
OpenAI’s DALL-E 2 explained
We all know that DALL-E 2 is one of the craziest models we have seen this year. DALL-E 2 is a text-to-image generation model developed by Open-AI researchers. It’s the second installment in the series of text-to-image generation models. DALL-E 2 is an extremely capable model with the ability to draw a large variety of images with never before seen text prompts. DALL-E 2 can create images that don’t exist on the internet, it’s more like an actual painter who can paint anything with his/her imagination. So, without any further ado, let’s dive straight into the details of how DALL-E 2 works.

Before we go into the workings of DALL-E 2, let’s have a look at some awesome results from the model.
You can check all the results here: DALL-E 2

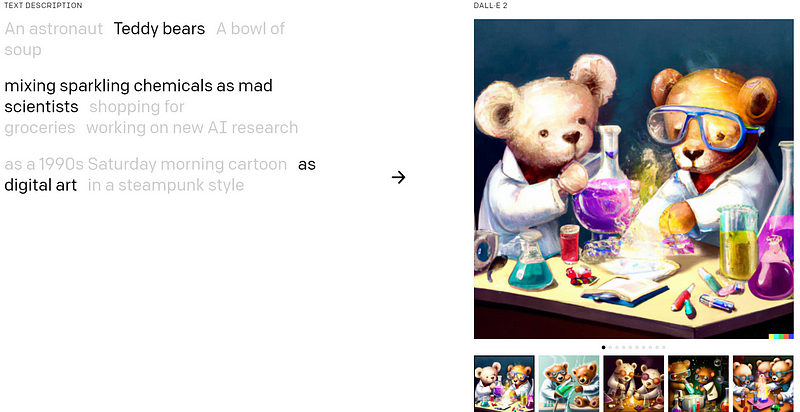
DALL-E 2 can understand images and text in great detail thus it can not only create images out of the text but also create other versions of famous paintings, understand different art styles, and also understand the lighting conditions and create shadows accordingly. It can also be used for inpainting and have the capability to generate image for almost any random text prompt.
The Architecture
DALL-E 2 has two main components in its architecture namely Prior and Decoder. First, we convert the text prompt into a text embedding, that is fed to the Prior to convert the text embedding into a representation of the image called Image Embedding. Next, the image embedding is passed through a decoder to convert the image embedding into the actual image.
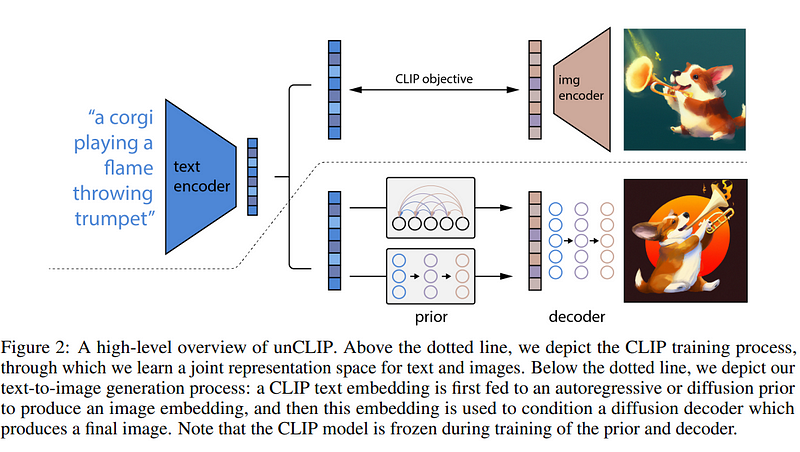

One may ask now, how are we generating these text and image embeddings? These text and image embeddings are generated via another technique developed by OpenAI called CLIP. CLIP is a neural network model that returns the best caption given an image. It is basically doing the opposite of what we are trying to achieve through DALL-E 2. CLIP is a contrastive learning model which means that it doesn’t classify the images but rather tries to match the images to their corresponding text prompt.
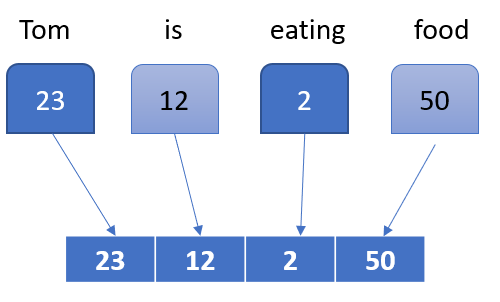
CLIP trains 2 encoders one that converts the image into image embeddings and the other converts text into text embeddings. An embedding is nothing but just an array of numbers arranged in a particular manner that represents a text or an image. The simplest example of embeddings is the ASCII representation of characters and numbers. The only difference is that these embeddings are not fixed like ASCII but rather learned through a neural network.
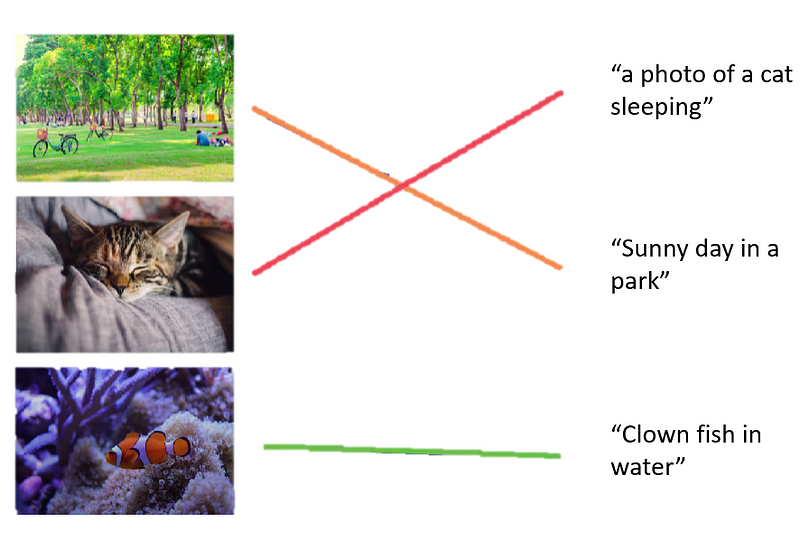
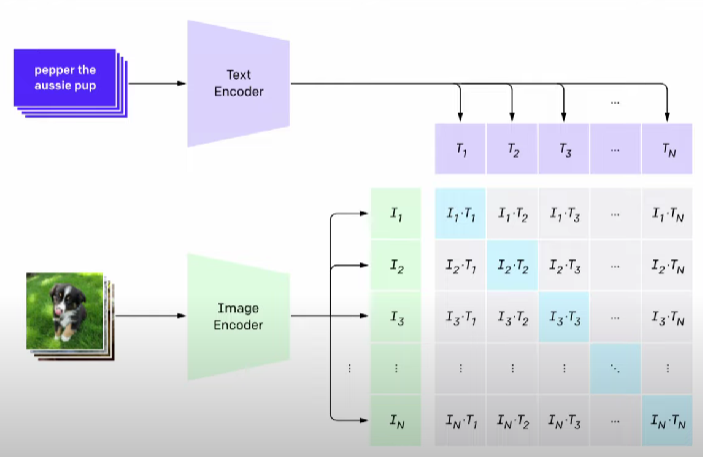
So, what does CLIP basically optimizes? CLIP basically tries to optimize that the correlation or similarity between the text embeddings and Image embeddings is as high as possible. Given below image shows what CLIP tries to achieve in its training. Ideally, all the blue blocks in the given below image should have very high similarity and all the gray blocks should have very low values or similarity.
In the paper, two different models are tried for Prior namely an autoregressive model and a diffusion model. In their experiment, it was found that the diffusion model performed better than the autoregressive model. Autoregressive models are those models that use observations from the previous time steps as input to a regression equation to predict the value at the next time step.
The Encoder: Prior Diffusion Model

CLIP text embedding is first fed to a diffusion prior to produce an image embedding, and then this embedding is used to condition a diffusion decoder which produces a final image. Note that the CLIP model is frozen during training of the prior and decoder.
A Diffusion model is basically a generative model that takes an input image and gradually increases the noise added to the input image at each given timestamp. The model adds noise till it starts looking like a complete random noise.
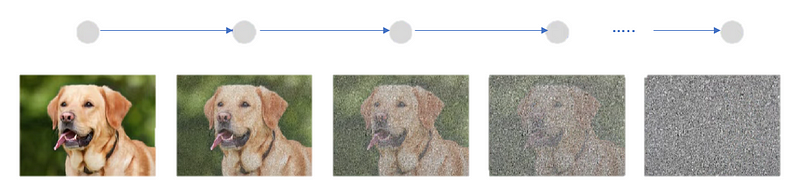
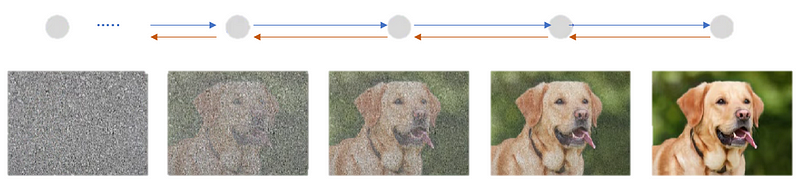
After the image is converted into a random noise image, we try to convert it back iteratively to its original state. In doing so, the network learns how to generate images from noise. It has been shown that the diffusion model has beaten GANs in image generation. We will discuss the Diffusion model in much more detail in the future blog.
Another question one might ask is why we need the Prior, why can’t we directly feed the text prompt and generate images? Look at the below image and see what happens when only a text prompt is given, when text embeddings are given, and when text+image embeddings are given. We can clearly see that giving text and image embeddings gives far superior results compared to just giving text prompt or text embeddings.

The Decoder: GLIDE
In the case of DALL-E 2, even the decoder is a diffusion model but this one’s an adjustable DIffusion model. It’s based on another paper from OpenAI called GLIDE. GLIDE is also an image generation model that takes the noisy image and iteratively improves upon them but it also adds the text embeddings to improve the image quality compared to a simple diffusion model. In addition to GLIDE’s technique, DALL-E 2 adds CLIP embeddings as well in order to increase the decoder performance. After a preliminary image of size 64x64 is created it is upsampled two times by a factor of 4 and finally resulting in a 1024x1024 sized image.
Generating variations of paintings
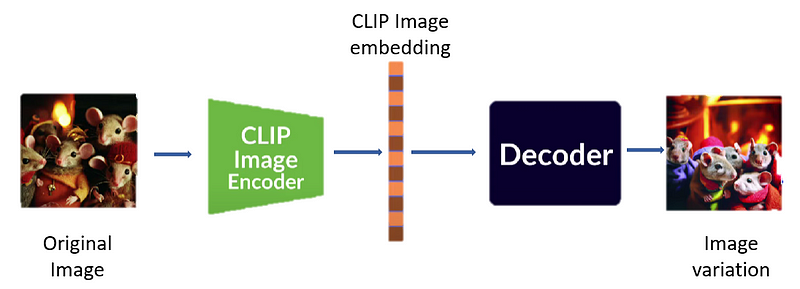
In order to generate different styles of a given painting, DALL-E 2 takes the original image and passes it through the CLIP image encoder to generate Image embedding and which later on is fed to the decoder to generate the different variations of the same image. NOTE: This process doesn’t use the Prior part of the network. Through this, we can also calculate what details are captured by CLIP and what is missed by it. We can see in the below image that it preserves the basic structure of the image i.e. a bunch of mice whereas it changes the lighting and their dresses.
It is very tough to come up with a metric that can determine how well the network is performing. Thus a humans rated the image based on three criterias namely caption similarity, photorealism and sample diversity. Since there is not an actual mathematical formula yet to see how well the model is performing we have to rely on the human intelligence to rate DALL-E 2’s performance.
Fail Cases
Just like any other model DALL-E 2 also fails in a few cases. It was shown that DALL-E 2 struggled when it came to putting text on the image and also it struggles when it came to putting things into perspective according to their physical attributes.

DALL-E 2 is an extremely powerful model, given the misuse of this technology, it's not been made publicly available as of now. It will be released in phases with more testing and implications on its wrong usage.
Original Paper: link
Thanks for giving your time and if you think that this blog added something to your knowledge base, please consider following the AIGuys Blog, and if you are interested to become a writer at AI guys you can follow this link.



