
Google’s Imagen vs OpenAI’s DALLE-2
Text to image generation models is the new fad in the market of AI. The latest model in this race is Google’s Imagen model. An answer to OPENAI’s DALLE-2 model. DALLE-2 made some great progress over DALLE-1 but in reality, it was not a successor of DALLE-1 but of GLIDE (another paper from OpenAI). DALLE-1 was trained with the help of GPT-3 whereas DALLE-2 used the technique of the diffusion model. Both DALLE-2 and Google’s Imagen use the Diffusion model with slight differences. Both models are extremely good at generating images from text prompts. But comparing their actual performance is a little tough thing to do as none of these are open-sourced yet.

So, without further ado let’s get into the nitty-gritty of the Imagen and see how it is different from OpenAI’s DALLE-2.
Let’s first see what are the Diffusion models.
Diffusion Model

A Diffusion model is basically a generative model that takes an input image and gradually increases the noise added to the input image at each given timestamp. The model adds noise till it starts looking like a complete random noise.
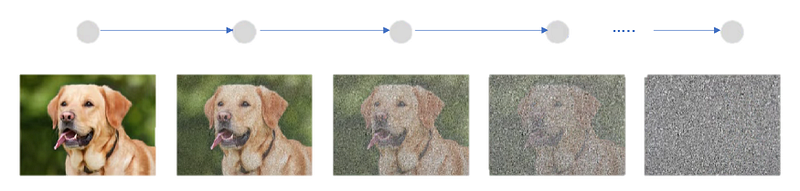
After the image is converted into a random noise image, we try to convert it back iteratively to its original state. In doing so, the network learns how to generate images from noise. It has been shown that the diffusion model has beaten GANs in image generation. To denoise the Image a model like U-Net is used by passing each noisy frame iteratively till the final high-resolution image is obtained.
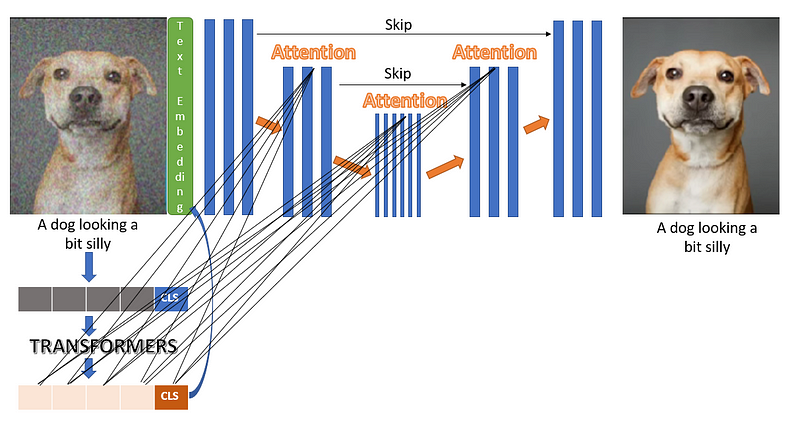
The above figure shows what the back diffusion model looks like. We see that the noisy image is used as input which generates a noise-free image as output. The noisy image also has class guidance through text embedding added to the input image. For the text embedding, DALLE-2 trains a transformer from scratch and uses the final token embedding as a class-conditioning in the diffusion model. We also see that the model used here is not just a simple U-Net but rather it’s U-Net with attention.
The idea behind such architecture is to generate images with less and less noise while having guidance from text embedding. But authors of DALLE-2 found out that adding the final class token to the input was not enough, that’s why each token generated from the transformer is being attended by each attention layer in the U-Net.
We see in the above architecture that there are two sets of connections between the transformer and U-Net. Firstly, the final class token is directly attached to the noisy input image. Secondly, all the text tokens are attached to every attention layer within U-Net.
On the other hand, Google Imagen uses a slightly different technique. Instead of training the transformers from scratch for the text-image pairs, it uses an off-the-shelf huge transformer model to generate text embedding. The transformer model used by Google’s Imagen is called T5-XXL. By doing this Imagen also reduced the size or number of layers required in the U-Net model. Google uses the frozen model while training the back diffusion U-Net.
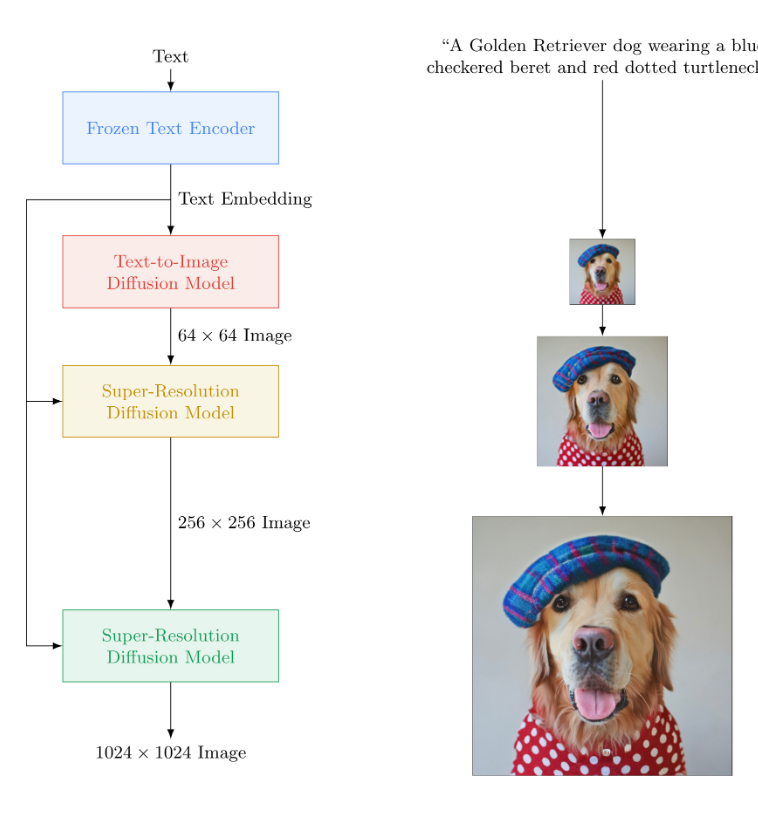
Both Google Imagen and DALLE-2 do not generate high-resolution images rather both use another model to upscale the images. The image generated by the back-diffusion model is of size64x64which is finally upscaled to the resolution of 1024x1024 the 4 times super-resolution model twice.
Classifier Free Guidance
Another crazy idea that was introduced in the DALLE-2’s predecessor (GLIDE) was classifier-free guidance. This further enhances the impact of the text while generating the image. In the classifier free guidance once the output is generated without any text and once with the text. Then we extrapolate the image in the direction of the with-text image to generate the high-quality samples. This is a weird hack but it works for both DALLE-2 and Imagen.

Imagen introduced a minor change in the classifier free guidance approach i.e., they included dynamic thresholding in the extrapolating to make sure that the extrapolated image doesn’t become too unfaithful to the actual result. In other words, the image extrapolated towards the text direction doesn’t generate pixels that are out of range meaning that the pixels are not too far such that they start behaving like noise. Applying dynamic thresholding reportedly led to better photorealism and better text alignment.
Imagen claims two major advantages over DALLE-2:
- Better photorealism
- Better images with text in them

At first glance, it looks like Imagen is outperforming DALLE-2 but more thorough testing of both the methods is still required. Preliminary tests do show that Imagen has a better understanding of understanding text because of its larger transformer model. The transformer used in Google’s Image is trained on around 960 million images, which is twice more than what DALLE-2 used.
Fail cases
In the below image both the model gets completely opposite of what is asked of them.

Another thing to note here is that Google’s Imagen doesn’t show to generate any human face, this might be due to privacy and racial bias present in the system, but it is tough to know without actually testing it fully.
That’s it for today. Hope to see you soon.
Original Paper: link
Thanks for giving your time and if you think that this blog added something to your knowledge base, please consider following the AIGuys Blog, and if you are interested to become a writer at AIGuys you can follow this link.




