
TPS-Mar21, Leaderboard %14, XGB, CatBoost, LGBM + Optuna 🚀
Part 2, Xgboost, CatBoost, and Lightgbm with Optuna…

Modeling is one of the most important parts of predictions. You should find the best machine learning model for better results. In part 1, we worked on EDA and feature engineering. You can see this article here.
In this part of the article, we compared three ml models that are Xgboost, Catboost, and LGBM. The competition metric is Area Under the Receiver Operating Characteristic Curve (ROC AUC).
You can see the dataset here and you can see full python code at the end of the article.

Introduction
Firstly we imported the libraries and then calculated the baseline scores of these machine learning models.
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifierfrom sklearn.metrics import roc_auc_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFoldimport optuna
from optuna.visualization import plot_optimization_history
from optuna.visualization import plot_param_importances# XGBClassifier
xgbc_model = XGBClassifier(min_child_weight=0.1, reg_lambda=100, booster='gbtree', objective='binary:logitraw', random_state=42)
xgbc_score = cross_val_score(xgbc_model, train_X, train_y, scoring='roc_auc', cv=5)
print('xgbc_score: ', xgbc_score.mean())
# LGBMClassifier
ligthgbmc_model = LGBMClassifier(boosting_type='gbdt', objective='binary', random_state=42)
ligthgbmc_score = cross_val_score(ligthgbmc_model, train_X, train_y, scoring='roc_auc', cv=5)
print('ligthgbmc_score: ', ligthgbmc_score.mean())
# CatBoostClassifier
cbc_model = CatBoostClassifier(loss_function='Logloss', random_state=42, verbose=False)
cbc_score = cross_val_score(cbc_model, train_X, train_y, scoring='roc_auc', cv=5)
print('cbc_score: ', cbc_score.mean())####################################################################
Outputs:
xgbc_score: 0.8898202612356174
ligthgbmc_score: 0.8879385374274603
cbc_score: 0.8909648517647316Xgboost + Optuna
According to baseline scores, the best model is catboost but it can be changed after hyperparameter tuning. You can see XGB usage with Optuna below.
def objective(trial, data=X, target=y):
X_train, X_val, y_train, y_val = train_test_split(data, target, test_size=0.2, random_state=42)
params = {
'max_depth': trial.suggest_int('max_depth', 3, 32),
'learning_rate': trial.suggest_categorical('learning_rate', [0.005, 0.02, 0.05, 0.08, 0.1]),
'n_estimators': trial.suggest_int('n_estimators', 2000, 8000),
'min_child_weight': trial.suggest_int('min_child_weight', 1, 300),
'gamma': trial.suggest_float('gamma', 0.0001, 1.0, log = True),
'alpha': trial.suggest_float('alpha', 0.0001, 10.0, log = True),
'lambda': trial.suggest_float('lambda', 0.0001, 10.0, log = True),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.1, 0.8),
'subsample': trial.suggest_float('subsample', 0.1, 0.8),
'tree_method': 'gpu_hist',
'booster': 'gbtree',
'random_state': 42,
'use_label_encoder': False,
'eval_metric': 'auc'
}
model = XGBClassifier(**params)
model.fit(X_train, y_train, eval_set = [(X_val,y_val)], early_stopping_rounds = 333, verbose = False)
y_pred = model.predict_proba(X_val)[:,1]
roc_auc = roc_auc_score(y_val, y_pred)
return roc_aucstudy = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=50)
print('Best value: ', study.best_value)####################################################################
Outputs:
Best value: 0.8951492161710065CatBoost + Optuna
def objective(trial, data=X, target=y):
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
params = {
'max_depth': trial.suggest_int('max_depth', 3, 64),
'learning_rate': trial.suggest_categorical('learning_rate', [0.005, 0.02, 0.05, 0.08, 0.1]),
'n_estimators': trial.suggest_int('n_estimators', 2000, 8000),
'max_bin': trial.suggest_int('max_bin', 200, 400),
'min_data_in_leaf': trial.suggest_int('min_data_in_leaf', 1, 300),
'l2_leaf_reg': trial.suggest_float('l2_leaf_reg', 0.0001, 1.0, log = True),
'subsample': trial.suggest_float('subsample', 0.1, 0.8),
'random_seed': 42,
'task_type': 'GPU',
'loss_function': 'Logloss',
'eval_metric': 'AUC',
'bootstrap_type': 'Poisson'
}
model = CatBoostClassifier(**params)
model.fit(X_train, y_train, eval_set = [(X_val,y_val)], early_stopping_rounds = 222, verbose = False)
y_pred = model.predict_proba(X_val)[:,1]
roc_auc = roc_auc_score(y_val, y_pred)
return roc_aucstudy = optuna.create_study(direction = 'maximize')
study.optimize(objective, n_trials = 50)
print('Best value:', study.best_value)####################################################################
Outputs:
Best value: 0.8925910141177894LGBM + Optuna
After hyperparameter optimization, we can see that LGBM is the best model now.
def objective(trial,data=X,target=y):
train_x, test_x, train_y, test_y = train_test_split(data, target, test_size=0.15,random_state=42)
params = {
'reg_alpha': trial.suggest_float('reg_alpha', 0.001, 10.0),
'reg_lambda': trial.suggest_float('reg_lambda', 0.001, 10.0),
'num_leaves': trial.suggest_int('num_leaves', 11, 333),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 100),
'max_depth': trial.suggest_int('max_depth', 5, 64),
'learning_rate': trial.suggest_categorical('learning_rate', [0.01, 0.02, 0.05, 0.005, 0.1]),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.1, 0.5),
'n_estimators': trial.suggest_int('n_estimators', 2000, 8000),
'cat_smooth' : trial.suggest_int('cat_smooth', 10, 100),
'cat_l2': trial.suggest_int('cat_l2', 1, 20),
'min_data_per_group': trial.suggest_int('min_data_per_group', 50, 200),
'cat_feature' : [11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31,
32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52,
53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67],
'n_jobs' : -1,
'random_state': 42,
'boosting_type': 'gbdt',
'metric': 'AUC',
'device': 'gpu'
} model = LGBMClassifier(**params)
model.fit(train_x,train_y,eval_set=[(test_x,test_y)],eval_metric='auc', early_stopping_rounds=300, verbose=False)
preds = model.predict_proba(test_x)[:,1]
auc = roc_auc_score(test_y, preds)
return aucstudy = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=50)####################################################################
Outputs:
Best value: 0.8966645758299353Visualizations
Optimization History
# Historic
plot_optimization_history(study)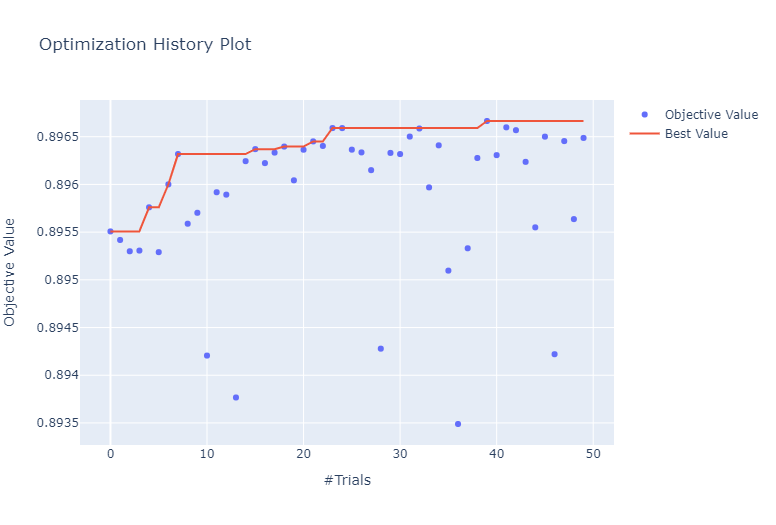
Hyperparameter Importances
# Importance
optuna.visualization.plot_param_importances(study)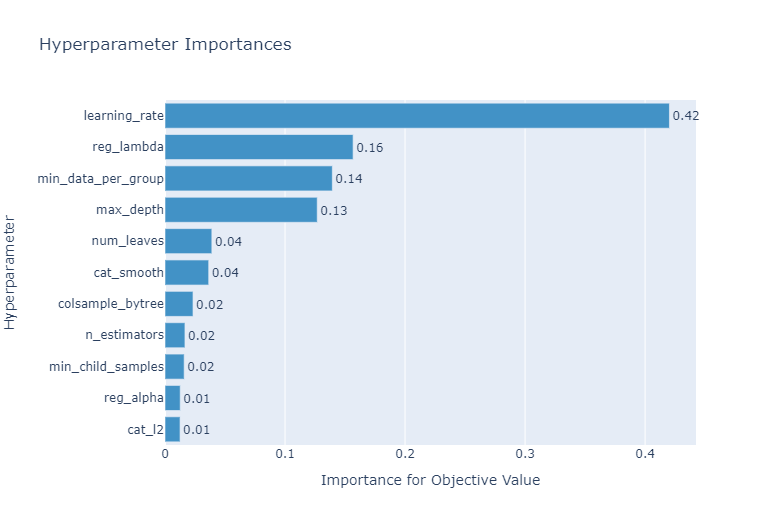
Conclusion
This is part 2 of the TPS-Mar21 competition that I am in LB %14. In this article, we compared famous machine learning boosting models for better prediction. Due to the results, Lightgbm is the best model for this problem.
According to the problem, the best boosting model can change. Also, sometimes speed can be more important than success. You can find more detailed information in this article about when to choose which boosting model.
You can see full python code and all plots from here 👉 Kaggle Notebook.
👋 Thanks for reading. If you enjoy my work, don’t forget to like it 👏, follow me on Medium and LinkedIn. It will motivate me in offering more content to the Medium community! 😊
References:
[1]: https://www.kaggle.com/hasanbasriakcay/xgb-catboost-lgbm-optuna-lb-14/notebook [2]: https://www.kaggle.com/c/tabular-playground-series-mar-2021/data [3]: https://optuna.readthedocs.io/en/stable/reference/study.html [4]: https://xgboost.readthedocs.io/en/stable/ [5]: https://catboost.ai/en/docs/ [6]: https://lightgbm.readthedocs.io/en/latest/ [7]: https://neptune.ai/blog/when-to-choose-catboost-over-xgboost-or-lightgbm



