
S3 Bucket for S3 Access Logs
ACM.194 Deployment scripts for a generic S3 bucket template
Part of my series on Automating Cybersecurity Metrics. The Code.
Free Content on Jobs in Cybersecurity | Sign up for the Email List
In the last post I explained how a common template to prevent misconfigurations in S3 buckets can help prevent misconfigurations.
Prior to that I provided untested code for a generic S3 bucket template.
In this post we’ll write our deployment script and test the template. Specifically, I’m going to use this generic template to deploy a CloudTrail bucket and a bucket to log access to the CloudTrail bucket. The S3 access bucket will contain all the logs for S3 buckets, with a separate prefix for each bucket’s access logs. The CloudFormation bucket I’ll create in the next post will have the access bucket assigned.
S3 Bucket Policy (pre-testing)
As a reminder the bucket template currently looks like this, prior to testing.
One thing I noticed right away when I came back to this code is that I want to match my naming convention and move Param to the end of the parameters instead of the beginning. That’s something a code review finds but an automated testing tool won’t.

S3 bucket functions
I’m going to add a functions script specific to S3 buckets, same as I did for other resources.
I created a file named s3_functions.sh in the S3 folder.
The S3 specific function calls our shared code in the functions file which you can find here in the GitHub repo:

Include the file with the source keyword.

As a reminder, a shared function deploys CloudFormation stacks with a standard naming convention. I started the topic here but the naming convention evolved throughout the series.
Our naming convention has a prefix that indicates the role profile used to deploy the resource. That prefix is used to limit roles to only updating their own stacks in IAM policies. For most of our resources up to this point we only allowed one role to deploy a particular type of resource.
For S3 buckets, we’ll need to be able to deploy a bucket stack with different prefixes depending on who is deploying the stack. For this reason, we won’t hard code the prefix for s3 buckets, but allow it to be passed in.
Each role can only create stacks matching their own prefix the way I’ve designed the IAM policies, so allowing someone to pass in any prefix should not allow them to escalate privileges to some other prefix. The use of a different prefix should cause AWS to reject the deployment due to the IAM policy that only allows that role to create stacks with a specific prefix. You can take a look and try out the code in the GitHub repo or check out other posts in the series for more on how that works.
Function to get the Key ID based on an alias

Bucket Names
There’s one other thing I want to do at this point. We need to formulate a bucket name that is unique across AWS.
Bucket names must be unique across all AWS accounts in all the AWS Regions within a partition. A partition is a grouping of Regions. AWS currently has three partitions:
aws(Standard Regions),aws-cn(China Regions), andaws-us-gov(AWS GovCloud (US)).
Other bucket naming rules exist here:
It would be nice to have some kind of naming convention for buckets. Once again I will include the profile in the bucket name, indicating who created the bucket. We can also use the profile in policies, when it makes sense. To ensure the bucket is unique, we can look up and include the organization ID in the bucket name if it is an organization-related bucket.
I’m going to use the following names for the tow buckets I’m going to create:
[profile]-[organization id]-s3accesslogs
[profile]-[organization id]-cloudtrail
When we are creating buckets that are not organization related, we can use the account id in the bucket name. The person creating the bucket may not have permission to query the organization ID but presumably they can query the account id. In that case the bucket name will look like this:
[profile]-[accountid]-[descriptive name]
I already create a function to look up the organization id here:

which looks like this:

Now I could source that file to use that function. But this presumes I have access to that source code on the same machine. I have plans to split this codebase up into separate GitHub repos to emulate how this might look n an organization with different roles managing different code bases. Who is going to maintain the S3 bucket code? Which repository will it end up in? I’m not sure so the maintainers of the S3 code will have access to the organizations code. Since we need this function in multiple places now, I’m going to move it to my common functions file.
While I’m there I’m to add a function to get the account ID as well. You can use the following command to get the current account id:
aws sts get-caller-identity
I can extract the account id and pass it back the same way I extracted the organization ID.
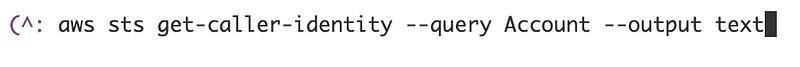
So my function looks like this:

I can test it from the folder where the shared_functions.sh file exists like this. First navigate to the shared functions file. Source it so you can call functions in it from the command line. Then execute the function (get_account_id) we just added.

That works. The account ID is returned.
Back to my s3_functions file. I’m going to alter my function that creates a bucket. First I’m going to pass in a bucket name suffix instead of the full bucket name. I want to make that clear so I’ll alter the parameter name accordingly.

Next I’ll get the appropriate id, with a caveat in the comments. I would not put the account id or organization ID in a public bucket name.

Even though AWS says they are not supposed to be secret I’ll just leave this here:
I can think of other ways to use these values as well.
Next I will formulate the bucket name according to our naming convention.

I also added some code to make sure the bucket name is all lower case:

All that for a bucket name! By now you may see why I’ve been avoiding S3 buckets up to this point. And I haven’t even gotten to the bucket policy.
Function to deploy an S3 bucket
Here’s the full function to deploy an S3 bucket:

The above should look familiar from prior posts, with the following S3-specific revisions:
- I’m checking to see a profile is passed in.
- I’m checking to see if a key alias is passed in.
- I’m looking up the key id.
- I’m generating the bucket name
- The log bucket is optional, but if it is set, a prefix is required. (May change this later, stay tuned).
Deployment script file and location
Next we need a deployment script that deploys the buckets. The deployment script lives in the directory owned by whomever is deploying the bucket. For the CloudFormation resources in the root account (temporarily), the OrgRoot user will own those resources, so the deployment script will exist in the Org directory.
I’m going to add an S3 folder under Org/S3/stacks.
cd ~/SecurityMetricsAutomation/Org/stacks
mkdir S3
cd S3
vi deploy.sh
[add code to the deploy.sh file]The first bucket I want to deploy is the bucket that will contain the S3 Access logs for all other buckets. This bucket will not have the access log bucket parameter set, obviously, because there are not existing buckets to pass in. That would a circular dependency.
Run the deployment script in the Organizations/stacks/S3 folder.
./deploy.sh
I’m deploying this in the root account for now to get it done but as mentioned I have plans to move it later when we flesh out our organization.
Validate the deployment
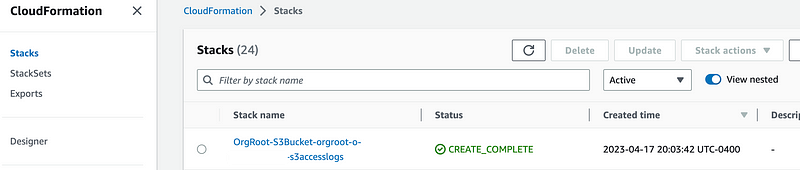
Check that the bucket template was successfully deployed on the CloudFormation dashboard:
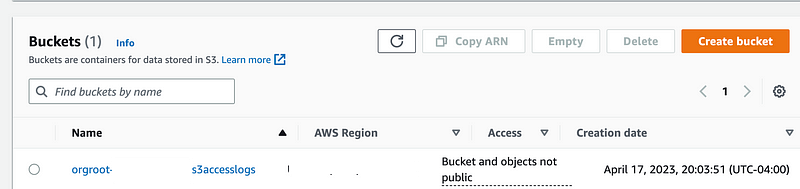
Take a look at your bucket and configuration by navigating to the S3 dashboard and clicking on the bucket.
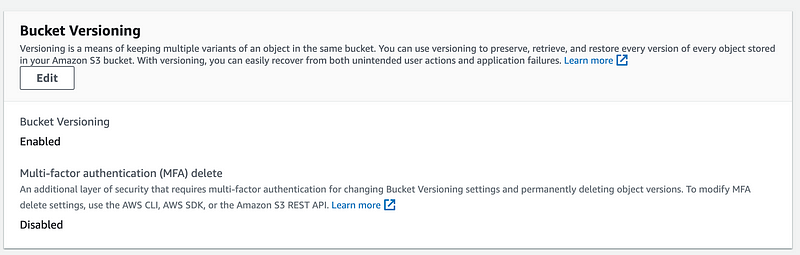
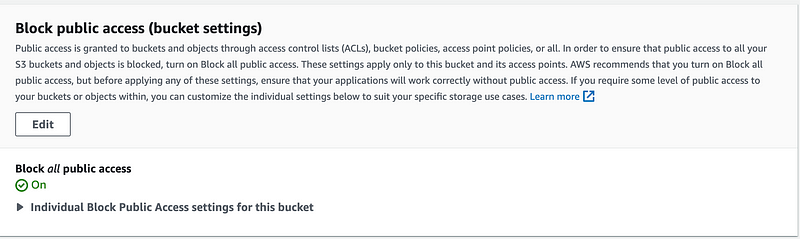
Validate the bucket settings to ensure they got deployed correctly. If you want to adjust any of the settings, make them in the scripts and template and redeploy the bucket. Don’t click buttons!
I am not going to go add screen shots of every property here but as you can see Bucket Versioning is enabled for the bucket as well as Block Public Access.
Many typos and bug fixes later, here is my final AWS S3 Bucket template which you can find in the associated GitHub repo (shortly):

Well, we have an access log bucket for all our other S3 buckets in the organizational root account. Now we need to deploy our CloudTrail bucket that uses the access log bucket. I’ll do that in the next post. I also still need to update bucket policies and our KMS key policy.
Follow for updates.
Teri Radichel | © 2nd Sight Lab 2023
About Teri Radichel:
~~~~~~~~~~~~~~~~~~~~
⭐️ Author: Cybersecurity Books
⭐️ Presentations: Presentations by Teri Radichel
⭐️ Recognition: SANS Award, AWS Security Hero, IANS Faculty
⭐️ Certifications: SANS ~ GSE 240
⭐️ Education: BA Business, Master of Software Engineering, Master of Infosec
⭐️ Company: Penetration Tests, Assessments, Phone Consulting ~ 2nd Sight LabNeed Help With Cybersecurity, Cloud, or Application Security?
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
🔒 Request a penetration test or security assessment
🔒 Schedule a consulting call
🔒 Cybersecurity Speaker for PresentationFollow for more stories like this:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
❤️ Sign Up my Medium Email List
❤️ Twitter: @teriradichel
❤️ LinkedIn: https://www.linkedin.com/in/teriradichel
❤️ Mastodon: @teriradichel@infosec.exchange
❤️ Facebook: 2nd Sight Lab
❤️ YouTube: @2ndsightlab