
Stable Diffusion — ControlNet Clearly Explained!
Generating images from line art, scribble, or pose key points using Stable Diffusion and ControlNet.

ControlNet is a neural network that controls a pretrained image Diffusion model (e.g. Stable Diffusion). Its function is to allow input of a conditioning image, which can then be used to manipulate the image generation.
Table of Contents
├─ What Does ControlNet Do? ├─ Inner Architecture │ ├─ Feedforward │ ├─ Backpropagation ├─ Architecture with Stable Diffusion │ ├─ Encoder │ ├─ Overall Architecture ├─ Training ├─ Conditioning │ ├─ Canny Edge │ ├─ Line Art │ ├─ Scribble │ ├─ Hough Line │ ├─ Semantic Segmentation │ ├─ Depth │ ├─ Normal Map │ ├─ Open Pose ├─ Summary ├─ References
What Does ControlNet Do?
The combination of ControlNet and Stable Diffusion enables Stable Diffusion to take in a condition input that guides the image generation process, resulting in enhanced performance of Stable Diffusion.
It can accept scribbles, edge maps, pose key points, depth maps, segmentation maps, normal maps, etc as the condition input to guide the content of the generated image. Here are a few examples:

Inner Architecture

All the parameters in the Stable Diffusion UNet are locked and cloned into a trainable copy to the ControlNet side. This copy is then trained with an external condition vector.
The reason for creating copies of the original weights rather than training the original weights directly is to prevent overfitting when the dataset is small, and to maintain the high-quality performance of large models that have been trained on billions of images and are ready for deployment in production.
Feedforward

Notations:
- x, y : Deep features in the neural network
- c : An extra condition
- “+” : Feature addition
- Z( · ; · ) : Zero convolution operation (1 x 1 convolution layer with both weight and bias initialized with zeros)
- F( · ; · ) : A neural network block operation (e.g. “resnet” block, “conv-bn-relu” block, etc.)
- Θ_z1 : The parameters of the first zero convolution layer
- Θ_z2 : The parameters of the second zero convolution layer
- Θ_c : The parameters of the trainable copy

During the first training step, since the weight and bias of a zero convolution layer are initialized as zeros, the feed-forward process is identical to the process without ControlNet.
After backpropagation, zero convolution layers in ControlNet become non-zero and affect the output.
In other words, when a ControlNet is applied to some neural network blocks, before any optimization, it will not cause any influence to the deep neural features.
Backpropagation

The backpropagation updates the trainable copy and the zero convolution layers in the ControlNet, enabling the zero convolution weights to gradually transition to optimized values through the learning process.
Why gradient will not be zero?
We might assume that the gradient would be zero if the weights of the convolution layers are zero. However, it is not true.
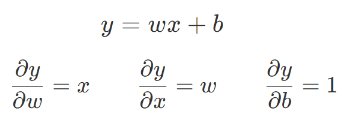
Consider y = wx + b being the zero convolution layer, where w and b are the weight and bias respectively, and x is the input feature map. The above are the gradients for each term.

In the beginning, when the weight value w = 0, the input feature x is typically non-zero. As a result, although the gradient on x becomes zero due to the zero convolution, the gradients of the weight and bias are not affected.
Nonetheless, after one gradient descent step, the weight value w will be updated to a non-zero value (since the partial derivative of y w.r.t. w is non-zero).
Architecture with Stable Diffusion
Encoder
Since the UNet of Stable Diffusion accepts a latent feature (64×64) instead of the original image, we have to also convert the image-based conditions to 64×64 feature space to match the convolution size.
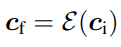
We can use a network ε to encode the input conditions (c_i) into feature maps (c_f).

In the diagram, we use z_t and z_t-1 as the input and output for the locked network block to match the notation in the Stable Diffusion context.
Overall Architecture
The following diagram shows the inputs and outputs of the ControlNet and the UNet in the Stable Diffusion, within one denoising step.

Furthermore, the diagram below illustrates how ControlNet and Stable Diffusion work together in the reverse diffusion process (sampling), in the whole picture.
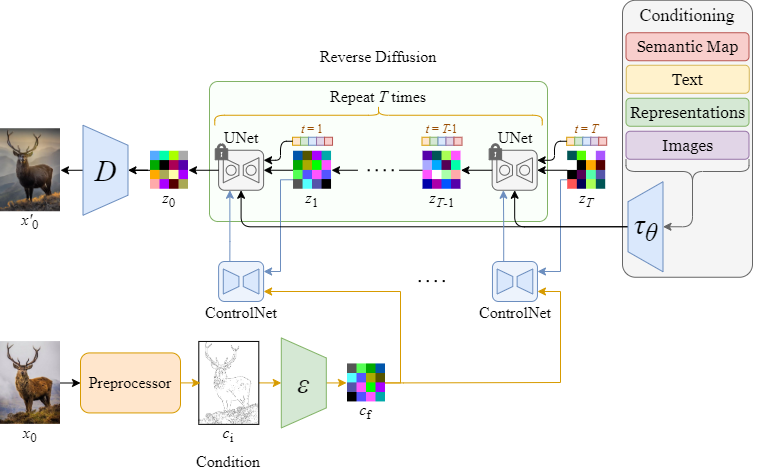
The above diagram has been modified from my previous article on Stable Diffusion. If you have not yet read it, I suggest that you familiarize yourself with the Stable Diffusion architecture explained there first, as it is a comprehensive resource.
Training
The ControlNet loss function is similar to the one of Stable Diffusion, but includes the text condition (c_t) and latent condition (c_f) to improve output consistency with specified conditions.

As part of the training process, we randomly replace 50% of the text prompts (c_t) with empty strings. This helps ControlNet to understand better the meaning of input condition maps such as Canny edge maps or human scribbles.

By removing the prompts, the encoder is forced to rely more on the information in the control maps, which improves its ability to understand their semantic content.
Conditioning
ControlNet is a flexible tool that allows you to utilize Stable Diffusion using different condition input types. The following are some examples of the types of inputs that can be used in ControlNet.
Canny Edge

Line Art

Scribble

Hough Line

Semantic Segmentation

Depth

Normal Map

Open Pose

Summary
ControlNet is a type of neural network that can be used in conjunction with a pretrained Diffusion model, specifically one like Stable Diffusion.
ControlNets allow for the inclusion of conditional inputs, such as edge maps, segmentation maps, and key points, into large diffusion models like Stable Diffusion.
This incorporation of ControlNets provides greater control over the image generation process, resulting in the ability to generate more specific and desired images.
References
[1] L. Zhang and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” arXiv.org, https://arxiv.org/abs/2302.05543.




