
OpenAI’s SORA: Latest Text2Video Breakthrough
In the last few years, we made great strides in text2image models. The images became so good that it became almost impossible to differentiate between the generated and the real images. But what about videos? Truth be told, videos are hard to crack because it is not just about producing a correct image given a prompt, but it’s more about how we make it consistent temporally. How do we make sure that the generated videos follow the rules of Physics and this is precisely the reason why text2video is hard. In today’s blog, we are going to take a deep dive into OpenAI’s SORA. SORA is the latest text2video model showcasing incredible capacity to generate videos with simple text prompts.
Topics Covered
- What is a Diffusion Model?
- U-Net in Diffusion Models
- Latent Diffusion Model
- Diffusion Transformer
- SORA Architecture Overview

What is a Diffusion Model?
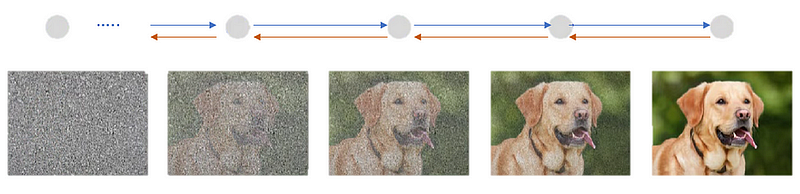
A Diffusion model is basically a generative model that takes an input image and gradually increases the noise added to the input image at each given timestamp. The model adds noise till it starts looking like a completely random noise.

After the image is converted into a random noise image, we try to convert it back iteratively to its original state. In doing so, the network learns how to generate images from noise. It has been shown that the diffusion model has beaten GANs in image generation. To denoise the image a model like U-Net is used by passing each noisy frame iteratively till the final high-resolution image is obtained.
For more detail read the given below blog, where we discussed this in detail.
U-Net in Diffusion Model
U-Net is a convolutional neural network architecture that is commonly used in diffusion models. It is a U-shaped architecture that consists of an encoder and a decoder. The encoder part of the U-Net contracts the input image, capturing its high-level features. The decoder part then expands the features back to the original image size, reconstructing the image.
In diffusion models, the U-Net is used to predict the noise that needs to be removed from the image at each step of the diffusion process. The model takes the noisy image and the current diffusion step as input, and it outputs the noise that should be removed to get the image from the previous step.
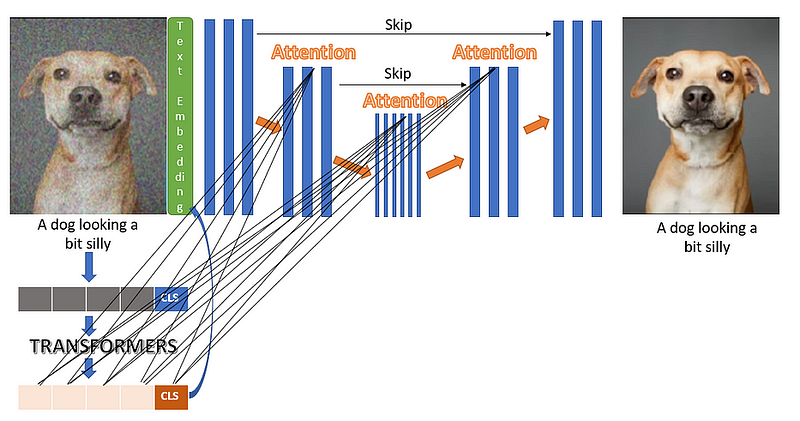
- Input Image with Noise: A noisy image is inputted to the model. This noise isn’t random but is typically sampled from a known noise distribution that the model is trained to reverse.
- Text Embedding: Along with the noisy image, a text embedding is created. This text embedding is derived from the textual description (“A dog looking a bit silly” in this case), which is intended to guide the image generation process. The embedding is produced by a Transformer model, which has been trained to understand and encode the meaning of the text.
- Class Token: The text embedding is appended with a special ‘class’ token (often denoted as [CLS] in Transformer architectures), which aggregates information from the embedding and serves as a high-level representation of the input text.
- U-Net with Attention: The actual image generation is carried out by a U-Net architecture enhanced with attention mechanisms. U-Net is a type of convolutional network designed for tasks that require understanding the content and context of an input, such as image segmentation. The attention mechanism allows the model to focus on different parts of the text embedding as it generates the image, effectively considering different aspects of the description at different stages of the generation process.
5. Interactions between Transformers and U-Net: The architecture leverages two levels of interaction between the text and the image:
- The overall class token is used to condition the generation process, essentially telling the model what type of image to generate.
- Individual tokens from the text embedding are fed into each attention layer of the U-Net. This allows every step of the generation to be influenced by different pieces of the text, making the process more granular and context-aware.
6. Output Image: The result of this iterative denoising process is a clear image that corresponds to the input text. The architecture aims to retain the essence of the textual description while also reducing the noise from the initial image.
Latent Diffusion Model
A latent diffusion model is a type of generative model that learns to create data that is similar to the data it was trained on. It does so by learning a representation of the data in a latent space, which is a compressed form that captures the essence of the data in fewer dimensions. By working in a latent space, they can be more efficient in terms of computation and memory usage than models that operate directly in the data space. They can also be applied to various types of data beyond images, such as audio, text, and even molecular structures.
Here are the key steps in the process:
Training Phase:
- The model first encodes data into a lower-dimensional latent space using an encoder (often a neural network like a variational autoencoder).
- It then adds Gaussian noise in a series of steps to the encoded data, effectively ‘destroying’ the original information progressively until only noise remains.
- A neural network, usually a U-Net architecture with attention mechanisms, learns to reverse this process: given a noisy latent representation, it predicts the noise that was added at each step and subtracts it to recover the data’s latent representation from one timestep before.
Sampling Phase:
- To generate new data, the model starts with noise and uses the learned denoising process to iteratively refine this noise into a coherent data sample in the latent space.
- Once a clear latent representation is obtained, a decoder network maps it back to the data space, producing a new data sample.
Diffusion Transformer
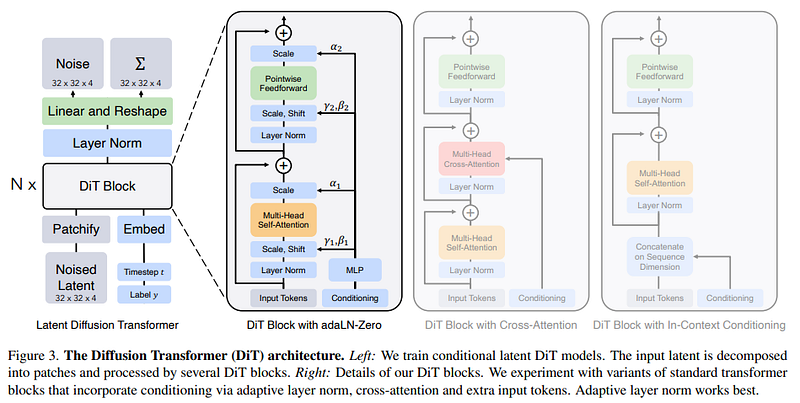
- Noise Input: A noise vector of a specific dimension (32 x 32 x 4) is input to the system. This represents the latent space where the diffusion process operates.
- Linear and Reshape: The noise vector is passed through a linear layer to transform its dimensionality and then reshaped as necessary for further processing.
- Layer Norm: After reshaping, a layer normalization step is applied, which is a technique to normalize the inputs across the features.
- DiT Block: This is where the core processing happens. The architecture uses multiple DiT blocks in a sequence. Each DiT block has several components:
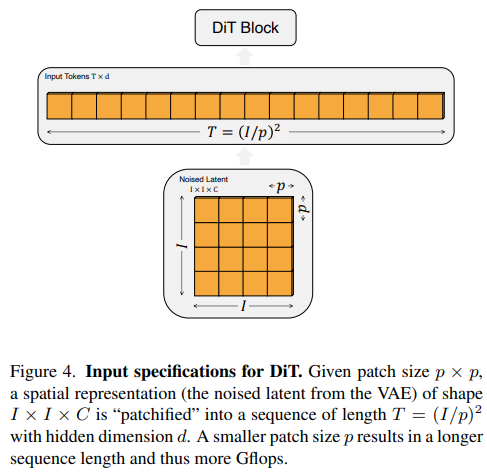
- Patchify and Embed: The input latent is broken down into patches and embedded with positional information.
- Noise Latent: The latent, now with added noise and a time step indicating the stage of the diffusion process, plus any labels for conditioning, is further processed.
- Multi-Head Self-Attention: This component allows the model to focus on different parts of the input sequence, important for capturing complex dependencies.
- Multi-Head Cross-Attention: It allows the model to attend across different sequences of data. This might be where conditioning on extra information (like class labels) occurs.
- Feedforward Neural Network: A typical component of transformer blocks that processes the data sequentially.
- Layer Norm and Scale-Shift: These are normalization and affine transformation steps that help stabilize the learning process.
DiT Block Variants:
- With adaLN-Zero: A variant with adaptive layer norm, likely to allow better conditioning on the noise levels or labels.
- With Cross-Attention: A variant where cross-attention is used, perhaps to incorporate conditioning from another modality or data source.
- With In-Context Conditioning: This block concatenates conditioning information directly with the sequence, which can help in guiding the diffusion process more directly.
Output: After processing through the transformer blocks, the model outputs the processed latent vectors that can be used to reconstruct the denoised image or generate new samples.
SORA Architecture Overview
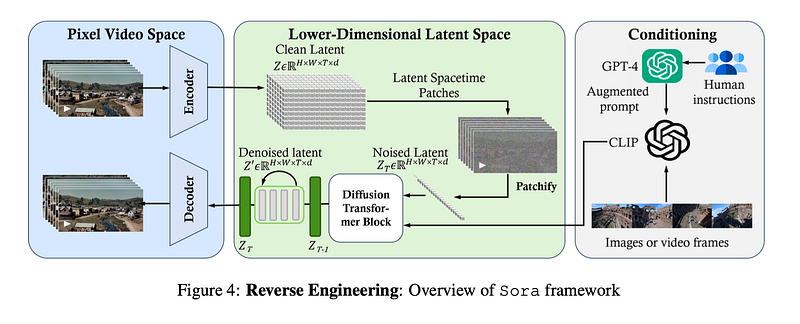
The architecture shown in the above image is what we think SORA might look like, since the official paper is not released, we are not very sure. We are gathering all the details from the technical report and can say that it is a generative framework designed to transform and manipulate video or image sequences within a latent space. Here’s a breakdown of how the overall architecture might operate:
1. Pixel Video Space: This is where the raw input data resides. It could be a sequence of images or video frames that exist in a high-dimensional space (each pixel is a dimension).
2. Encoder: The input data is passed through an encoder, which compresses the high-dimensional pixel data into a lower-dimensional latent space. This latent representation captures the essential information from the original data while reducing its complexity.
3. Lower-Dimensional Latent Space: The architecture processes data within this space, which includes several key steps: — Clean Latent ( Z ): This is the initial, noise-free latent representation of the input data. — Latent Spacetime Patches: The latent representation is divided into patches that incorporate both spatial and temporal information, essential for capturing the dynamics of video data. — Patchify: This process involves breaking down the latent space into smaller, more manageable segments or “patches” for processing. — Noised Latent ( Z_t ): Noise is added to the latent representation to create a noised version, which is a standard step in diffusion models. The added noise typically increases over a number of timesteps until the signal is completely noisy. — Diffusion Transformer Block: These blocks iteratively work to denoise or ‘reverse engineer’ the latent representation back to its clean state. The blocks progressively remove noise from the latent representation over a series of timesteps, effectively learning to reverse the diffusion process.
4. Conditioning: The architecture uses various conditioning methods to guide the denoising process, including: — GPT-4 Augmented Prompt: Prompts generated or augmented by GPT-4 can provide context, instructions, or goals for the generation process. — Human Instructions: Direct human input can be used to guide the denoising process according to specific requirements or objectives. — CLIP: The CLIP model can be used to align the denoised outputs with textual descriptions, ensuring that the generated images or video frames are semantically coherent with the provided instructions or prompts.
5. Decoder: After the denoising process in the latent space, the clean latent representation is passed through a decoder. The decoder reconstructs the data back into the original high-dimensional pixel space, resulting in the generation of denoised images or video frames that reflect the conditioning inputs.
That’s it for today, I hope you enjoyed reading the article.
Writing such articles is very time-consuming; show some love and respect by clapping and sharing the article. Happy learning ❤
Please don’t forget to subscribe to AIGuys Digest Newsletter
References
[1] https://openai.com/research/video-generation-models-as-world-simulators



