
Machine Learning Art
Remove noise from audio files
using Deep Learning — DEMO + CODE
Many systems, such as automated voice recognition, video chat systems, and assistive listening devices, use monaural speech augmentation. Most state-of-the-art techniques use a deep neural network to estimate a TF mask in the short-time Fourier transform (STFT) representation, with many of these masks being real-valued or complex. The predicted covers are generally well-defined and constrained by an upper bound to increase network training stability. However, both systems suffer if the frequency resolution is too low for reducing noise between voice harmonics. The methods described above need at least 20 ms windows to achieve a minimum frequency of 50 Hz.
The authors offer DeepFilterNet, a two-stage speech improvement system based on deep filtering, in this paper. First, they use ERB-scaled gains to improve the spectral envelope by simulating human frequency perception. Deep filtering is used in the second step to improve the periodic components of speech. They build a low-complexity architecture by enforcing network sparsity using separable convolutions and substantial grouping in linear and recurrent layers, in addition to taking use of perceptual features of speech.
This framework supports Linux, MacOS and Windows.
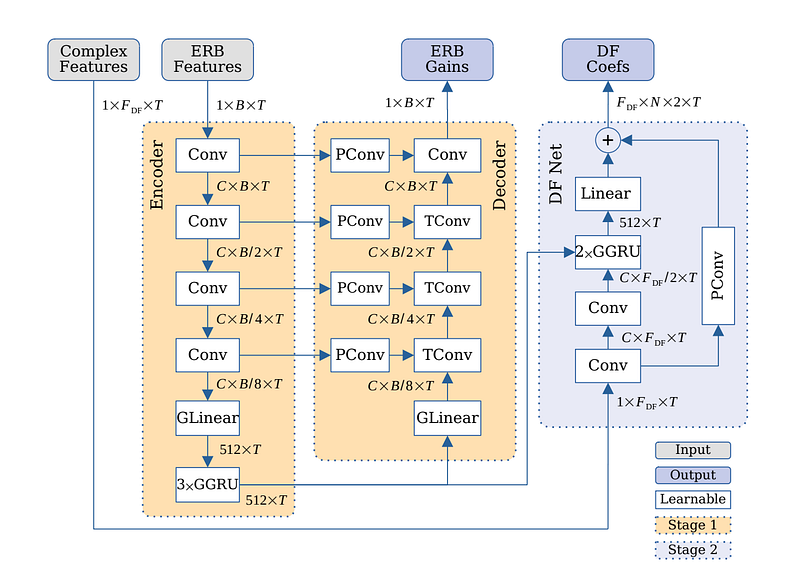
The Deep Filter Net architecture is shown in this below diagram. As add-skip connections, the authors employ 1x1 pathway convolutions (PConv) and transposed convolutional blocks (TConv), which are equivalent to encoder blocks. To introduce sparsity, GRU (GLinear, GGRU) layers and grouped linear layers are utilized.
Conclusion
DeepFilterNet, a low-complexity speech improvement system, was suggested by the authors. They demonstrated that DeepFilterNet outperforms other techniques while being more computationally efficient. This is accomplished by the use of a perceptually justified strategy that reduces model complexity. Furthermore, they demonstrated that DF outperforms CRMs, especially for lower STFT window widths. State-of-the-Art in removing noise from audio files
@inproceedings{schroeter2022deepfilternet,
title={DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering},
author={Hendrik Schröter and Alberto N. Escalante-B. and Tobias Rosenkranz and Andreas Maier},
booktitle={ICASSP 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
year={2022},
organization={IEEE}
}
Project Page:
https://arxiv.org/pdf/2110.05588.pdf
Github:
DEMO:
Keywords: Audio and Speech Processing; Machine Learning ; Signal Processing , deep learning, audio
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
- Check out my instagram with new material every week
- If you enjoyed this, follow me on Medium for more
- Want to collaborate? Let’s connect on LinkedIn
- https://linktr.ee/datasculptor
- 3D Machine Learning generated model on sketchfab
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai