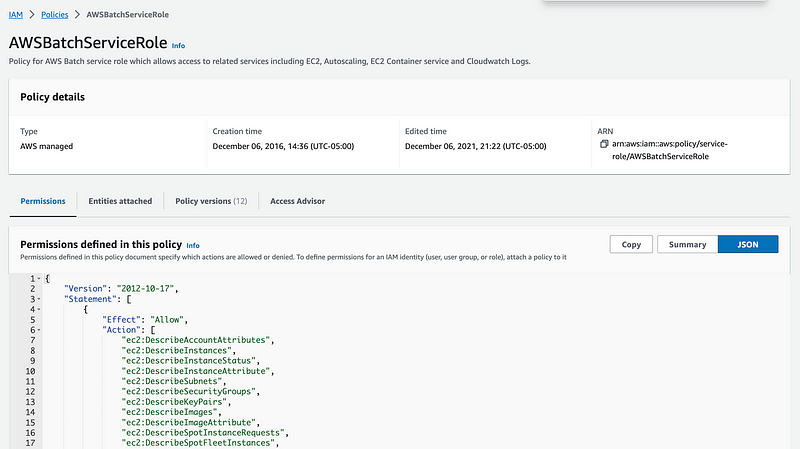
With the default policy I could delete the Compute Environment. Interesting.
OK next I have a Compute Environment associated with a role I created with a custom policy that still exists. To avoid any confusion, I remove the role I just created.
Problem: Can’t delete a role with a custom policy.
Solution: Review and fix the policy, which turns out to be a mismatched resource prefix.
First I have to disable the compute environment. I do that and it gets stuck in update mode for a very long time. Eventually I try to delete the environment again and it says I can’t because there’s an existing job queue. So I head over to the job queue and disable it. Then I came back here to write this paragraph.
I head back over to delete the job queue — and it’s gone. What? Did I delete it? Pretty sure I just disabled it. Anyway, mission accomplished. I get the access denied error again:
Access Denied during delete ECS cluster CloneGithubToCodeCommit_Batch_*** with error User: arn:aws:sts::***:assumed-role/BatchServiceComputeEnvironmentRole/aws-batch is not authorized to perform: ecs:DeleteCluster on resource: arn:aws:ecs:us-east-2:464339214996:cluster/CloneGithubToCodeCommit_Batch_*** because no identity-based policy allows the ecs:DeleteCluster action
OK let’s check the policy I created.
Here’s the problem. The resource in the policy requires a prefix of AWSBatch, however the resource the compute environment is trying to act on has a prefix of CloneGithubToCodeCommit_Batch_.

Now initially I copied that policy from the documentation. What is in the IAM console for the default service policy?
Recall from my last post, that the document references this policy:
BatchServiceRolePolicy
When I look at that policy it does match what I deployed less the things I took out:

So why was I able to just delete a cluster with what I presumed was the default Batch policy?
Search for Batch in the IAM policies list and select AWS Managed.
Notice there are two Batch service policies with very similar names.
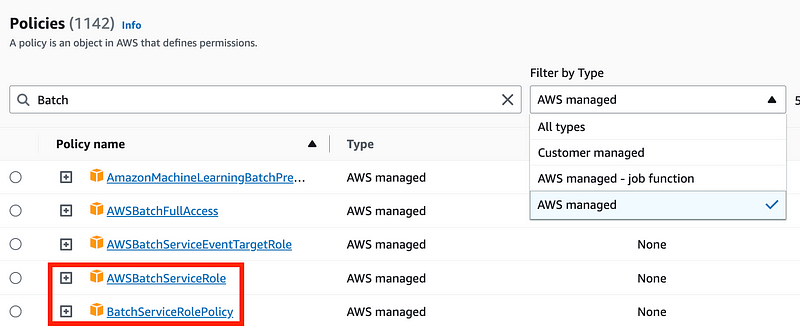
When I created the Batch role above using the AWS console and I selected the AWS service, it automatically assigned the AWSBatchServiceRole, NOT the BatchServiceRolePolicy referenced in the Batch documentation.
Aha.
The AWSBatchServiceRole has permission to delete *ANY* cluster.
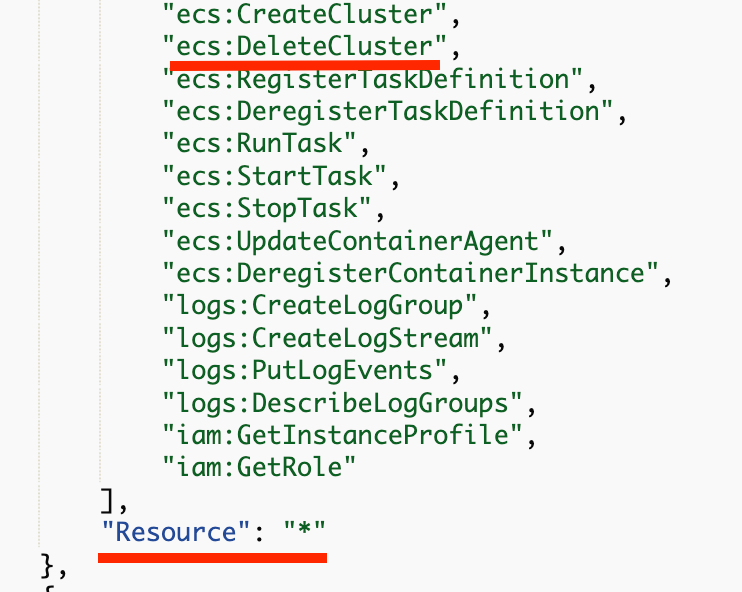
That’s why it worked.
OK. How should I fix my role?
- I could simply remove the prefix.
- I can pass in the Compute Environment name which seems to be the prefix and use it in my policy.
It seems like it would be easy enough to do the latter. Let’s try it.
I create a parameter with a hardcoded default for now:
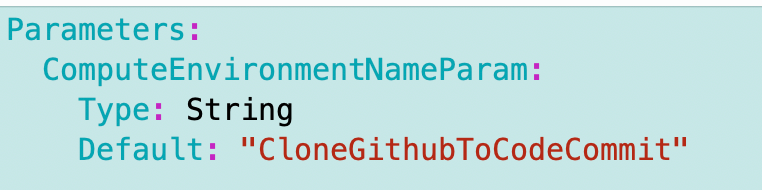
There are a number of places referencing this prefix so I update them all to use the parameter value instead:

Yay! That worked. Now I have to modify the place where I deploy this policy to pass in the compute environment name.
Autoscaling policy error
The other error I noticed was that my Batch Compute Environment got an error saying autoscaling permissions are missing.
BatchServiceComputeEnvironmentRole/aws-batch is not authorized to perform: autoscaling:CreateAutoScalingGroup on resource: arn:aws:autoscaling:xxxxx:xxxxxxxxx:autoScalingGroup:*:autoScalingGroupName/CloneGithubToCodeCommit-xxxxxx because no identity-based policy allows the autoscaling:CreateAutoScalingGroup action
This was the same issue.

It too is fixed by the above resolution.
Test the Batch job again
- Create the compute environment — with the same name in the policy for now. I still am forced to select the Batch ECS role for the EC2 instance, but I choose my own Compute Environment Policy.
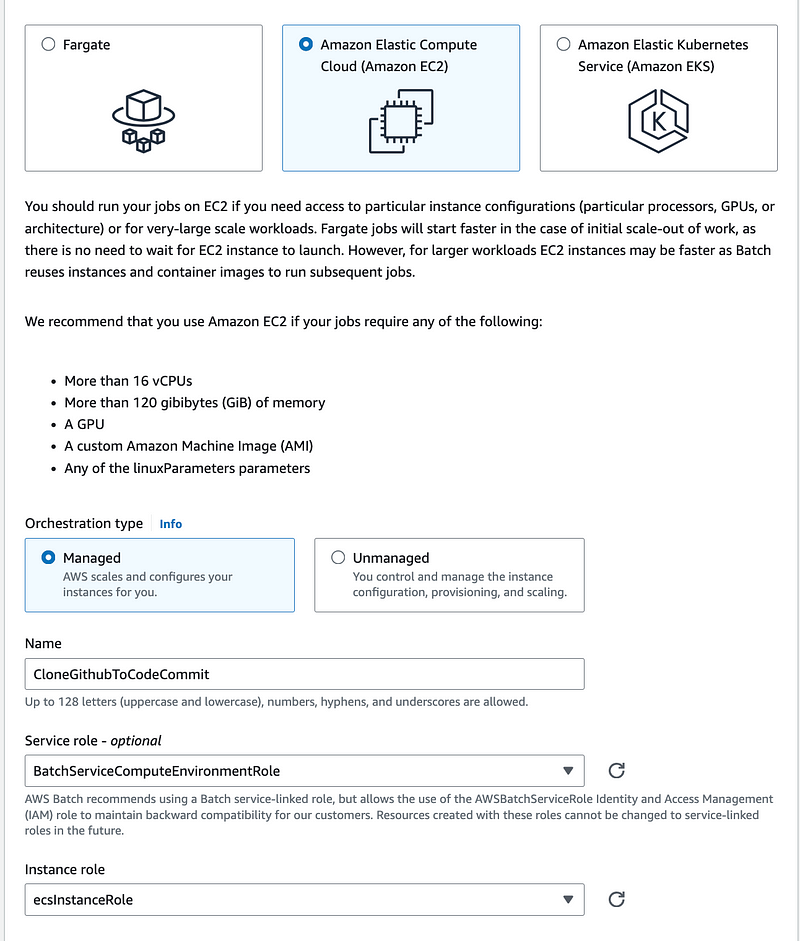
Recall that I’m choosing the lowest priced instance type available per the analysis in a prior post and limiting to 2 vCPUs.
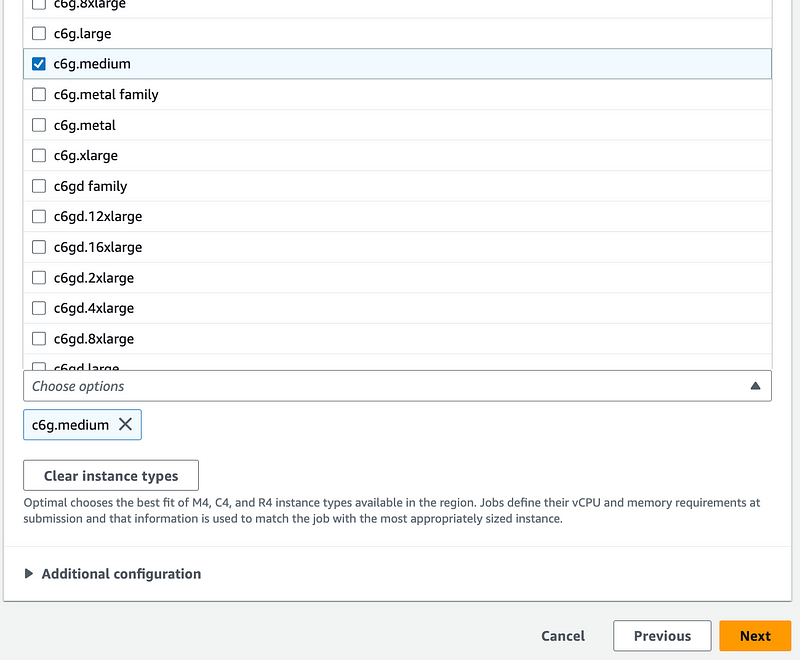
The network configuration is the same as the Lambda function as explained before, less Lambda access.
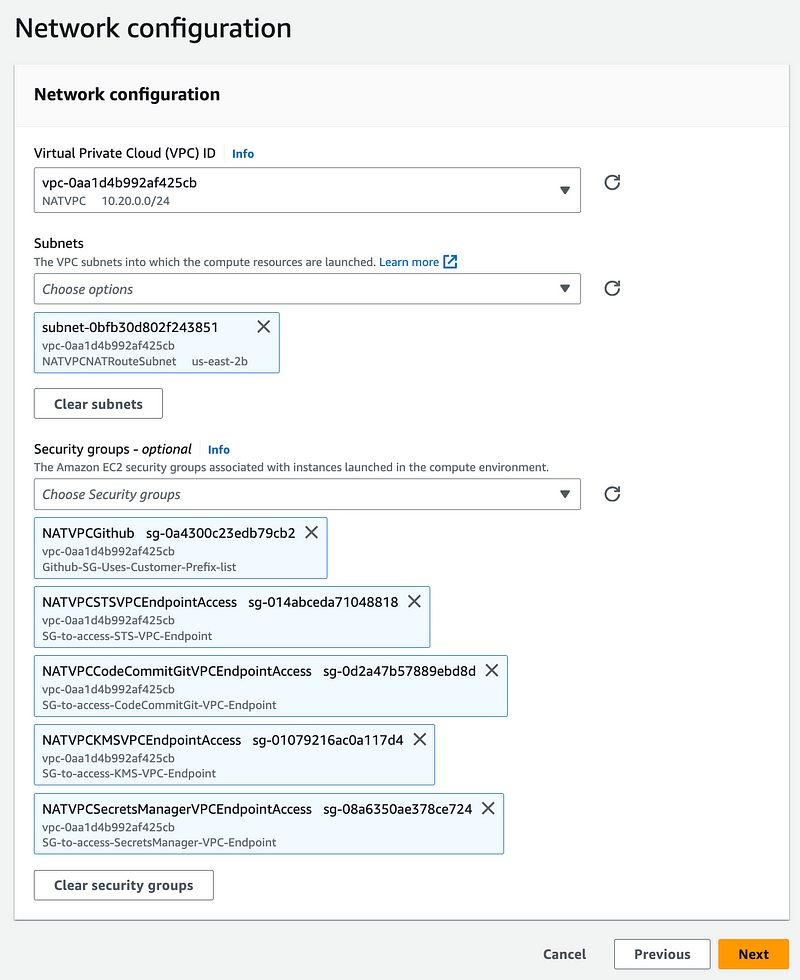
I had inadvertently deleted min vCPUs and got an error about that. Seems like that could default to 0. Anyway that seemed to work.
I check my compute environments list and it’s deploying.
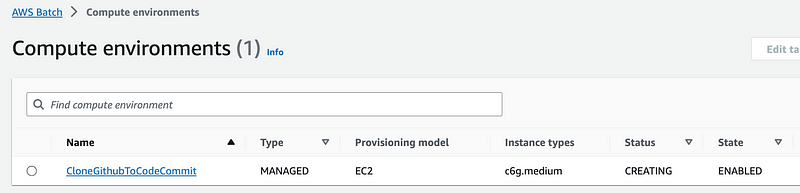
Next I head over to Job Queues. I have to select the Orchestration type again which I suppose limits you to selecting compute environments that match that orchestration type.
I select the Compute Environment, and create the Queue. I forgot to give my queue a name below. I just called it TestQueue.
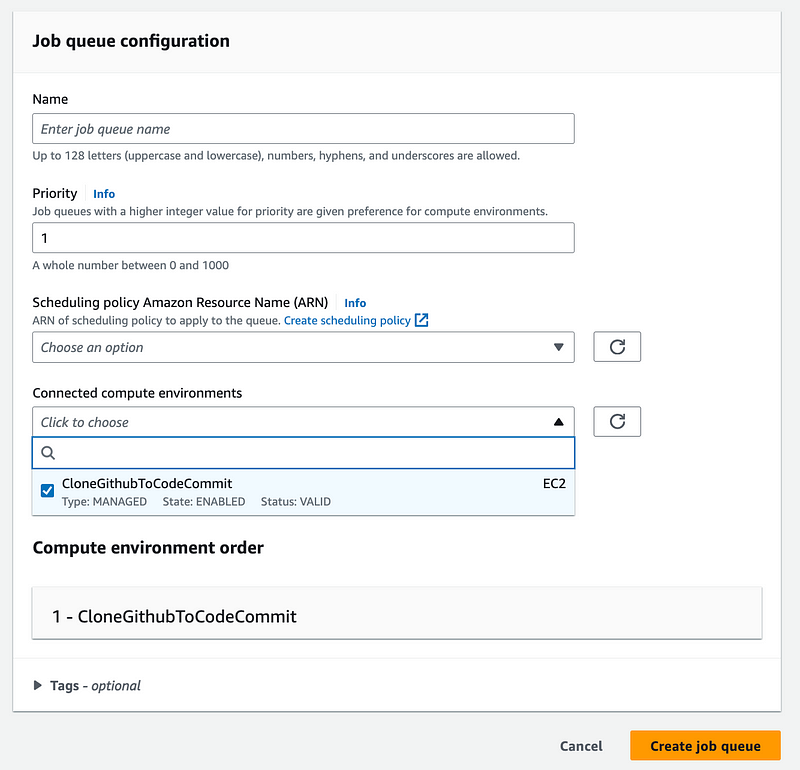
That worked and is creating.
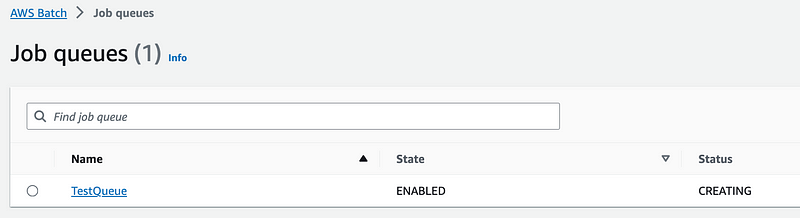
I check my Compute Environment and it is ready:
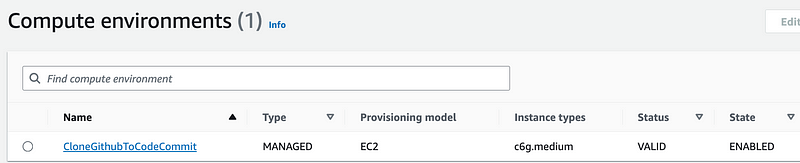
I head over to Job Definitions and I have to create the Orchestration Type again. I feel like that could be streamlined.
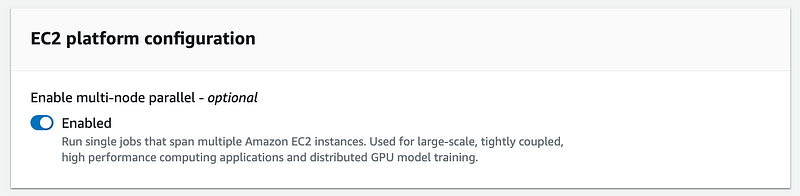
I disable multi-node so I only use one EC2 instance (node) to save money.
I give the job a name and click Next.
Once again I have to select the compute type. Isn’t that picked up from the compute environment? Anyway:
I select my job roles and click next.

Then click Create Job Definition.
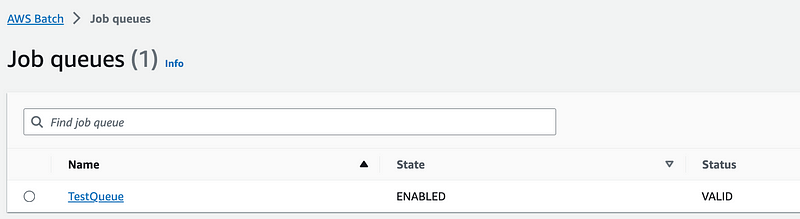
I check my Job Queue and it still shows it in the CREATING state but I click the refresh button and the status turns to VALID.
Back to my Job definition and it is ACTIVE.
But wait a minute. It says MULTINODE. Oh. I turned that on by accident when I meant to turn it off. I went ahead and deregistered this job definition so I could recreate it with that option disabled.
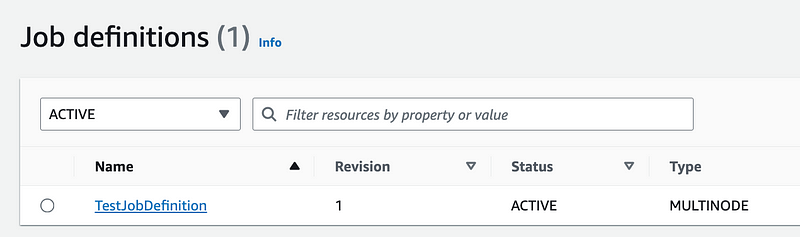
Also, I figured out that when you click the refresh button it shows you all your containers, even when you have Active selected. See below.
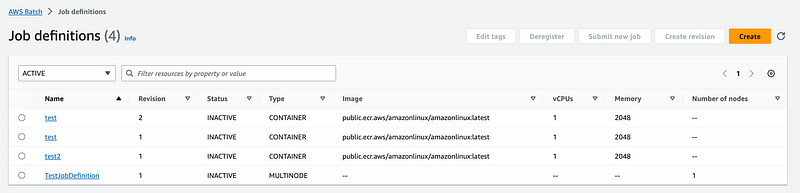
Note that the other Job Definitions I created and subsequently deregistered are Type Container whereas the one I just created is MULTINODE.
I recreated the job definition and turned off multi-node.
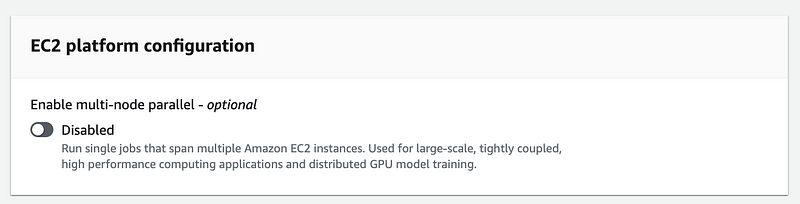
Now I have to set the user name. Do not use dashes, spaces, or special characters here.
I use the rest of the defaults and create the job definition.
I Submit a new job using the button on the right.

Besides setting a name, choosing my job definition and job queue, I use all the defaults.
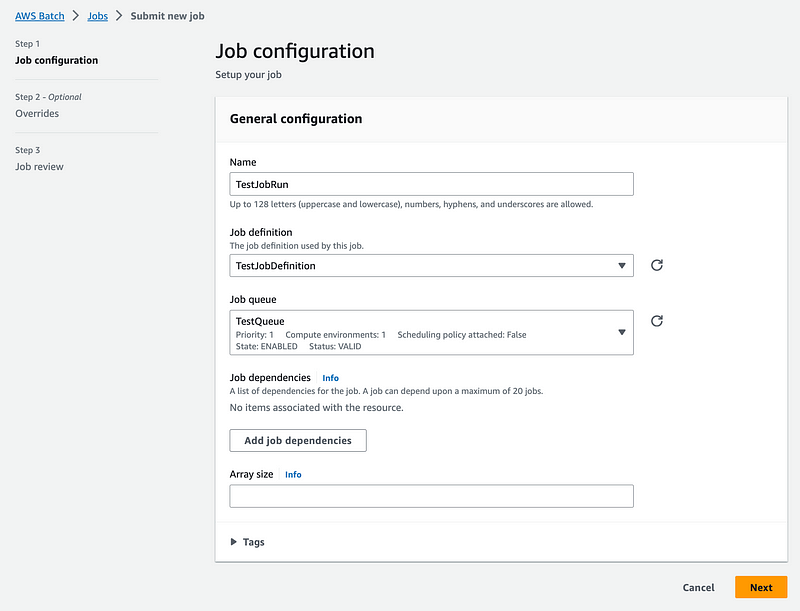
I head over to Jobs and my job failed.

I click on my job. Apparently no logs could be written. Something is wrong with my policy I’m sure.

I head over to my Job Queue. No errors there.
I head over to my Compute Environment. No errors.
I turn on Container Insights.
This information isn’t going to help me at the moment and will cost money so I turn it back off.
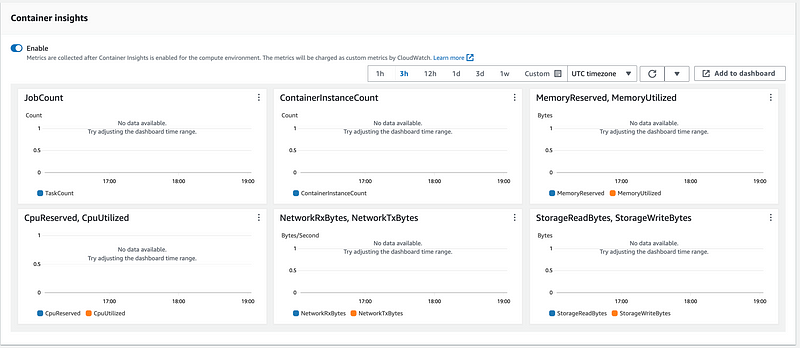
Back to my job. Wait. I missed this error in the fine print. That should be in red. Even though I told you to give the user a valid name, I’m getting an invalid name error. Hmm.
Apparently the user name cannot have uppercase letters in it? Really?
OK.
I head over to the job definition and click the Create Revision button and change the name.
I clone my job and submit it again.
Well that doesn’t work because apparently it cloned the invalid username rather than using the new job definition.
I head back to job definition and submit a new job.
My job is stuck in the Runnable state which is what happened before. I don’t know if it is spinning up a new EC2 instance or what.
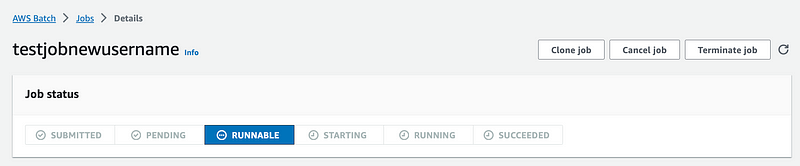
I head over to the Compute Environment Cluster and I see no nodes (EC2 instances.) Hmm.
I don’t see any errors anywhere in the console, just the job sitting in the RUNNABLE state. I wonder if that has to do with limited resources of the instance type I selected or something like that. It would be nice to get some feedback as to what is going on right now.
Let’s check the CloudTrail logs.
Looks like ECS RunTask is having issues:
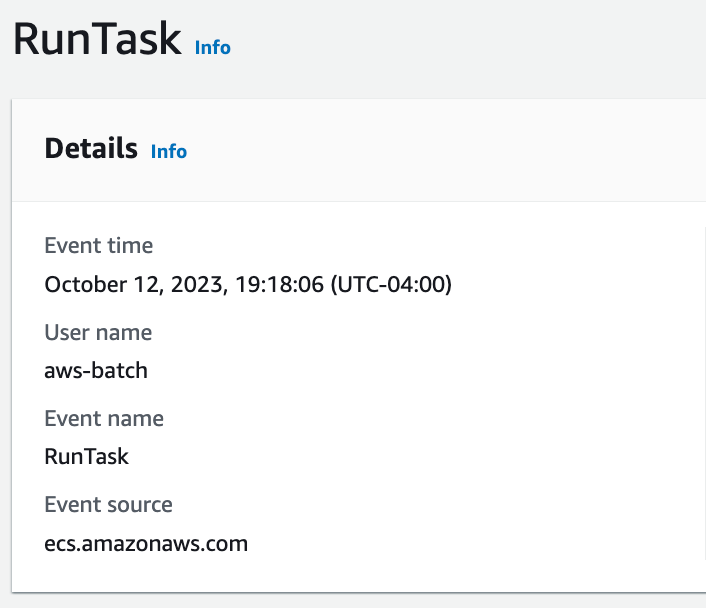

I see 16 instances of this error:
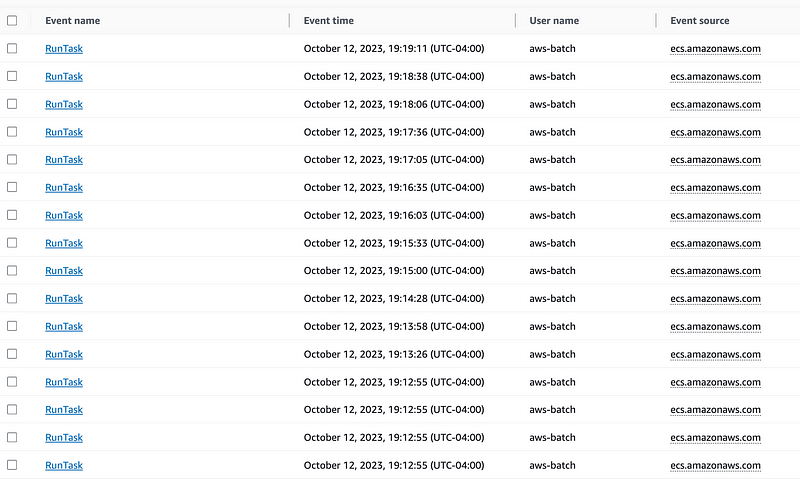
The error prior to that was my username error.
That seems a bit inefficient. Once the first error occurs shouldn’t it stop and report an error? Or if it is waiting for an EC2 instance then it shouldn’t keep logging errors. It should say “Checking for EC2 instance?” Is it checking for the instance type or it’s failing to create it for some reason?
I think it is checking for an instance that doesn’t exist because now there are eve more errors:

Hmm. Well, let me think about all of this for a minute.
That seems to be running eternally because either something is not working, or because my policy doesn’t work. Either way this has been a time-consuming exercise and a lot of configuration for something I expected to be pretty simple.
After waiting for a pretty significant amount of time (far more than I could afford if trying to use an MFA code) I started rethinking my needs and strategy. I really don’t think I need what Batch has to offer to do what I need to do. And if I do need it in the future I could probably create it more easily and cost-effectively with ECS and a queue or something.
In any case, what I need at the moment is much simpler and I already have a working container. I’ll think this through a bit more in the next post and consider alternatives.
Follow for updates.
Teri Radichel | © 2nd Sight Lab 2023
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab





