
LLM Architectures Explained: Attention Mechanism(Part 5)
Deep Dive into the architecture & building of real-world applications leveraging NLP Models starting from RNN to the Transformers.
Posts in this Series
- NLP Fundamentals
- Word Embeddings
- RNNs, LSTMs & GRUs
- Encoder-Decoder Architecture
- Attention Mechanism ( This Post )
- Transformers
- BERT
- GPT
- LLama
- Mistral
Table of Contents
· 1. Introduction ∘ 1.1 Overview ∘ 1.2 Motivation · 2. Attention Mechanism: A Solution ∘ 2.1 The Idea ∘ 2.2 How Does Attention Work? · 3. Attention Mechanism in a Model · 4. Types of Attention mechanisms ∘ 4.1 Bahdanau Attention (Additive Attention) ∘ Step 1: Compatibility Score Calculation ∘ Step 2: Attention Weights ∘ Step 3: Context Vector ∘ 4.2 Luong Attention (Multiplicative Attention) ∘ 4.3 Self-Attention ( Scaled Dot-Product Attention ) ∘ 4.3.1 What’s Inside the Self-Attention Block? ∘ 4.3.2 How Does Self-Attention Work? ∘ Step 1: Compute the Query, Key, and Value Matrices ∘ Step 2: Calculate Attention Scores ∘ Step 3: Scaling the Scores ∘ Step 4: Apply the Softmax Function ∘ Step 5: Weight the Values ∘ 4.4 Multi-Head Attention ∘ Step 1: Linear Projections ∘ Step 2: Scaled Dot-Product Attention ∘ Step 3: Concatenation ∘ Step 4: Final Linear Projection ∘ 4.5 Cross-Attention ∘ 4.5.1 Masked Multi-Head Attention ∘ 4.6 Google’s Neural Machine Translation (GNMT): Another Example ∘ 4.7 Global & Local Attention ∘ 4.8 Hard & Soft Attention · 5. Attention over LSTMs · 6. Score Functions · 7. Attention Mechanism in Computer Vision ∘ 7.1 Types of Attention in Computer Vision ∘ 7.2 Key Applications ∘ 7.3 Benefits · 8. Conclusion · 9. Test your Knowledge! ∘ 9.1 DIY
1. Introduction
1.1 Overview
The Attention Mechanism has revolutionized deep learning models, particularly in handling complex tasks involving long-range dependencies, such as natural language processing (NLP), machine translation, and even image recognition. It was first introduced in the context of neural machine translation to address limitations in handling long sequences but has since become a foundational concept in several modern architectures, including Transformers.
Before even beginning to explain Attention we have to go back and see the problem which Attention was supposed to solve.
1.2 Motivation
Before attention and transformers, Sequence to Sequence (Seq-2-Seq) learning worked pretty much like this:
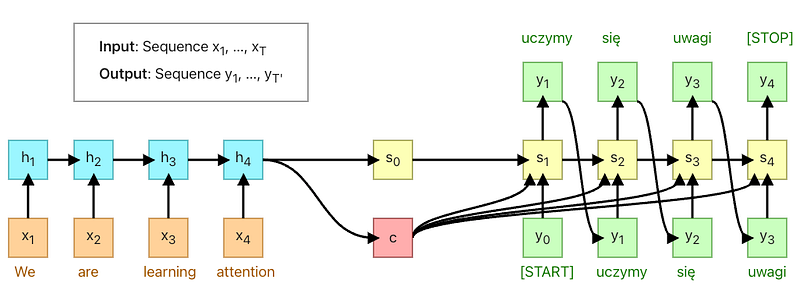
This solution works fine as long as the sentence is short. After the encoder is done with its job, we’re left with the context vector c and the initial decoder state s0. Those two vectors have to “summarize” the whole input sequence because we’re going to feed them into the decoder part of our model. You can treat the context vector as something that transfers information between the encoded sequence and the decoded sequence.
For long sentences, like T=100, it is highly probable that our context vector c is not going to be able to hold all meaningful information from the encoded sequence.
It is a lot easier to compress the first sentence to the context vector than to do the same for a whole quote. We could create longer and longer context vectors but because RNNs are sequential that won’t scale up. That’s where the Attention Mechanism comes in.
Limitations of the Context Vector
In tasks like machine translation, word-for-word translation is rarely sufficient due to differences in sentence structure across languages.
A simple example:
English => French
red => rouge
dress => robe
“red dress” => “robe rouge”
Notice how red is before dress in English but rouge is after robe.Here, the order of words changes between languages. To handle this, traditional models use a context vector, an intermediate representation that encodes the entire input sentence into a fixed-size vector before generating the output.
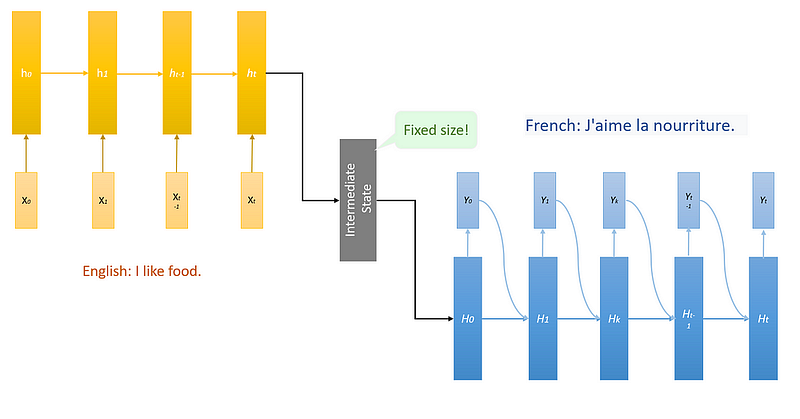
However, the fixed size of the context vector is a major limitation. Since it can only hold a limited amount of information, its ability to accurately represent longer sentences decreases. For instance, if each word in a short sentence gets equal attention, a longer sentence forces the model to allocate less attention to each word, leading to information loss. As a result, the quality of the output declines, especially in long sequences.
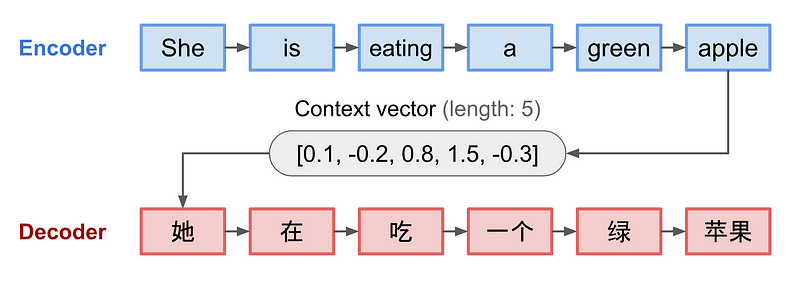
This problem became evident in early Seq2Seq models, where longer input sentences caused the model to forget earlier parts of the input. To overcome this, the attention mechanism was introduced, allowing models to focus on specific parts of the input dynamically, rather than relying on a single context vector to store all the information.
To Sum Up
- Handling Long-Range Dependencies: Traditional models like RNNs struggled with long sequences. Attention enables the model to focus on any part of the sequence, regardless of distance, improving tasks like language translation.
- Parallel Processing and Scalability: Attention, especially in Transformer models, allows parallel processing of sequences, unlike RNNs, which process tokens sequentially, leading to faster, more scalable models.
- Contextual Understanding: Attention improves understanding of contextual relationships, allowing the model to focus on important words or regions, leading to better accuracy in tasks like machine translation.
- Flexibility Across Domains: Initially for NLP, attention is now used in various domains, such as computer vision, where it highlights relevant image regions for tasks like object detection.
- Improved Interpretability: Attention provides transparency by showing what the model is focusing on, aiding in understanding decisions in sensitive applications like healthcare.
- Enhanced Seq2Seq Performance: Attention helps sequence-to-sequence models, like in translation, avoid information loss by dynamically focusing on different parts of the input, improving performance.
2. Attention Mechanism: A Solution
2.1 The Idea
The idea is to create a new context vector every timestep of the decoder which attends differently to the encoded sequence. Attention acts as a bridge between the encoder and decoder, allowing the decoder to access all encoder hidden states rather than relying solely on the final one. With this mechanism, the model can focus on relevant parts of the input sequence, enabling it to align input segments with their corresponding output segments. This alignment process helps the model handle long input sequences more effectively.
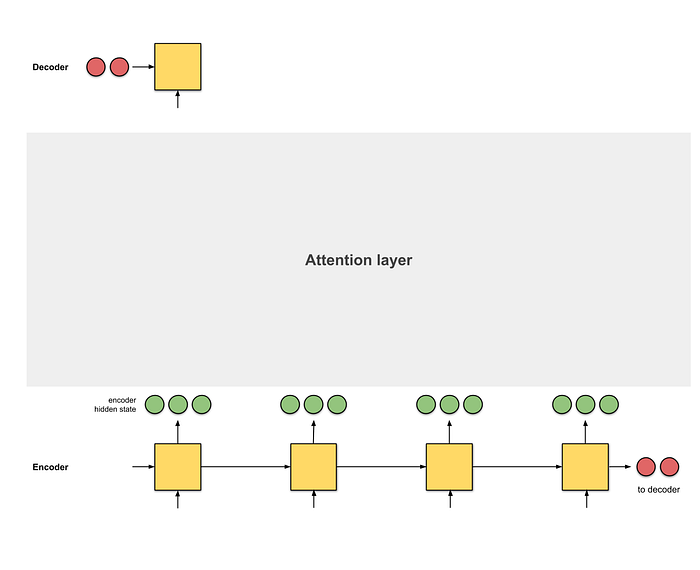
To address the “context bottleneck,” Bahdanau et al. introduced an architecture that creates a unique context vector for each time step in the decoder. This is done by computing weighted aggregations across all encoder hidden states, rather than summarizing the sequence into a single vector.
For example, when translating “I love you” into Spanish as “te amo,” the attention mechanism aligns the related words in both languages. This allows the decoder to search for the most relevant encoder time steps at each decoding phase, independent of the temporal position in the input sequence.
As the model generates the output sequence, it continually compares the current decoder hidden state with all encoder hidden states to create a new context vector. This selective focus on important sections within the input is the essence of attention. When constructing a sentence, the model identifies positions within the encoder’s hidden states that contain the most relevant information, enhancing its ability to handle long sequences effectively.
This selective focus on relevant areas is what we call “attention.”
For further reading, check out the transformative papers:
Bahdanau et al. (2014), “Neural Machine Translation by Jointly Learning to Align and Translate”
Vaswani et al. (2017), “Attention is All You Need”
2.2 How Does Attention Work?
Before we look at how attention is used, allow me to share the intuition behind a translation task using the seq2seq model.
Intuition: seq2seq A translator reads the German text from start till the end. Once done, he starts translating to English word by word. It is possible that if the sentence is extremely long, he might have forgotten what he has read in the earlier parts of the text.
So that’s a simple seq2seq model. The step-by-step calculation for the attention layer I am about to go through is a seq2seq+attention model. Here’s a quick intuition on this model.
Intuition: seq2seq + attention A translator reads the German text while writing down the keywords from the start till the end, after which he starts translating to English. While translating each German word, he makes use of the keywords he has written down.
Attention places different focus on different words by assigning each word with a score. Then, using the softmaxed scores, we aggregate the encoder hidden states using a weighted sum of the encoder hidden states, to get the context vector.
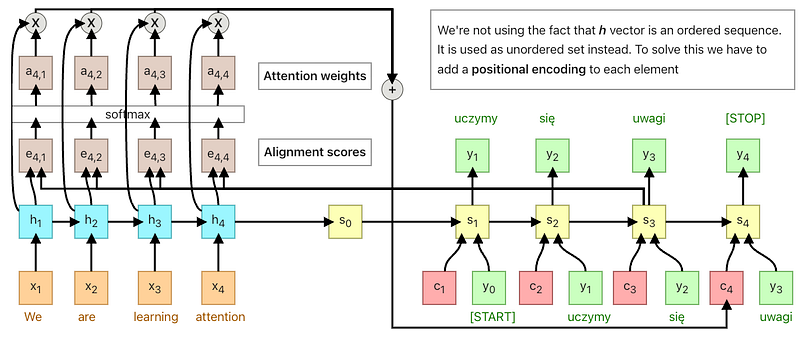
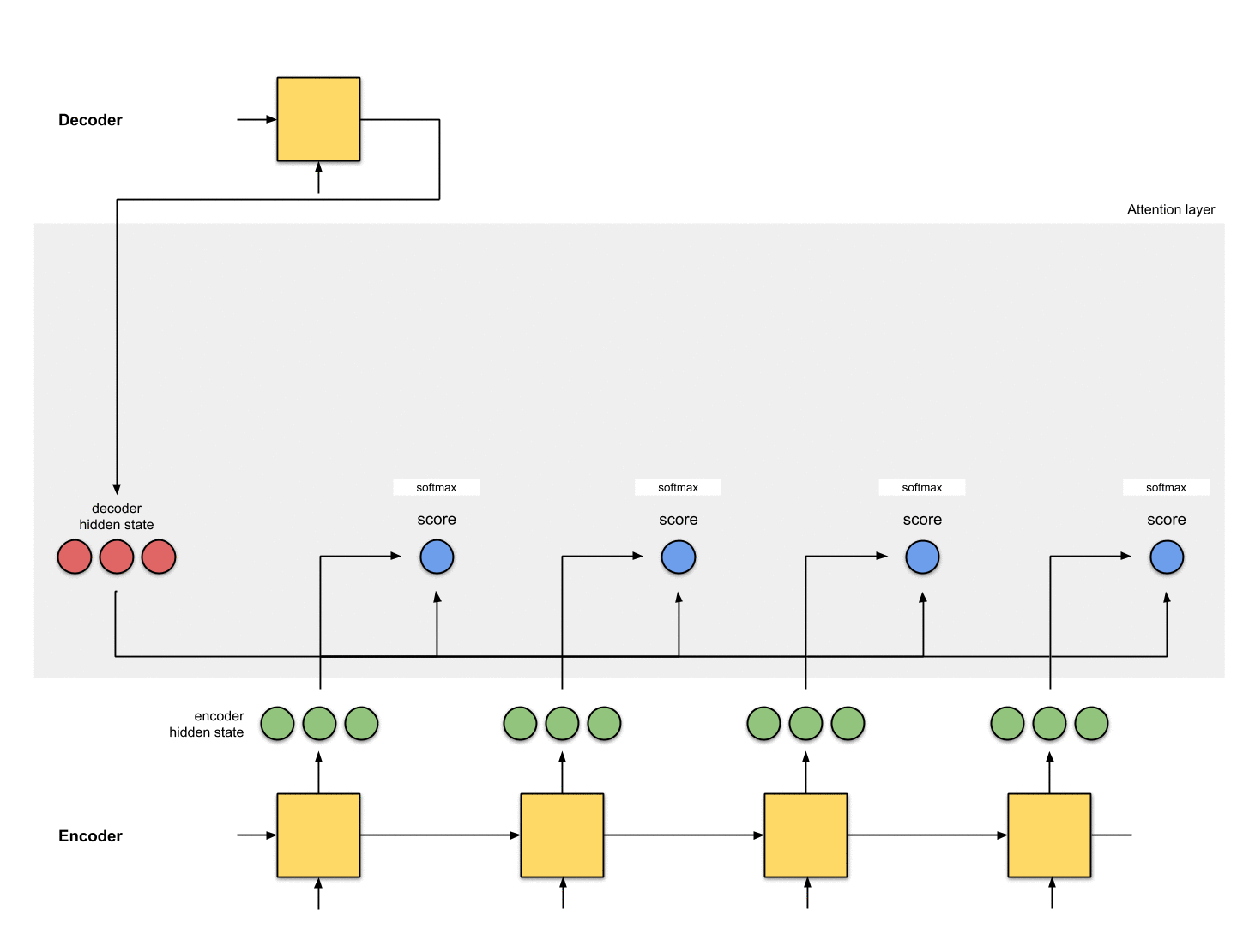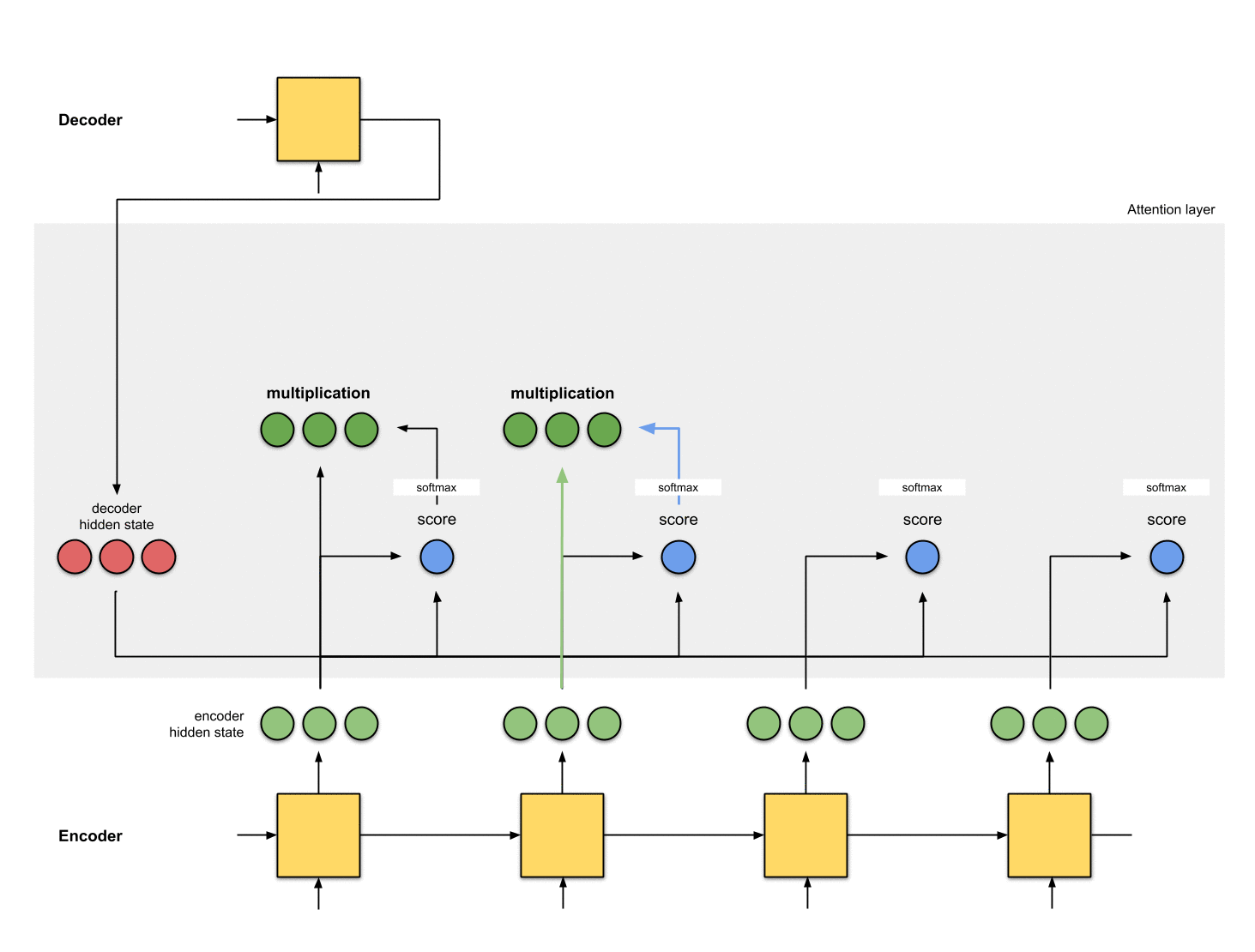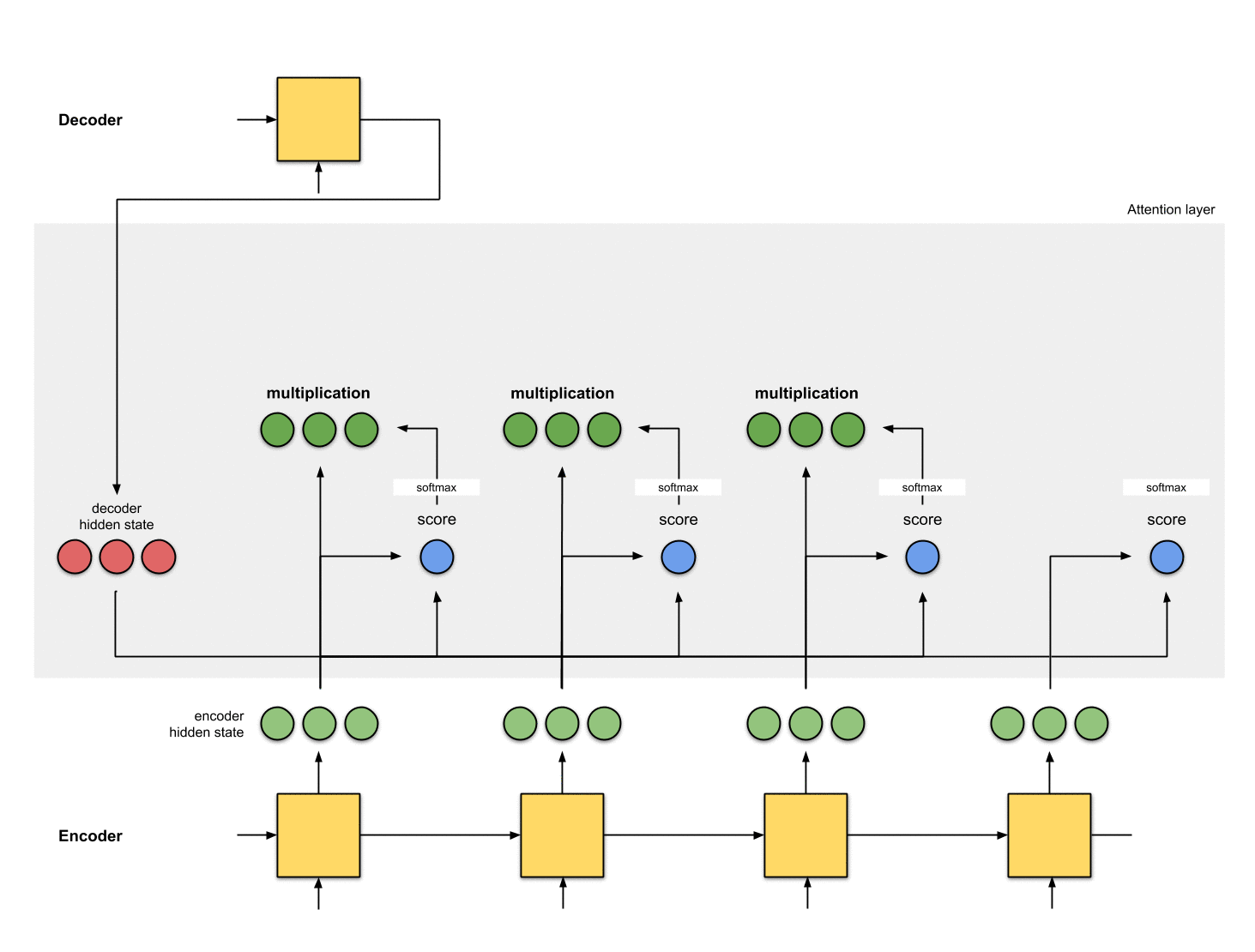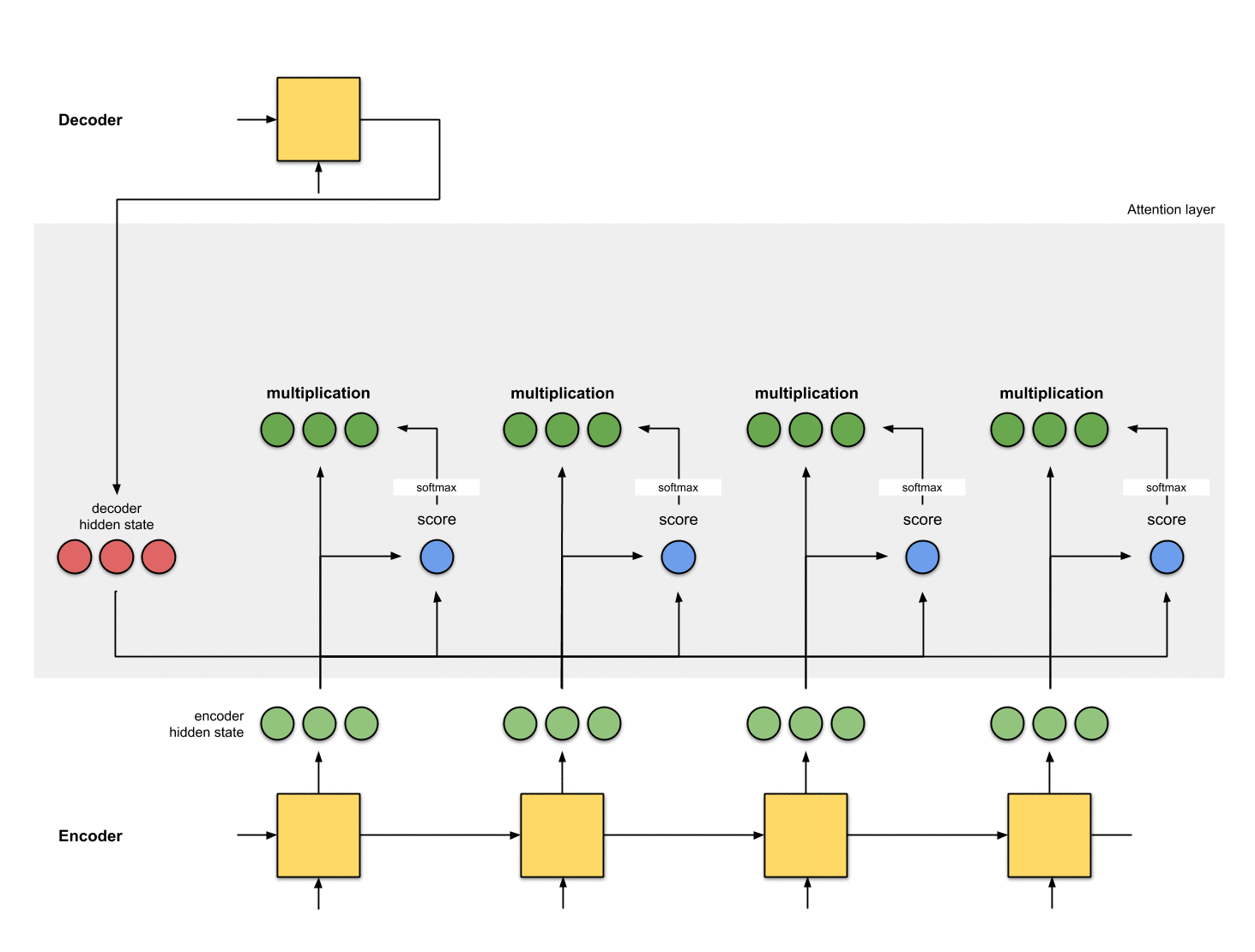
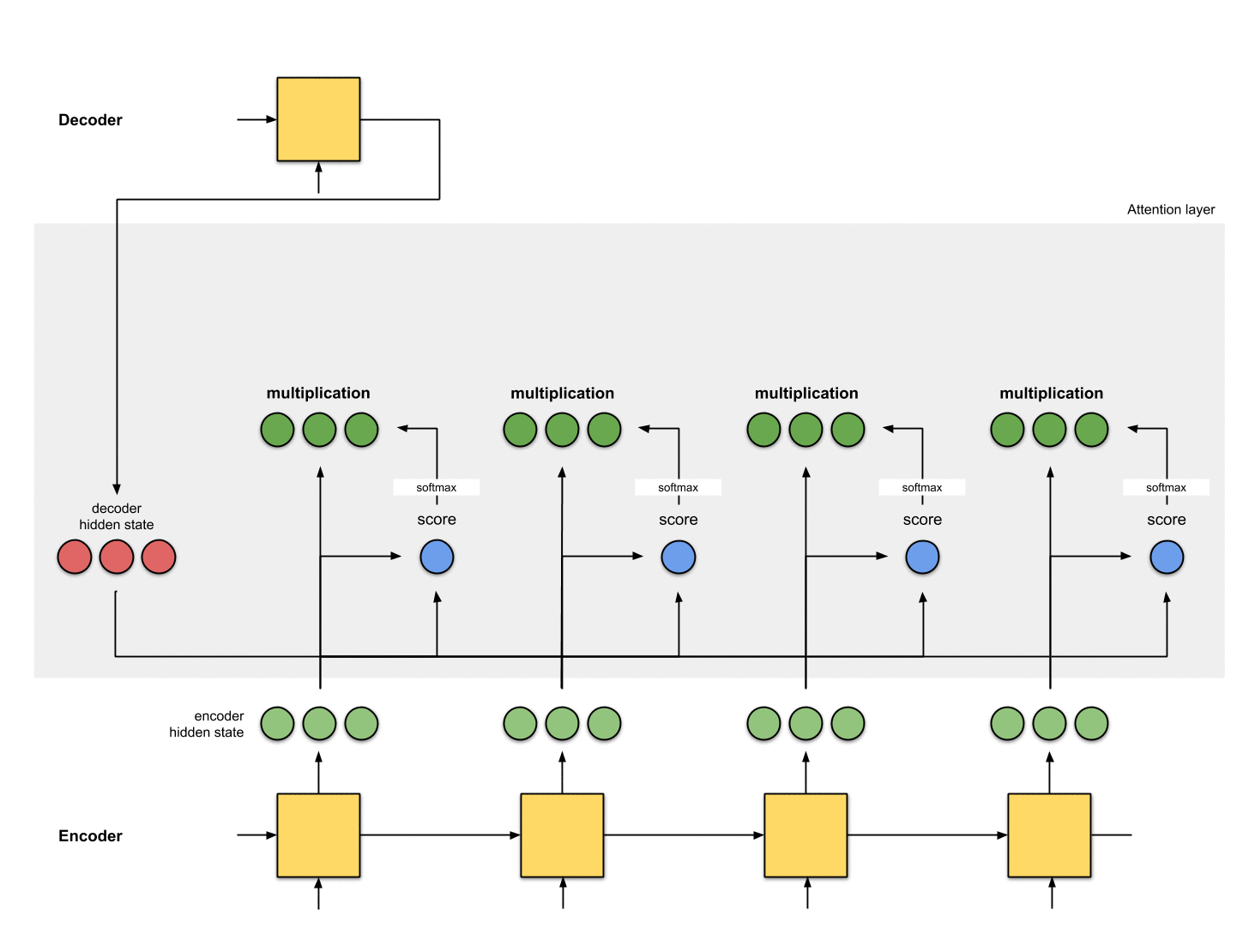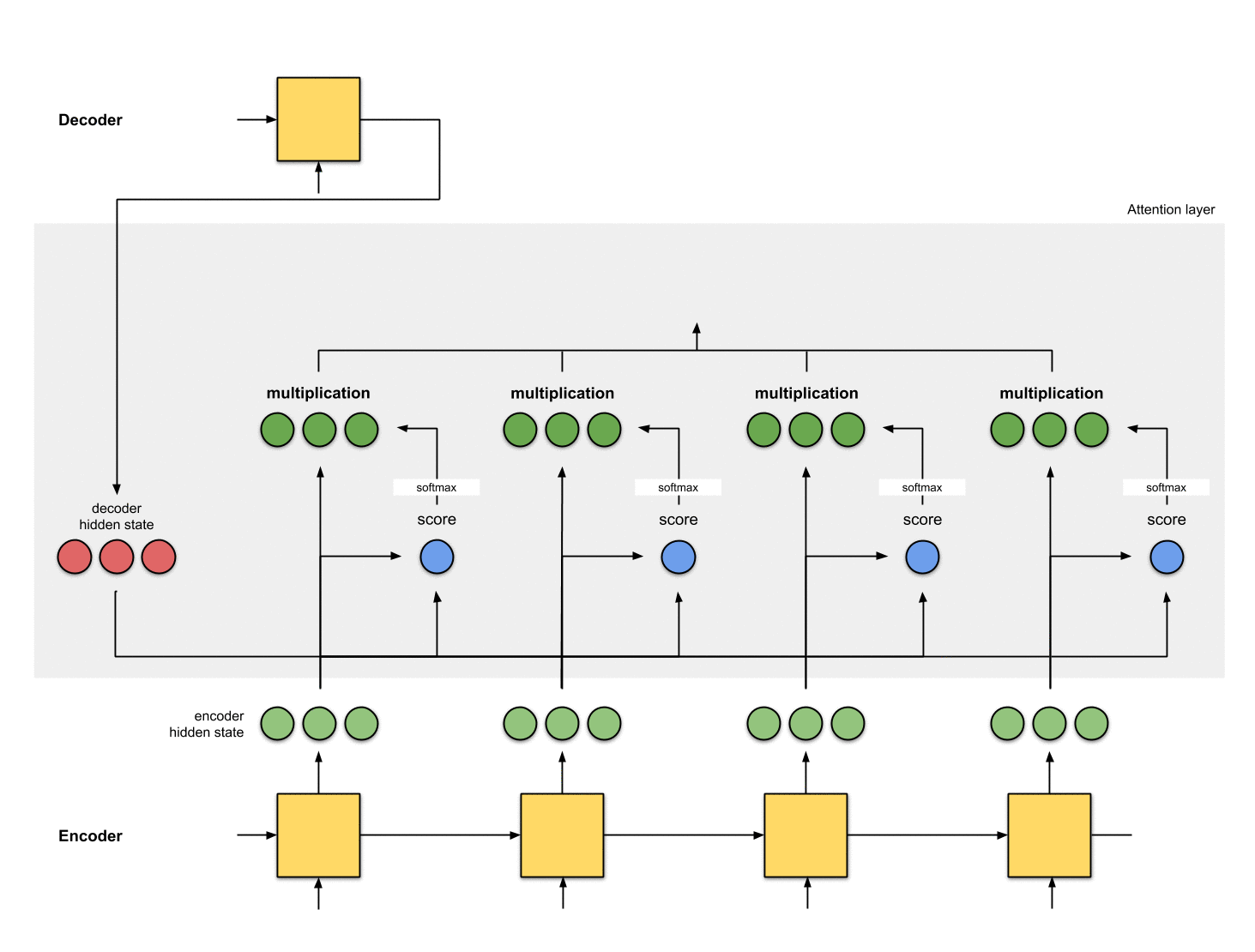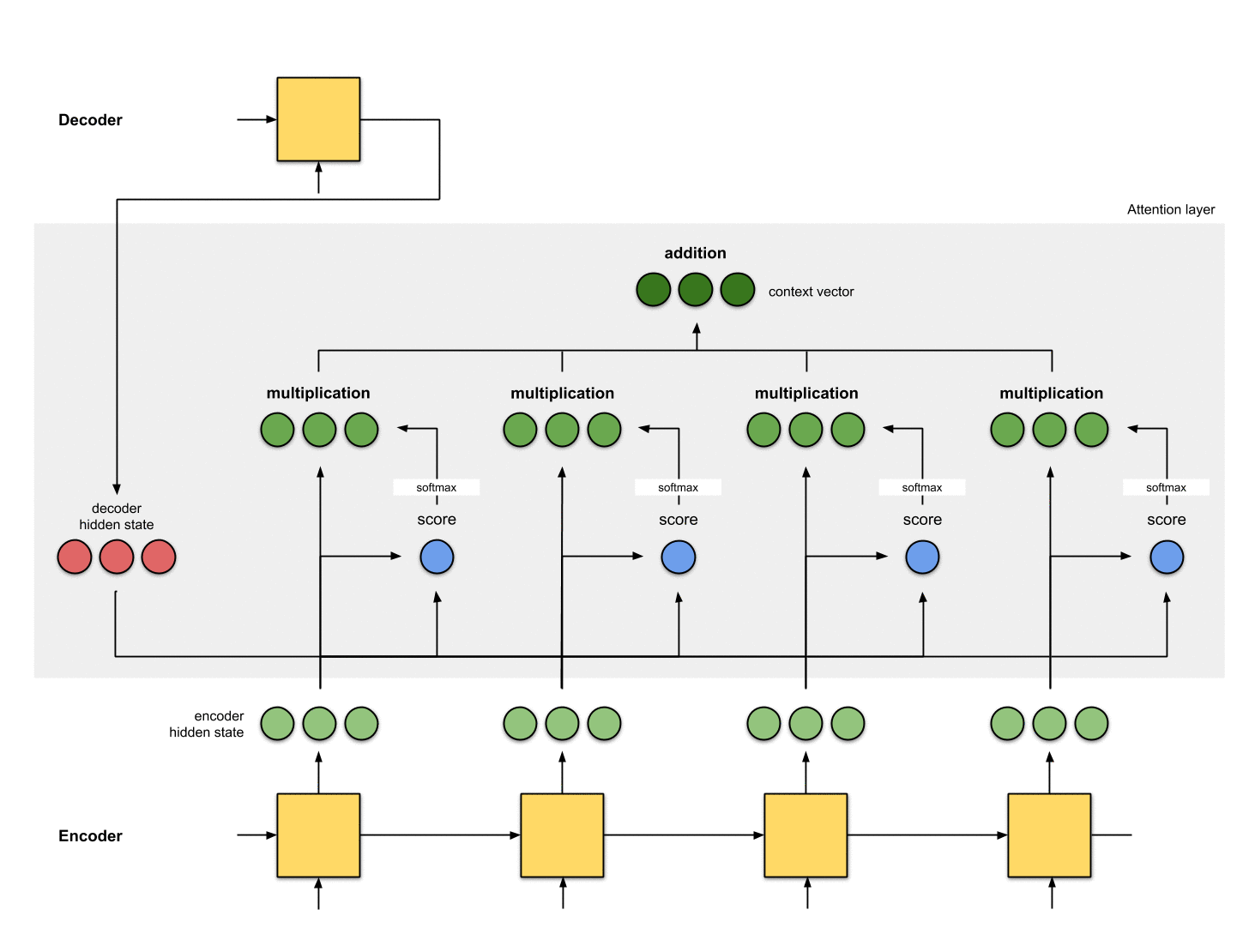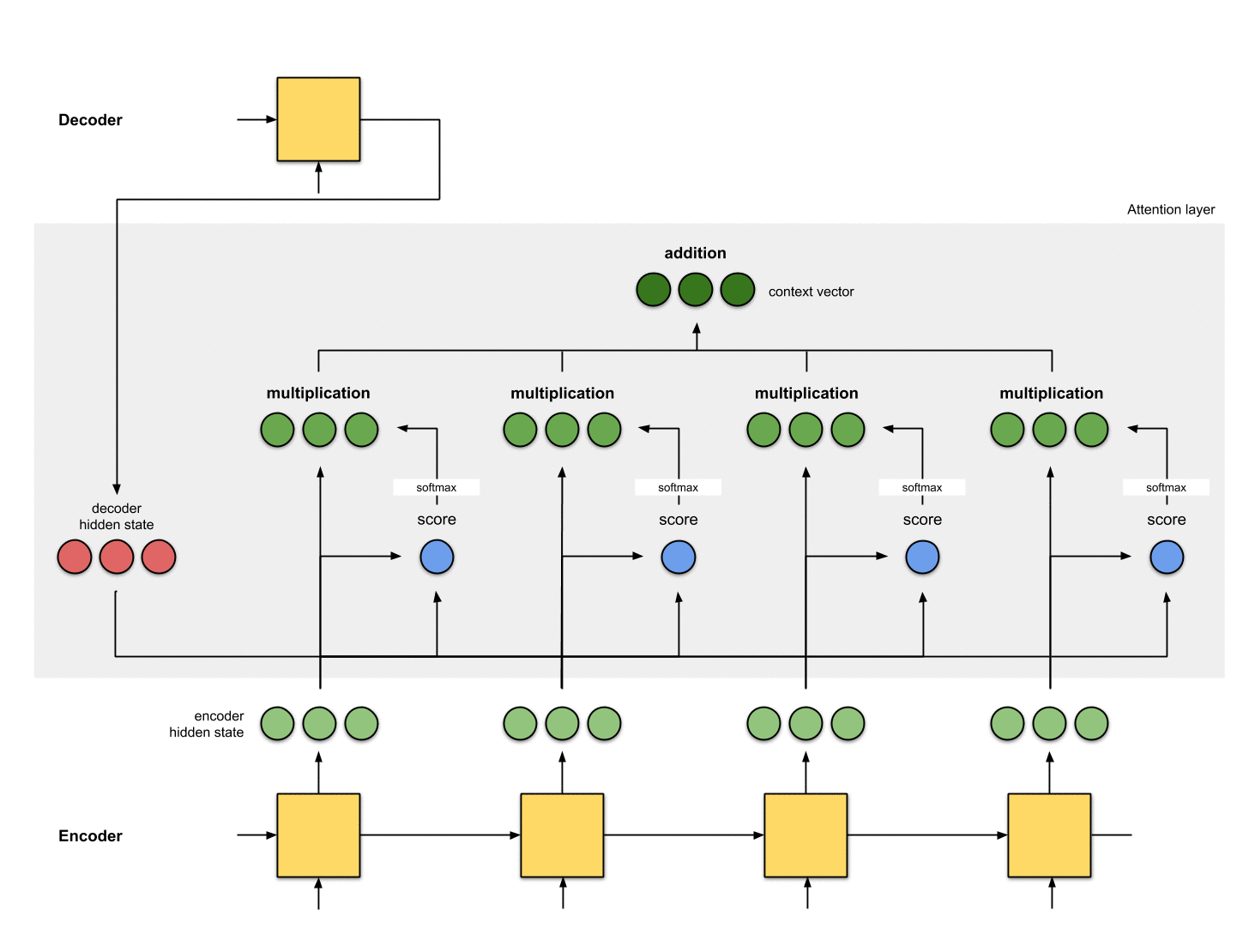
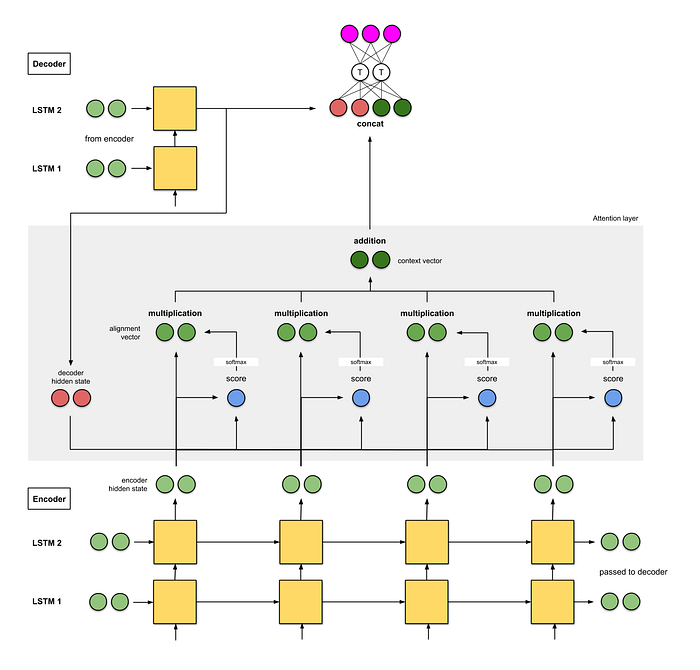
The implementations of an attention layer can be broken down into 4 steps.
Step 0: Prepare hidden states.
Let’s first prepare all the available encoder hidden states (green) and the first decoder hidden state (red). In our example, we have 4 encoder hidden states and the current decoder hidden state. (Note: the last consolidated encoder hidden state is fed as input to the first time step of the decoder. The output of the first time step of the decoder is called the first decoder hidden state, as seen below.)

Step 1: Obtain a score for every encoder hidden state.
A score (scalar) is obtained by a score function (also known as the alignment score function or alignment model). In this example, the score function is a dot product between the decoder and encoder hidden states.
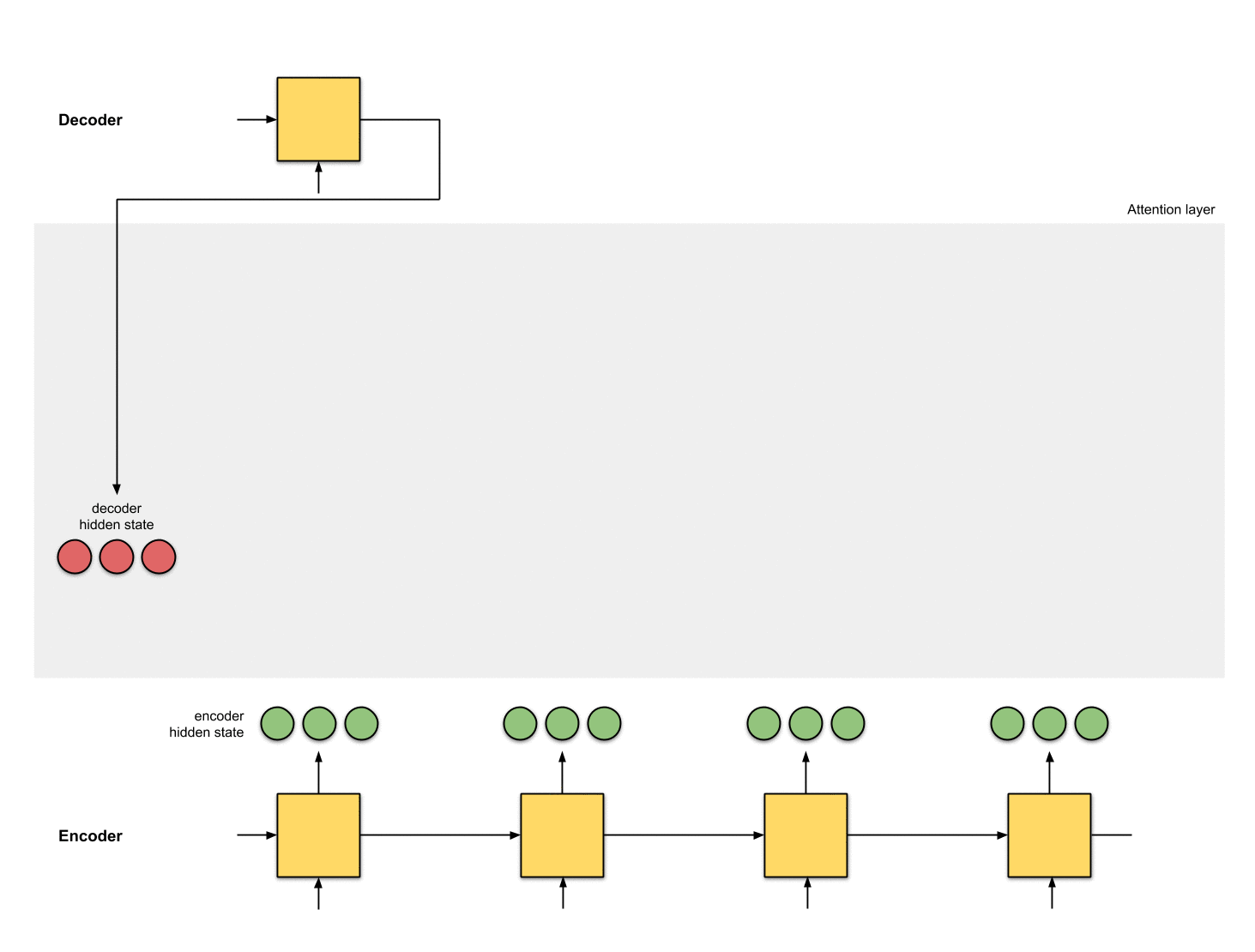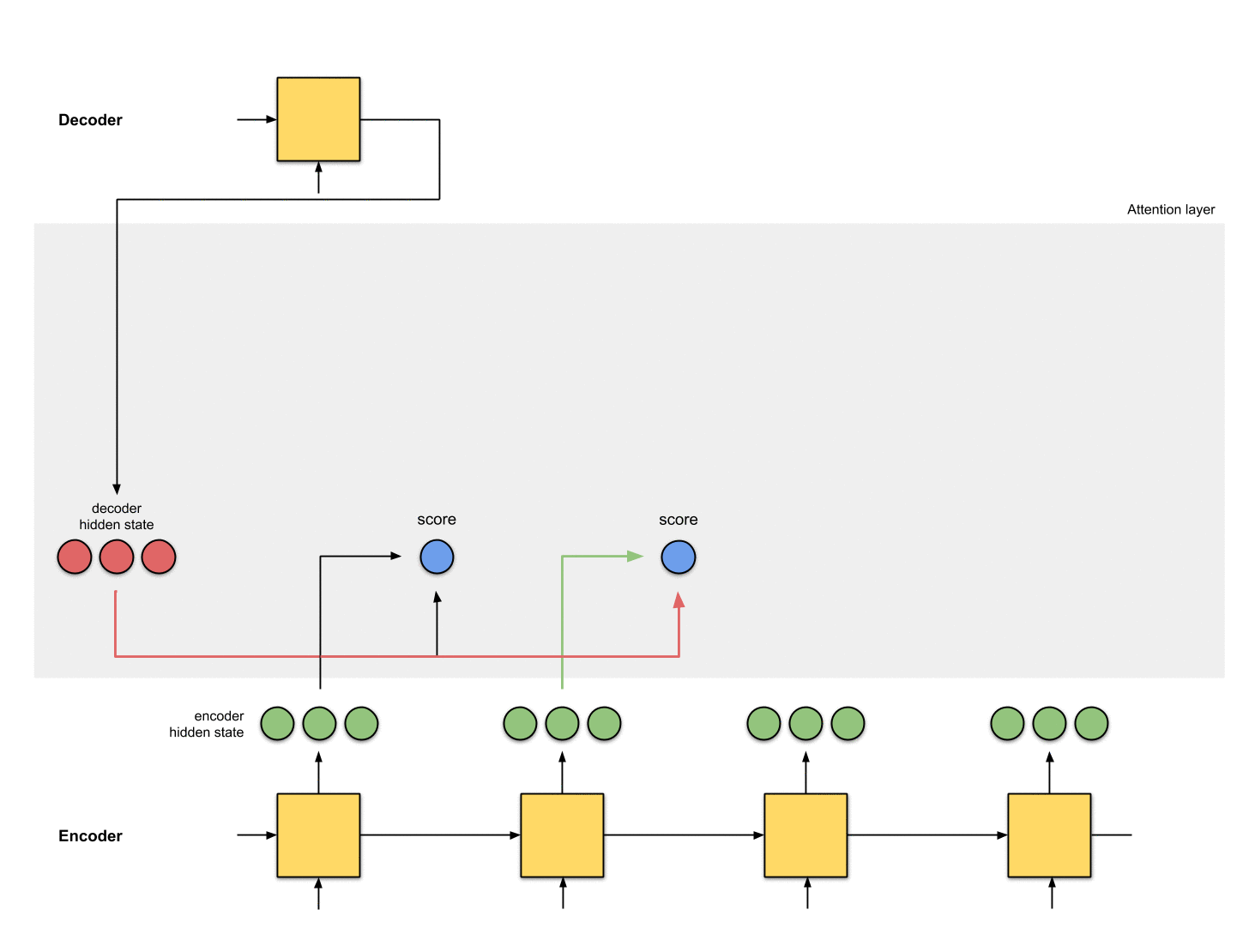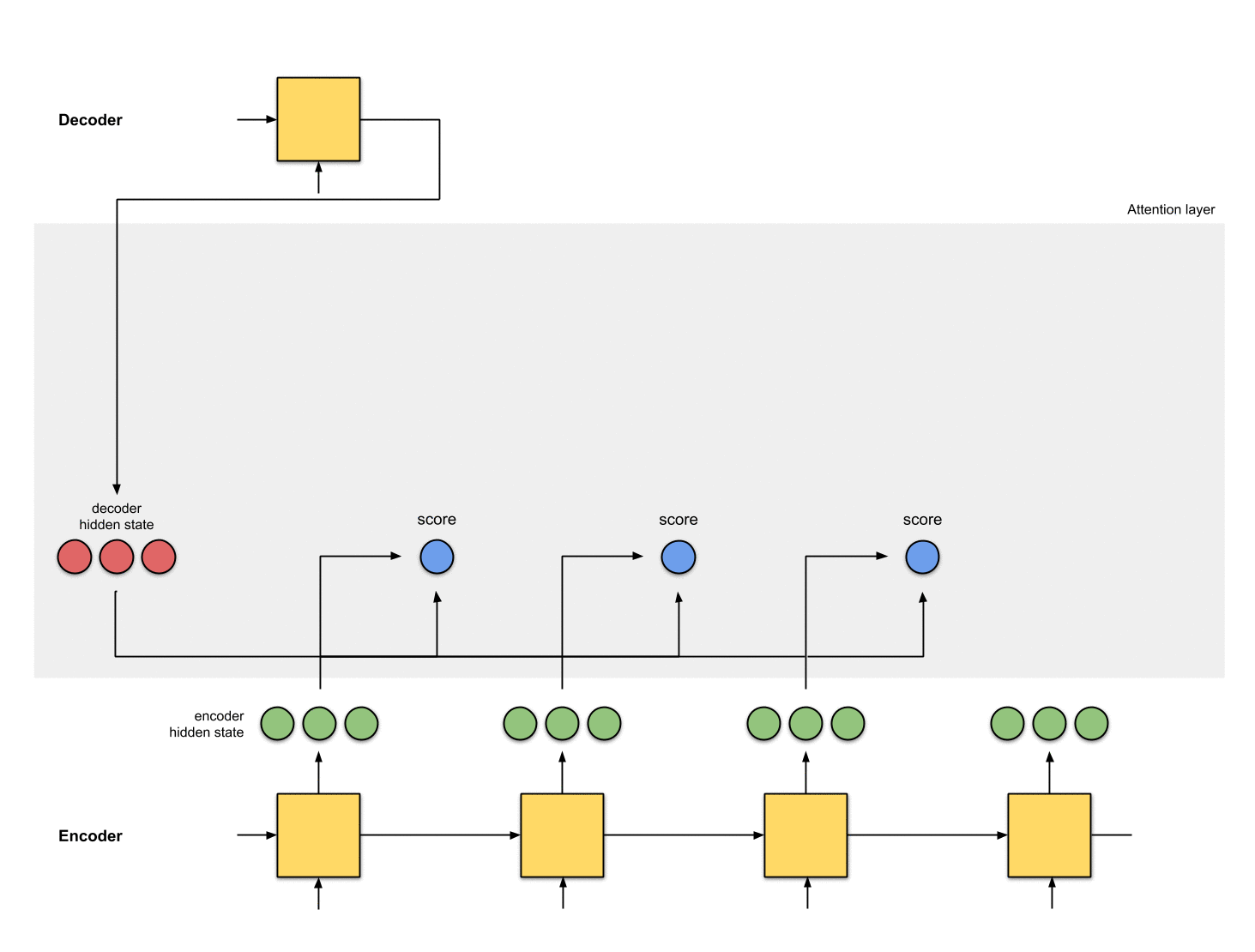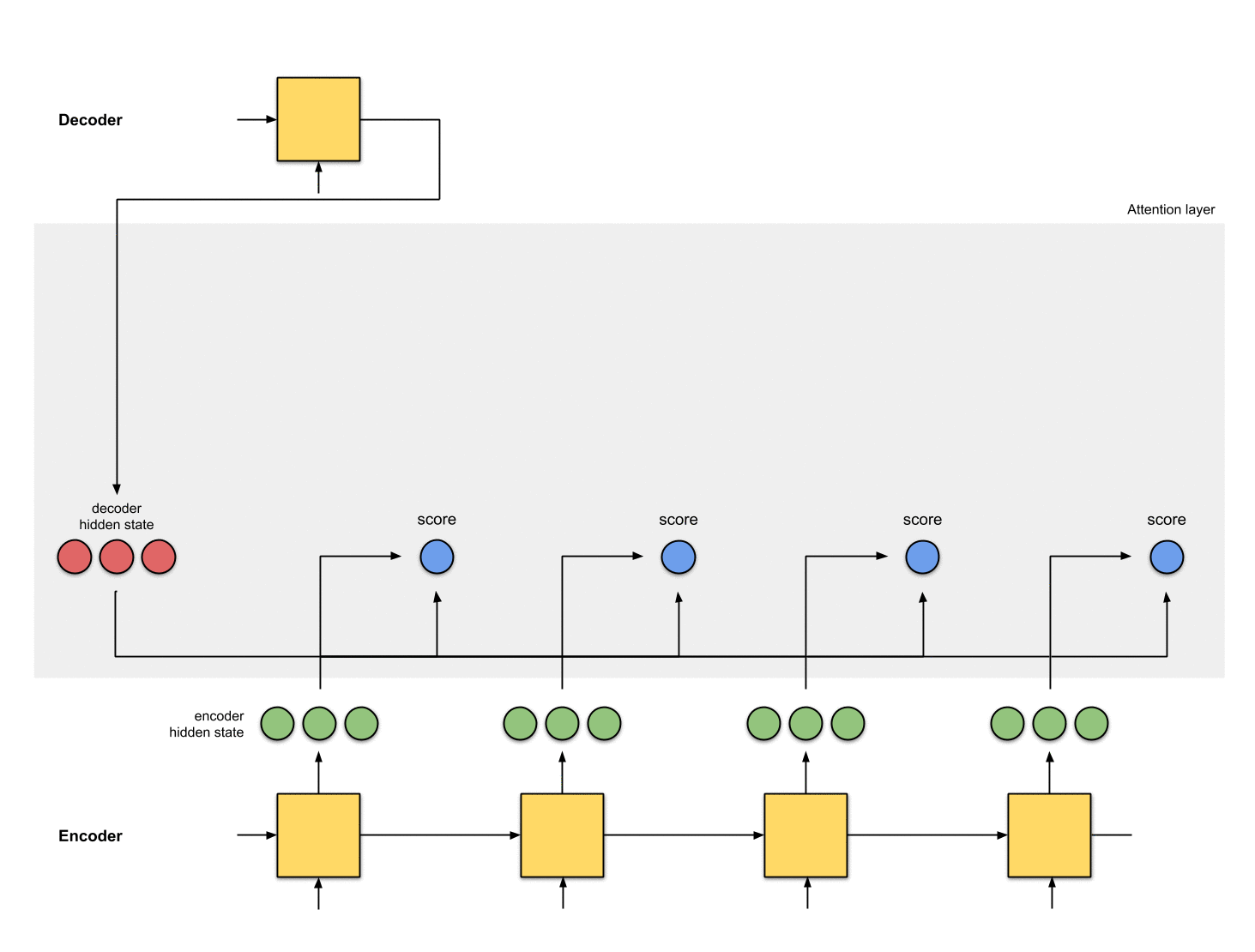
decoder_hidden = [10, 5, 10]
encoder_hidden score
---------------------
[0, 1, 1] 15 (= 10×0 + 5×1 + 10×1, the dot product)
[5, 0, 1] 60
[1, 1, 0] 15
[0, 5, 1] 35In the above example, we obtain a high attention score 60 for the encoder hidden state [5, 0, 1]. This means that the next word (next output by the decoder) is going to be heavily influenced by this encoder hidden state.
Step 2: Run all the scores through a softmax layer.
We put the scores to a softmax layer so that the softmaxed scores (scalar) add up to 1. These softmaxed scores represent the attention distribution.
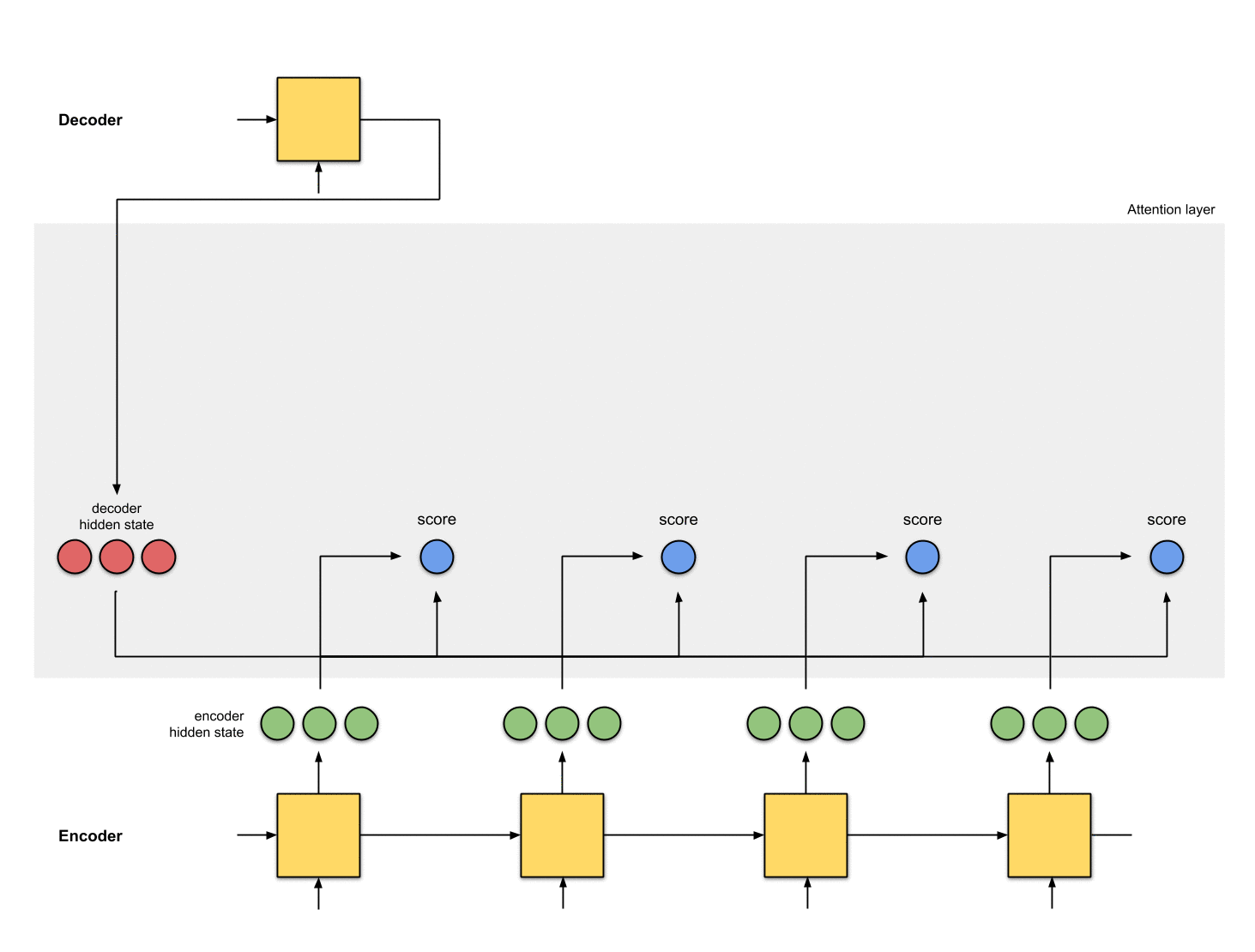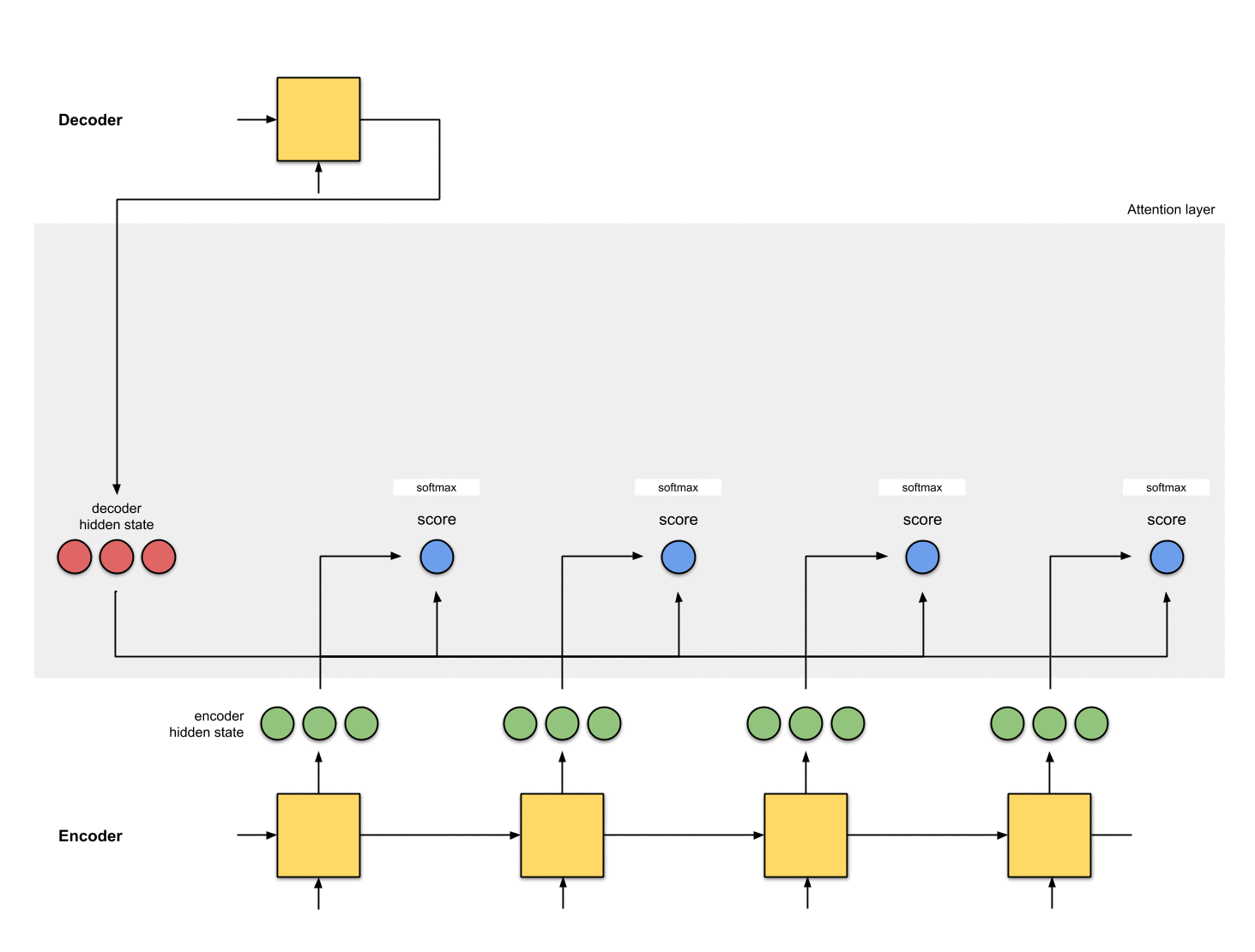
encoder_hidden score score^
-----------------------------
[0, 1, 1] 15 0
[5, 0, 1] 60 1
[1, 1, 0] 15 0
[0, 5, 1] 35 0Notice that based on the softmaxed score score^, the distribution of attention is only placed on [5, 0, 1] as expected. In reality, these numbers are not binary but a floating-point between 0 and 1.
Step 3: Multiply each encoder hidden state by its softmaxed score.
By multiplying each encoder hidden state with its softmaxed score (scalar), we obtain the alignment vector or the annotation vector. This is exactly the mechanism where alignment takes place.
encoder score score^ alignment
---------------------------------
[0, 1, 1] 15 0 [0, 0, 0]
[5, 0, 1] 60 1 [5, 0, 1]
[1, 1, 0] 15 0 [0, 0, 0]
[0, 5, 1] 35 0 [0, 0, 0]Here we see that the alignment for all encoder hidden states except [5, 0, 1] are reduced to 0 due to low attention scores. This means we can expect that the first translated word should match the input word with the [5, 0, 1] embedding.
Step 4: Sum up the alignment vectors.
The alignment vectors are summed up to produce the context vector. A context vector is aggregated information of the alignment vectors from the previous step.
encoder score score^ alignment
---------------------------------
[0, 1, 1] 15 0 [0, 0, 0]
[5, 0, 1] 60 1 [5, 0, 1]
[1, 1, 0] 15 0 [0, 0, 0]
[0, 5, 1] 35 0 [0, 0, 0]context = [0+5+0+0, 0+0+0+0, 0+1+0+0] = [5, 0, 1]Step 5: Feed the context vector into the decoder.
The manner this is done depends on the architectural design. Later we will see in the examples how the architectures make use of the context vector for the decoder.
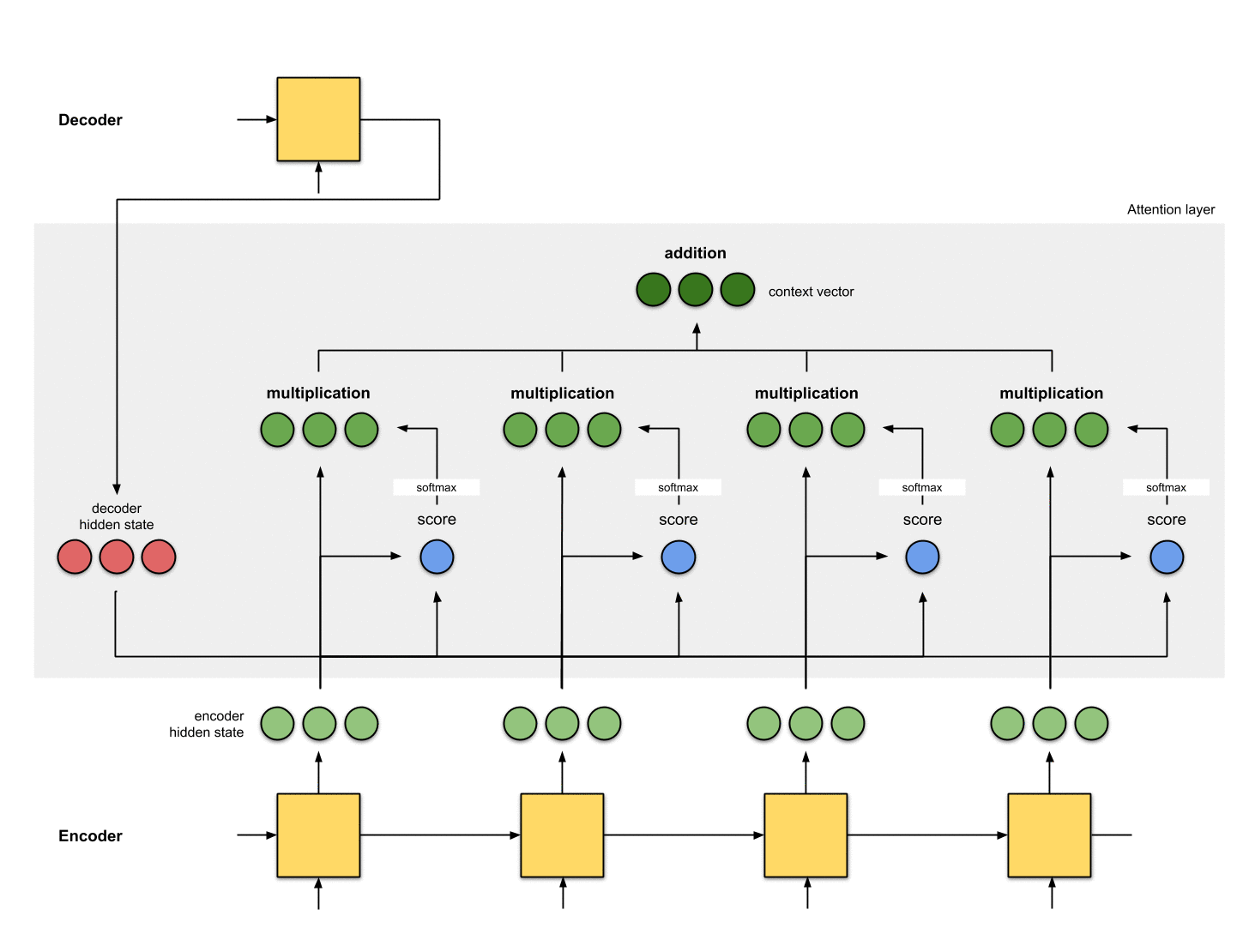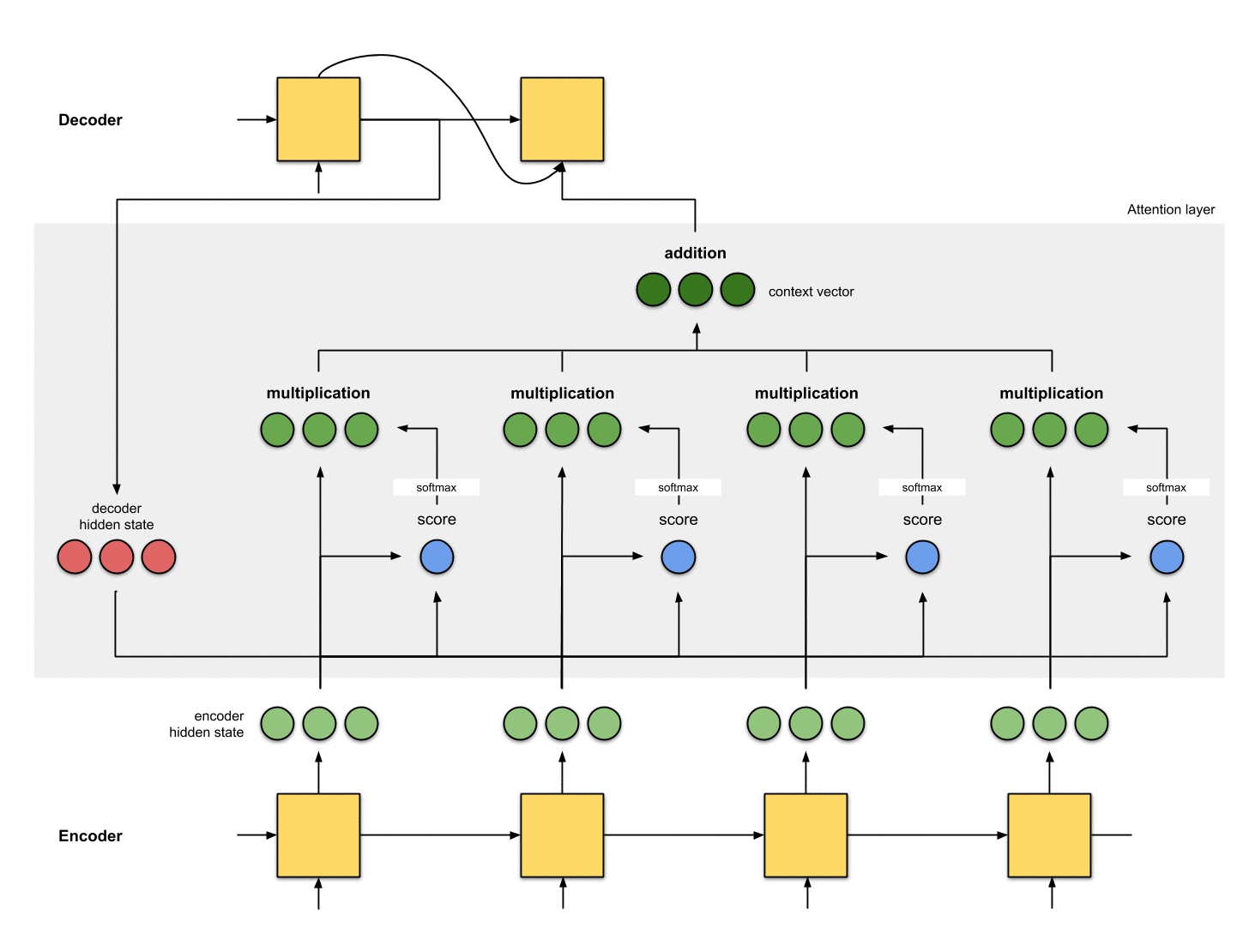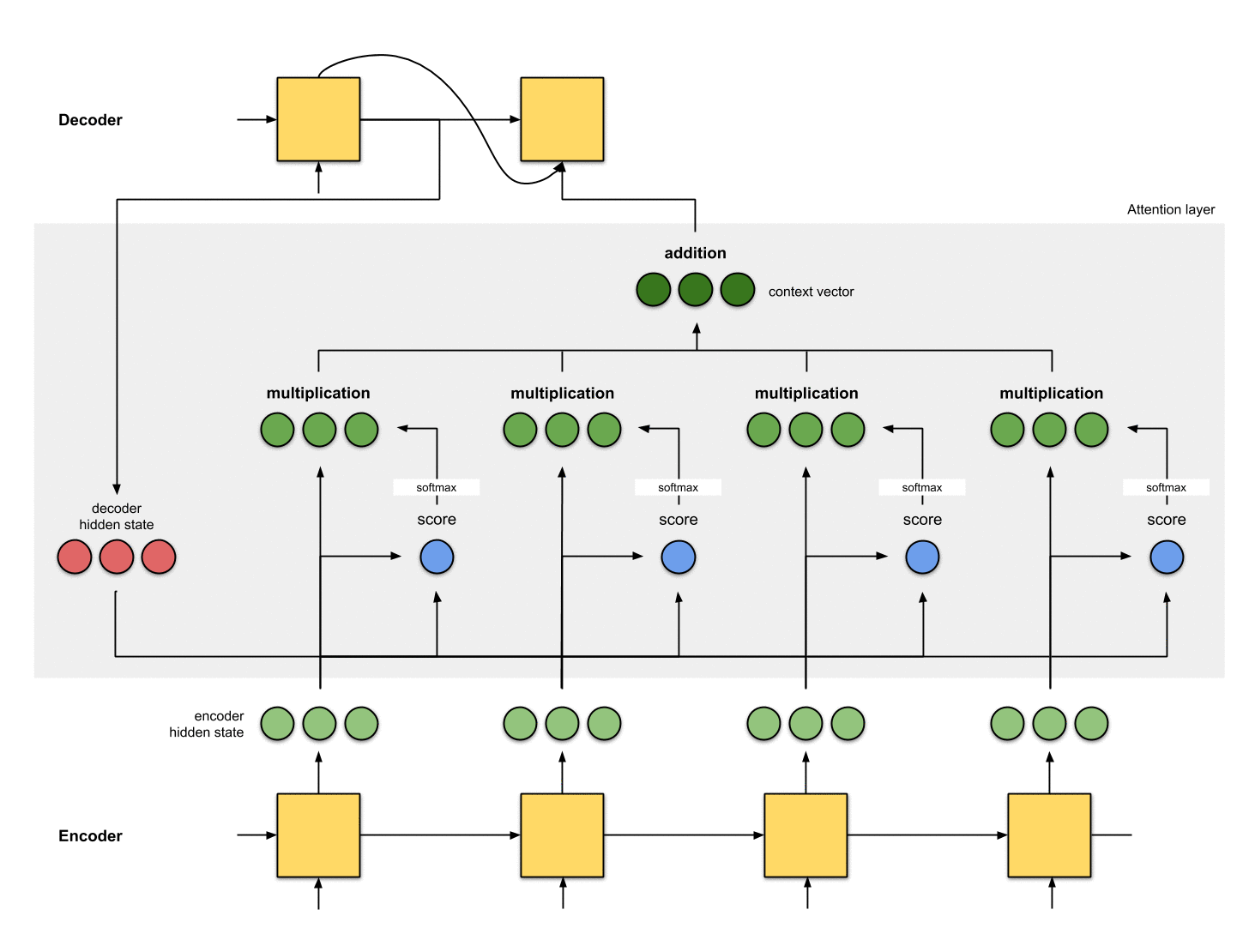
That’s about it! Here’s the entire animation:

Training and inference During inference, the input to each decoder time step t is the predicted output from decoder time step t-1. During training, the input to each decoder time step t is our ground truth output from decoder time step t-1.
Intuition: How does attention actually work?
Answer: Backpropagation, surprise surprise. Backpropagation will do whatever it takes to ensure that the outputs will be close to the ground truth. This is done by altering the weights in the RNNs and the score function (if any). These weights will affect the encoder hidden states and decoder hidden states, which in turn affect the attention scores.
3. Attention Mechanism in a Model
Here’s how attention typically operates within a model:
- Input Sequence Representation:
- The model processes the input data and generates hidden states (representations) for each token (or part) of the sequence.
- These hidden states capture the context of each token in relation to the entire input.
2. Attention Scoring:
- At each decoding step, the model generates an attention score for each token in the input sequence.
- The score determines how relevant or important a token is for generating the current output. This is usually computed by comparing the current decoder state with the encoder hidden states using dot products or learned transformations.
- The scores are normalized using a softmax function, resulting in attention weights that sum to 1.
3. Weighted Sum:
- The attention mechanism then calculates a context vector by taking the weighted sum of the encoder’s hidden states. Each hidden state’s contribution to the context vector is determined by its attention weight.
- The context vector now contains a focused representation of the input, emphasizing the most relevant parts for generating the current output token.
4. Decoding:
- The decoder uses this context vector, along with its own hidden states, to generate the next token in the output sequence.
- This process is repeated for each token in the output sequence, allowing the model to adaptively focus on different parts of the input at each step.
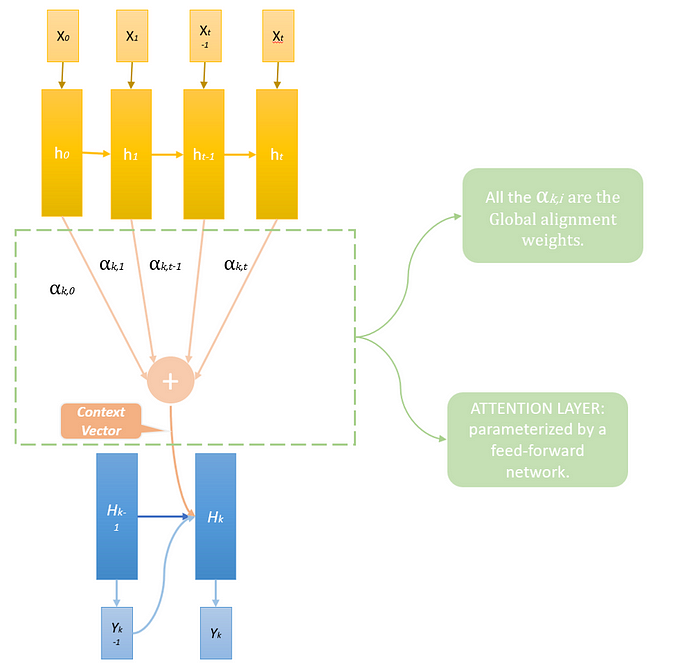
Attention mechanism tries to overcome the information bottleneck of the intermediary state by allowing the decoder model to access all the hidden states, rather than a single vector — aka intermediary state — build out of the encoder’s last hidden state, while predicting each output.
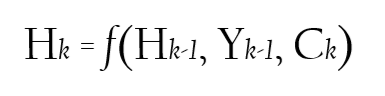
Calculating the next hidden state for the decoder model.
The input to a cell in decoder now gets the following values:
- The previous hidden state of the decoder model Hₖ-₁.
- The previous output of decoder model Yₖ-₁.
- A context vector Cₖ — a weighted sum of all encoder hidden states(hⱼ’s) aka annotations. (New addition)
4. Types of Attention mechanisms
In modern deep learning, various types of attention mechanisms have been developed, each addressing different aspects of sequence modeling and enhancing the model’s ability to focus on relevant information. Below are the most widely used types:

4.1 Bahdanau Attention (Additive Attention)
Introduced by: Dzmitry Bahdanau et al. (2014)
Bahdanau Attention, also known as Additive Attention, is a method for calculating attention weight values in sequence-to-sequence models. It was introduced by Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio in their paper “Neural Machine Translation by Jointly Learning to Align and Translate” in 2014.
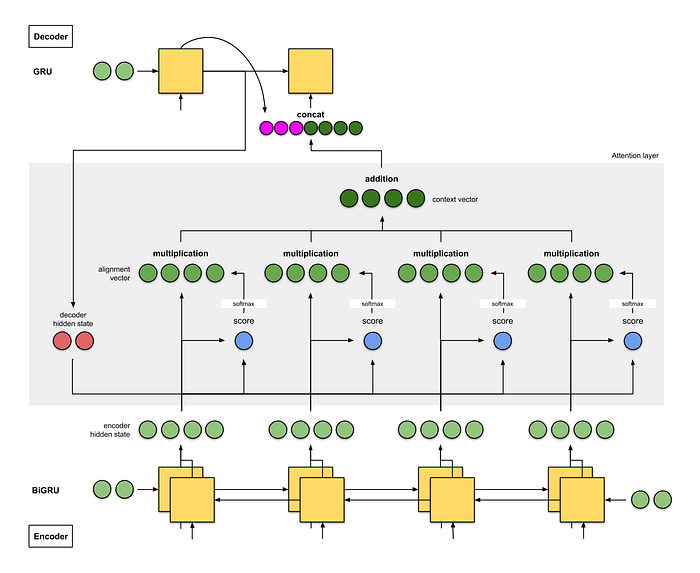
How it Works:
- It computes attention weights by learning an alignment score between the decoder’s hidden state and the encoder’s hidden states. These scores are then passed through a softmax function to normalize them into probabilities.
- Each attention weight represents the relevance of each input token to the current output token.
- The final context vector is a weighted sum of the encoder hidden states based on these attention weights.
Here’s a detailed explanation of how Bahdanau attention works:
Step 1: Compatibility Score Calculation
- At each decoding timestep, Bahdanau attention computes a compatibility score between the previous hidden state of the decoder (si−1) and each encoder hidden state (hj).
- This compatibility score is typically calculated using a feedforward neural network (often a single-layer neural network) that takes si−1 and hj as inputs.
- Mathematically, the compatibility score eij for encoder hidden state hj and decoder hidden state si−1 is calculated as follows:
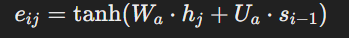
Step 2: Attention Weights
- Once the compatibility scores are computed, they are passed through another neural network (often a single-layer neural network followed by a softmax activation) to obtain attention weights.
- Mathematically, the attention weight αij for encoder hidden state hj at decoding timestep i is calculated as follows:

Step 3: Context Vector
- With the attention weights computed, the context vector ci for the current decoding timestep i is obtained by taking a weighted sum of the encoder hidden states, where the weights are given by the attention weights.
- Mathematically, the context vector ci is calculated as follows :
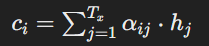
Mathematical foundation: The score is computed using a learned feed-forward network:
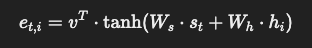
where St is the decoder hidden state, hi is the encoder hidden state, and Ws, Wh, v are learned parameters.
The authors achieved a BLEU score of 26.75 on the WMT’14 English-to-French dataset.
Intuition: seq2seq with bidirectional encoder + attention
Translator A reads the German text while writing down the keywords. Translator B (who takes on a senior role because he has an extra ability to translate a sentence from reading it backwards) reads the same German text from the last word to the first while jotting down the keywords. These two regularly discuss every word they read thus far. Once done reading this German text, Translator B is then tasked to translate the German sentence to English word by word, based on the discussion and the consolidated keywords that both of them have picked up.
Translator A is the forward RNN, Translator B is the backward RNN.
Advantages: Bahdanau Attention improves the model’s ability to handle long sequences and helps the decoder decide which part of the input to focus on at each step of output generation.
4.2 Luong Attention (Multiplicative Attention)
Introduced by: Minh-Thang Luong et al. (2015)
Luong Attention, also called Multiplicative Attention, is another attention mechanism that differs in how the alignment scores are calculated. It builds upon Bahdanau Attention but uses a simpler, more efficient scoring method by leveraging dot products.
How it Works:
- Instead of learning a separate feed-forward layer, Luong Attention computes attention scores using the dot product between the decoder hidden state and encoder hidden states.
- There are three types of scoring functions:
- Dot Product:
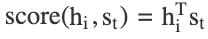
2. General:
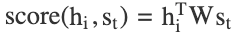
3. Concatenation: Similar to Bahdanau, but with concatenation of inputs.
Formula (Dot-Product):
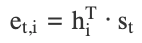
where hi is the encoder hidden state, and st is the decoder hidden state.
In Luong attention, the first difference from Bahdanau attention is that instead of considering the previous hidden state value of the decoder side, Luong attention incorporates the current timestamp hidden state value of the decoder.
The second difference lies in the method of calculating the attention weight (α) value: Luong attention utilizes the dot product between the current timestamp hidden state of the decoder (si) and each encoder hidden state (hi).
In Luong attention, the final difference is that the context vector ci is passed directly into the output of the LSTM cell, which contrasts with the approach in Bahdanau attention where the context vector is concatenated with the input to the LSTM cell. This streamlined integration of the context vector into the LSTM cell output simplifies the decoding process and enhances the model’s ability to generate accurate outputs. Diagrams can indeed aid in understanding these concepts visually.
On the WMT’15 English-to-German, the model achieved a BLEU score of 25.9.
Intuition: seq2seq with 2-layer stacked encoder + attention
Translator A reads the German text while writing down the keywords. Likewise, Translator B (who is more senior than Translator A) also reads the same German text, while jotting down the keywords. Note that the junior Translator A has to report to Translator B at every word they read. Once done reading, both of them translate the sentence to English together word by word, based on the consolidated keywords that they have picked up.
Advantages: Luong Attention is computationally more efficient due to the use of simple dot products, making it faster and more scalable for large models.
4.3 Self-Attention ( Scaled Dot-Product Attention )
Introduced by: Vaswani et al. (2017) in the Transformer
Self-Attention allows a model to focus on different parts of the same input sequence. This mechanism is key to Transformers, where it enables each token in a sequence to attend to every other token, learning global dependencies in the sequence.
How it Works:
- Each input token is represented as a query (Q), key (K), and value (V) vector.
- The attention score is calculated as a dot product between the query vector of a token and the key vectors of all other tokens in the sequence.
- The results are normalized using softmax, and the final output is a weighted sum of the value vectors, where the weights come from the attention scores.
Alright, we have already discussed that the traditional deep learning models struggled to capture long-range dependencies and contextual information effectively from the sequential data.
But other than this, have you wondered, “What is the most important requirement to build any Natural Language Processing (NLP) Application?”
I hope you guessed it right! It’s the conversion of words to numbers, called Vectorization.
Earlier the input sequence was typically represented as a set of vectors where each vector represents a token in the corpus, produced through methods like One-Hot Encoding, Bag of Words, TF-IDF, which heavily rely on word frequencies.
But these methods struggle to capture the significant meaning conveyed by the phrases such as “money bank” and “river bank” used in the same sentence, something like “She visited the money bank, near the river bank.”
To overcome this problem, we used “Word Embeddings”, which were powerful enough to capture the semantic meaning of words to find the similarity between the tokens, represented by a dimensional vector, dₘ (which can be of 512, 256, or even 64 dimensions).
But the problem with them was that they were the Static Embeddings. Meaning, these vectors are created through training on a large corpus of text and then use them in various NLP tasks. Such that they capture only the average meaning for the token, regardless of the context in which the word has appeared.
For example, the word “bank” will have the same vector whether it’s used in the context of a financial institution or the side of a river.
💡 That’s why we use “Self-Attention” Mechanism to generate sensible “Contextual Embeddings” using “Static Embeddings” as input.
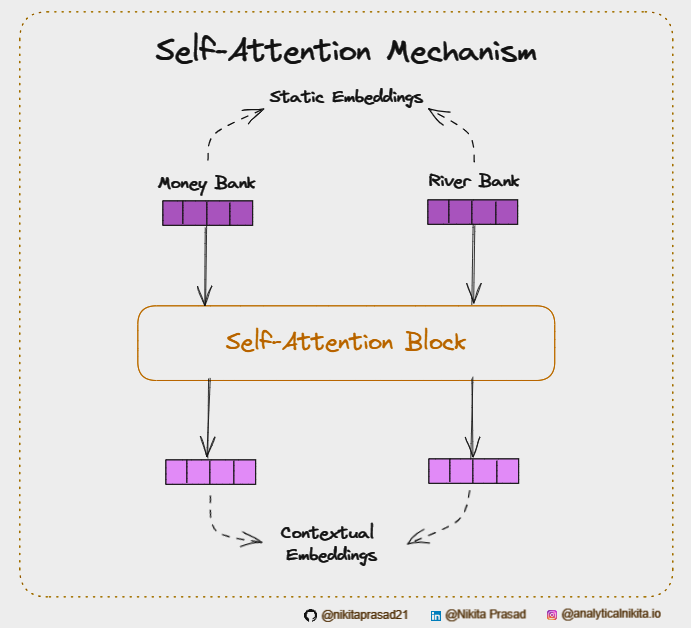
It allows dynamic understanding of context in any NLP tasks, depending on the surrounding words.
4.3.1 What’s Inside the Self-Attention Block?
The attention mechanism operates on three inputs:
- Queries (Q): This matrix is the word we’re currently focusing on.
- Keys (K): This matrix represent all the words in the document we’re comparing our query to.
- Values (V): This matrix hold the actual context for each word in the input document.
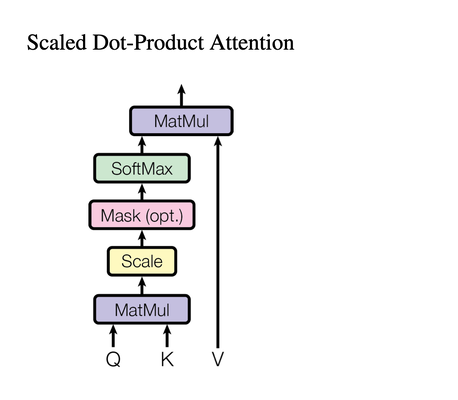
These are the important components behind the self-attention mechanism. As they allow the model to look at a word (query), then compare it to every other word (keys), and lastly, decide how much attention to give to each word (values).
So, you’ve got the gist that self-attention deals with only one type of input sequence. But what exactly does that mean? Let’s dive deeper.
4.3.2 How Does Self-Attention Work?
Let’s unpack it step by step.
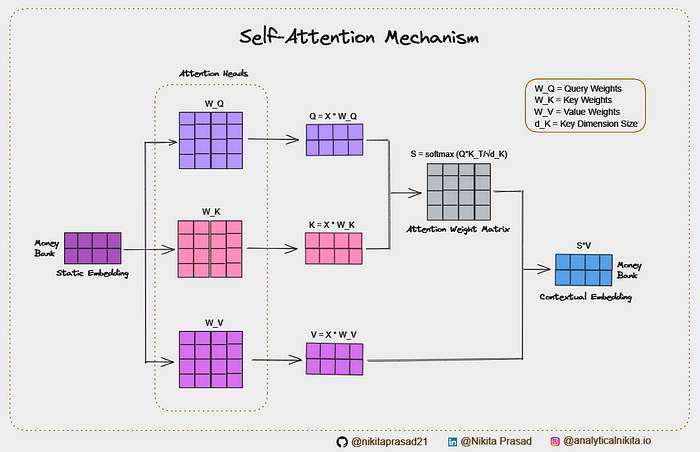
Step 1: Compute the Query, Key, and Value Matrices
First, we transform each token of our sentence into three different vectors Q, K, and V.
Query, Key and Value matrices are calculated through the matrix multiplication of an input matrix X and a weight matrix W (it’s a learnable parameter).
Step 2: Calculate Attention Scores
Next, we calculate how much each word should pay attention to every other word. This is done by taking the dot product of the Query and Key matrices.
This outputted matrix denotes the similarity (or simply the compatibility) between two input vectors.
Step 3: Scaling the Scores
(Important) While dealing with high-dimensionality matrices, the dot product leads to very large variance. This can cause instability in the model.
Here’s why:
During backpropagation, the softmax function would produce extremely large gradients, for large dot product values. This results in negligible updates of smaller dot product values during the training process, due to small gradients, leading the model towards the vanishing gradient problem.
Therefore, to mitigate this problem, the dot products are scaled by a square root of the dimensionality of Key vectors i.e., √dₖ.
This is why, it is known as Scaled-Dot Product Attention.
Step 4: Apply the Softmax Function
We then pass these scaled scores through a softmax function to normalise the values between 0 to 1.
This is to ensure that the compatibility scores follow a probability distribution, with the weights of each token summing to 1 or 100%, known as the Attention Weight Matrix.
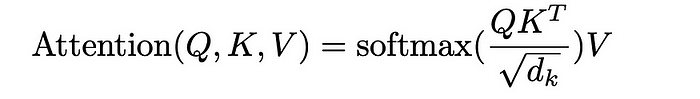
And from my past article, we know that, these probability values represent how much attention each token in the sequence should get, indicating their importance and contribution to the final context vector.
Step 5: Weight the Values
These probabilities are used to calculate the weighted multiplication with the Value matrix.
Finally, this will gives us the text specific contextual output embeddings.
Advantages:
- Self-Attention captures long-range dependencies in a sequence more effectively than RNNs and LSTMs.
- It allows parallel computation, enabling faster training.
Alright, so we’ve talked about self-attention and how it allows the model to focus on different parts of the input sequence. But what if we could do this multiple times, from different perspectives?
Consider this sentence, “The bank can be a lifesaver.”
Does this refer to a financial institution, or the side of a river?
That’s where multi-head attention comes in.
4.4 Multi-Head Attention
Introduced by: Vaswani et al. (2017) in the Transformer
Multi-Head Attention is an extension of self-attention, used in Transformer models. Instead of using a single set of attention scores, Multi-Head Attention applies several attention mechanisms in parallel, allowing the model to focus on different parts of the input sequence simultaneously.
How it Works:
- The input is linearly projected into multiple sets of queries, keys, and values.
- For each head, self-attention is applied independently, and the results are concatenated and linearly transformed to produce the final output.
- This allows the model to capture different aspects of the sequence (e.g., positional dependencies, semantic relations) in parallel.
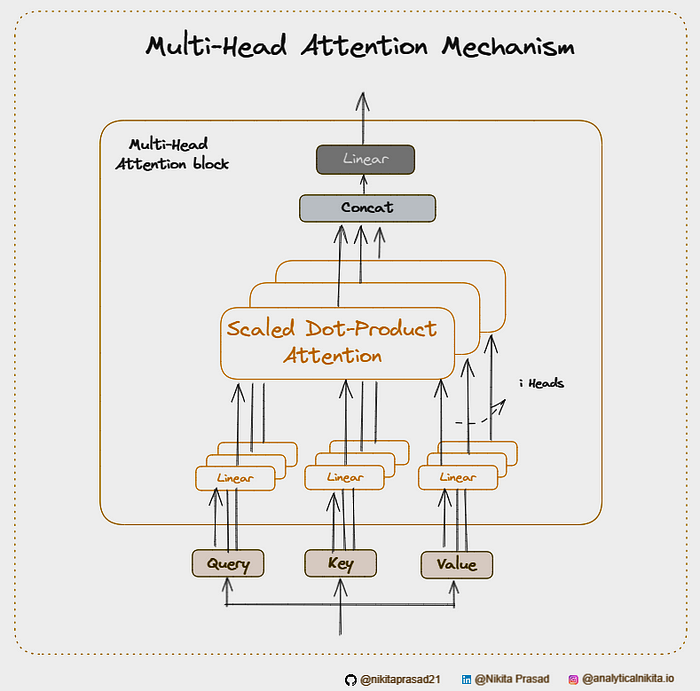
In multi-head attention, above process is repeated multiple times with different linear projections of the queries, keys, and values matrices.
Here’s it gets a bit mathematical, but stay with me:
Step 1: Linear Projections
For each head, the input sequence is linearly projected into queries, keys, and values using learned weight matrices:
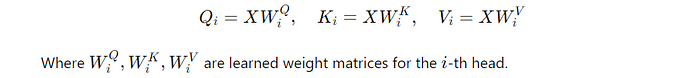
Step 2: Scaled Dot-Product Attention
Each set of queries, keys, and values matrices undergoes the scaled dot-product attention mechanism, independently:
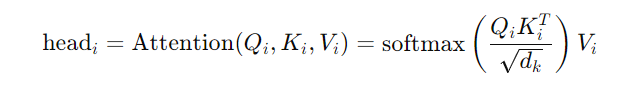
Step 3: Concatenation
Now, the outputs of all attention heads are concatenated:
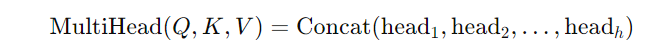
Step 4: Final Linear Projection
Lastly, the concatenated output is then projected using another learned weight matrix to produce the final output:
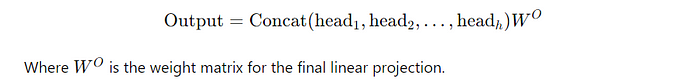
Hence, using multiple heads means that each head can focus on different parts of the input sequence simultaneously. One head might pick up on the overall structure of the sentence, while another focuses on specific details, parallelly.
When you combine all these perspectives, you’ll get a more comprehensive understanding of the input sequence (same as we human do).
Advantages:
- Multi-Head Attention enables the model to capture multiple relationships within the sequence, improving its ability to focus on different parts of the data.
- It allows better representation of complex dependencies and context.
4.5 Cross-Attention
Used in: Transformer Encoder-Decoder Architecture
Cross-Attention is a mechanism used in sequence-to-sequence models, such as in the Transformer’s encoder-decoder structure. Unlike self-attention, which works within the same input sequence, cross-attention allows the decoder to attend to the encoder’s output, making it crucial in tasks like machine translation.
How it Works:
- The decoder uses cross-attention to focus on the encoder’s output sequence (instead of its own sequence) while generating each token in the output sequence.
- The decoder generates queries from its own hidden states, and the keys and values are generated from the encoder’s output states. This enables the decoder to selectively attend to different parts of the input sentence.
While self-attention deals with a single input sequence, cross-attention involves two different input sequences.
Simply putting, that’s the only difference.
This is crucial in tasks like machine translation, where you’re dealing with a source language (like English) and a target language (like French) [1].
Cross-attention acts as the bridge between the encoder and decoder in a transformer model. Here’s how it works:
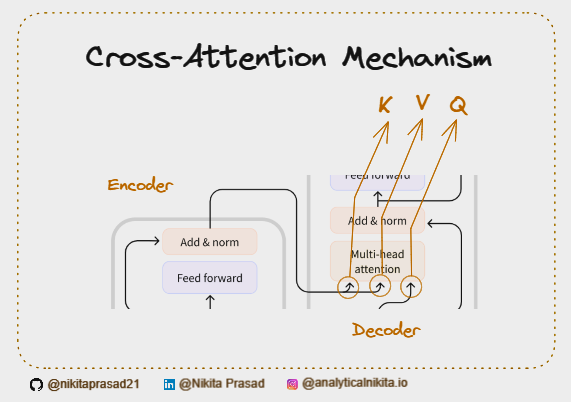
- Encoder Output: The encoder processes the source language (English) and produces a set of encoded representations.
- Decoder Input: The decoder takes the target language (French) input sequence.
- Cross-Attention: The output of the encoder (encoded representations) is used as the Key and Value in the cross-attention mechanism, while the Query comes from the previous decoder’s layer, for Multi-Head Attention.
So, why is this important?
By using cross-attention mechanism, each part of the decoder can focus on any part of the input sequence. This allows the model to learn different language conversion patterns between the two sequences, leading to more accurate and fluent translations.
So, we’ve talked about multi-head attention. But what about masked multi-head attention?
This is where things get even more interesting, especially when it comes to tasks like language modeling and text generation.
4.5.1 Masked Multi-Head Attention
It is a type of multi-head attention used primarily in the decoder part of the Transformer architecture. It’s designed to ensure that during training, the model should not “cheat” by looking at future tokens while predicting the next-token in a sequence.
How Does Masked Multi-Head Attention Work?
Alright, let’s break down, the process of ‘Masking the Future Tokens’:
In masked multi-head attention, we simply introduce a mask that prevents each token from attending to any future tokens.
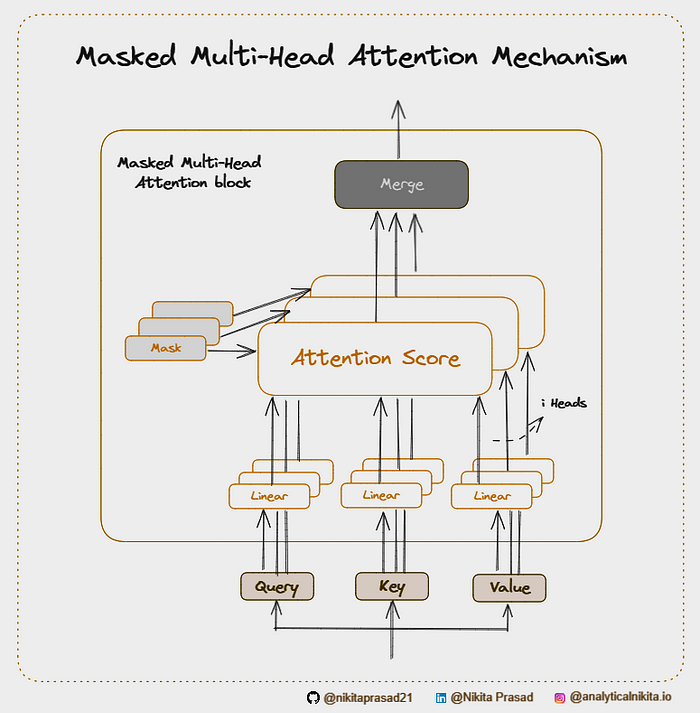
This is usually implemented by setting the attention scores of these future tokens to a very large negative number (or negative infinity) before applying the softmax function to effectively nullify their influence.
The Masked-Attention mechanism can be represented as:

Just like regular multi-head attention, masked attention can also be applied across multiple heads.
Each head operates independently, learns different aspects of the input, and then the results are concatenated and linearly projected to form the final output.
Why It Matters?
Because it allows the model to generate coherent and contextually accurate sequences (one token at a time), without peeking onto future information, to maintain the integrity of sequential data processing.
So, that’s it! Those are the 3 Types of Self-Attention Mechanisms, used in the Transformer architecture, that has revolutionized the world of NLP.
4.6 Google’s Neural Machine Translation (GNMT): Another Example
Because most of us must have used Google Translate in one way or another, it is imperative to talk about Google’s NMT, which was implemented in 2016. GNMT is a combination of the previous 2 examples we have seen.
- The encoder consists of a stack of 8 LSTMs, where the first is bidirectional (whose outputs are concatenated), and a residual connection exists between outputs from consecutive layers (starting from the 3rd layer). The decoder is a separate stack of 8 unidirectional LSTMs.
- The score function used is the additive/concat.
- Again, the input to the next decoder step is the concatenation between the output from the previous decoder time step (pink) and the context vector from the current time step (dark green).
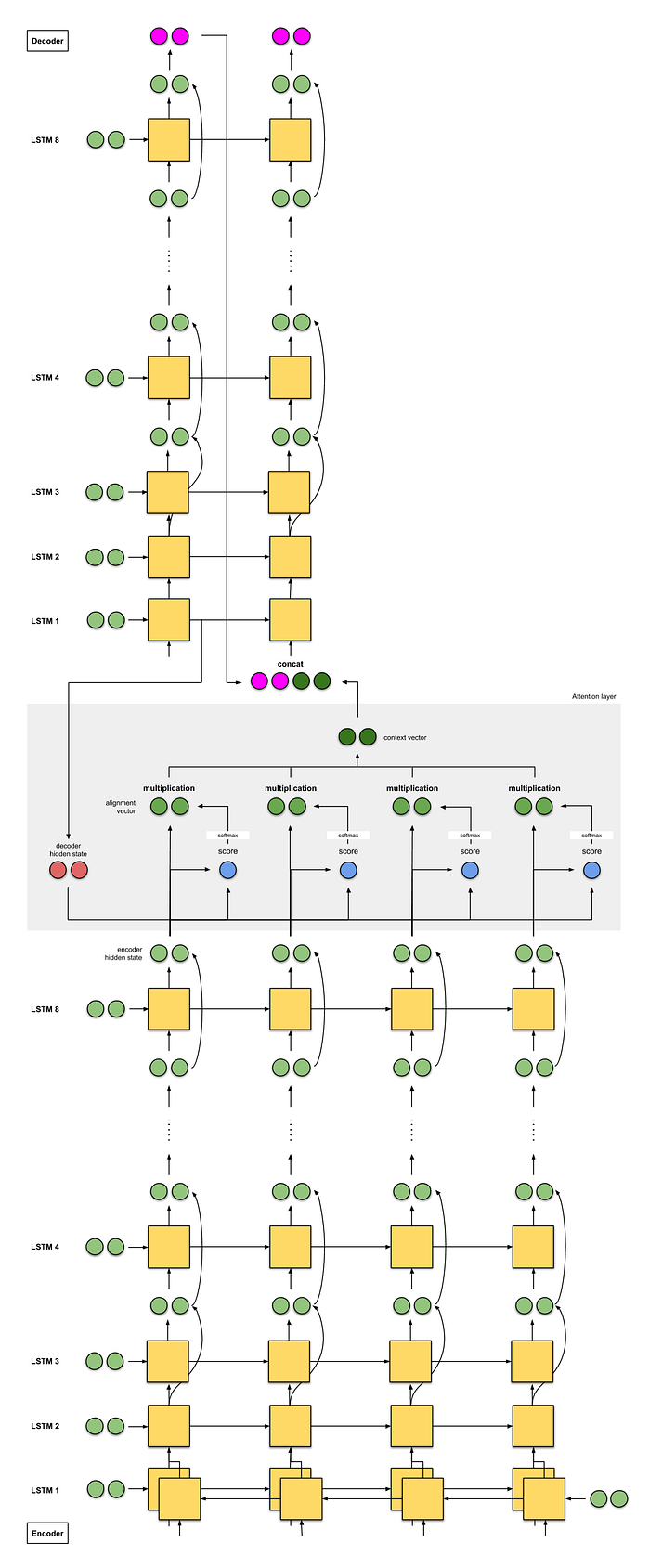
The model achieves 38.95 BLEU on WMT’14 English-to-French, and 24.17 BLEU on WMT’14 English-to-German.
Intuition: GNMT — seq2seq with 8-stacked encoder (+bidirection+residual connections) + attention
8 translators sit in a column from bottom to top, starting with Translator A, B, …, H. Every translator reads the same German text. At every word, Translator A shares his/her findings with Translator B, who will improve it and share it with Translator C — repeat this process until we reach Translator H. Also, while reading the German text, Translator H writes down the relevant keywords based on what he knows and the information he has received.
Once everyone is done reading this English text, Translator A is told to translate the first word. First, he tries to recall, then he shares his answer with Translator B, who improves the answer and shares with Translator C — repeat this until we reach Translator H. Translator H then writes the first translation word, based on the keywords he wrote and the answers he got. Repeat this until we get the translation out.
4.7 Global & Local Attention
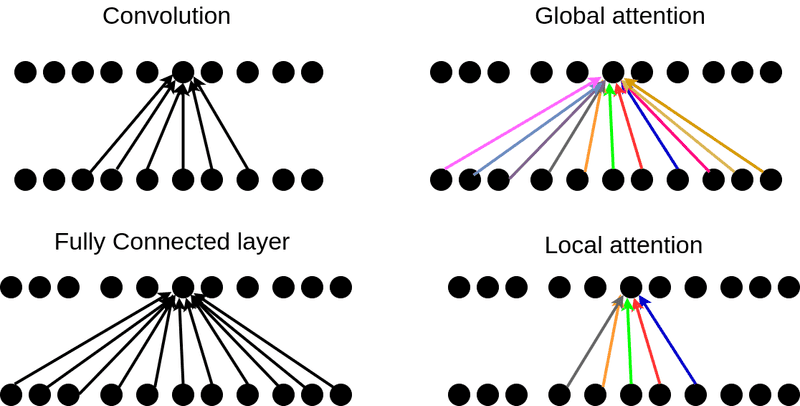
In addition to multiplicative attention, Luong et al. also introduced global and local attention in 2015 paper.
Global Attention: 1. In global attention, the model considers the entire input sequence when computing attention scores, which is useful when all parts of the input may contribute to the output.
2. This is commonly used in tasks like translation, where words or phrases from the entire sentence are relevant at different points in the output.
Local Attention: 1. In local attention, the model restricts its focus to a small, predefined window around the current token. This can be more efficient in cases where only nearby tokens are likely to influence the output.
2. It reduces computational overhead but may miss long-range dependencies.
[Xu2015]
4.8 Hard & Soft Attention
In their paper Show, Attend, and Tell], Xu et al. introduced the concepts of hard and soft attention, particularly for image captioning tasks.
Hard Attention: - Stochastic Attention: The model selects a specific region to attend to. - Pros: Reduces computational complexity by focusing only on selected regions. - Cons: Requires reinforcement learning for training, making it harder to optimize.
Soft Attention: - Deterministic Attention: Applies a weighted average over all input features. - Pros: Easier to train using standard backpropagation. - Cons: Focuses on all parts of the input, which can be less focused.
5. Attention over LSTMs
Introduced by Cheng in 2016
In the 2016 paper by Jianpeng Cheng, titled “Long Short-Term Memory-Networks for Machine Reading,” the key contribution was the use of Attention mechanisms combined with LSTM networks for machine reading tasks. Specifically, the paper introduced Attention over LSTMs to improve the performance of models in understanding and answering questions from text passages, which was crucial for tasks like machine reading comprehension.
Key Highlights from the 2016 Paper:
- Attention Mechanism in LSTMs:
- Cheng introduced an attention mechanism to allow the LSTM model to focus on different parts of a text when answering a specific question. This attention mechanism enabled the model to “attend” to more relevant words or passages dynamically, based on the input question.
- This was one of the earlier uses of attention mechanisms in combination with LSTM networks, making the model better at machine reading tasks by focusing on the most important parts of the input sequence.
2. Machine Reading Tasks:
- The paper primarily focused on tasks where a system reads a passage of text and answers questions about it. Attention helped the model locate relevant information within longer passages of text.
3. Difference from Self-Attention:
- The attention mechanism introduced here was between different parts of the input sequence and external context (e.g., the question being asked), rather than attending to different parts of the same sequence as in Self-Attention.
- The attention mechanism in this paper was more in line with the encoder-decoder attention seen in early sequence-to-sequence models, rather than the self-attention mechanism introduced later in 2017 by the Transformer.
Thus, while Cheng’s paper laid important groundwork in showing the power of attention over recurrent networks (LSTMs), it did not introduce Self-Attention, which was fully realized in Vaswani et al.’s 2017 Transformer paper.
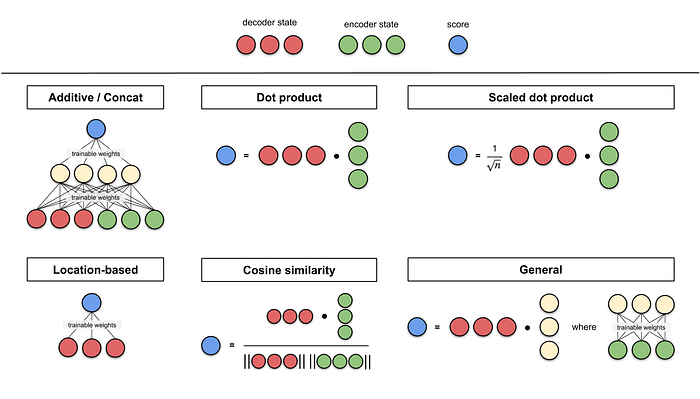
6. Score Functions
Below are some of the score functions as compiled by Lilian Weng. The score functions additive/concat and dot product have been mentioned in this article. The idea behind score functions involving the dot product operation (dot product, cosine similarity etc.), is to measure the similarity between two vectors. For feed-forward neural network score functions, the idea is to let the model learn the alignment weights together with the translation.

7. Attention Mechanism in Computer Vision
The attention mechanism, initially successful in natural language processing (NLP), has also demonstrated promising results in computer vision by helping models focus on specific regions or features in images for tasks like image classification, object detection, and semantic segmentation.
7.1 Types of Attention in Computer Vision
Spatial Attention: The model learns to focus on important regions of the image by assigning attention scores to different areas. These scores weight the features from each region, helping the model prioritize relevant parts of the image. Reference: Residual Attention Network for Image Classification by Wang et al. (2017)
Channel Attention: Focuses on selecting the most informative feature channels. Attention scores are computed for each channel in the feature map, allowing the model to prioritize important channels. Reference: Squeeze-and-Excitation Networks by Hu et al. (2017)
Self-Attention: Also known as non-local operation, self-attention computes the response at any position in the image as a weighted sum of features from all positions, allowing the model to capture global context beyond local regions handled by convolutional layers. Reference: Non-local Neural Networks by Wang et al. (2018)
7.2 Key Applications
Object Detection and Segmentation: Spatial attention helps models focus on object regions, ignoring background noise, which improves detection and segmentation accuracy. Reference: Object Detection with Deep Reinforcement Learning and Attention Mechanism” by Bellemare et al. (2016)
Image Captioning: Attention guides the model to focus on different image regions at each step of caption generation, leading to more accurate and descriptive captions. Reference: Show, Attend and Tell: Neural Image Caption Generation with Visual Attention by Xu et al. (2015)
Visual Question Answering (VQA): In VQA tasks, attention directs the model to the relevant parts of the image based on the question, improving the accuracy of the generated answers. Reference: Bottom-Up and Top-Down Attention for Visual Question Answering by Anderson et al. (2017)
Transformers in Vision: Vision Transformers (ViTs) treat images as sequences of patches, applying self-attention similar to how transformers handle tokens in NLP. This approach has been successful in several vision tasks. Reference: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” by Dosovitskiy et al. (2020)
7.3 Benefits
The attention mechanism allows computer vision models to allocate computational resources dynamically, focusing on the most important parts of the image or feature map. This results in improved performance across complex vision tasks.
8. Conclusion
The Attention Mechanism has fundamentally transformed the landscape of deep learning, particularly in handling complex tasks involving sequential data. Starting from its introduction as a solution to overcome the limitations of traditional models like RNNs and LSTMs, attention allows models to dynamically focus on the most relevant parts of the input sequence, regardless of its length or structure. This is especially crucial in tasks such as machine translation, text summarization, and image captioning, where context and relationships between elements are critical.
Throughout this blog, we explored the core idea behind the attention mechanism, breaking down its working principles, such as how compatibility scores, attention weights, and context vectors are computed. We delved into various types of attention mechanisms, from Bahdanau and Luong Attention to more advanced approaches like Self-Attention and Multi-Head Attention, which form the foundation of modern architectures like Transformers.
Attention’s versatility extends beyond text-based applications, as demonstrated by its increasing use in computer vision tasks, where it helps models focus on specific regions of an image to improve performance in tasks such as object detection and image classification.
In conclusion, attention has not only enhanced model performance by improving the handling of long-range dependencies, but it has also added interpretability and scalability to models. As the field of AI continues to evolve, attention mechanisms will likely remain at the forefront, influencing the design of new architectures and expanding the range of their applications across diverse domains.
9. Test your Knowledge!
- How would you implement a basic self-attention mechanism in PyTorch? What are the key steps and components involved?
— Expected Answer: The implementation involves computing queries, keys, and values as linear transformations of the input, followed by calculating attention scores using dot-product, applying a softmax function to normalize these scores, and then computing the weighted sum of the values. Finally, this output is passed through another linear layer.
2. Can you explain the role of positional encoding in Transformer models? How would you implement it in code?
— Expected Answer: Positional encoding provides the model with information about the position of tokens in a sequence since Transformers lack a built-in notion of order. In code, it’s often implemented using sinusoidal functions to generate a fixed representation, which is then added to the input embeddings.
3. How does the scaled dot-product attention differ from regular dot-product attention, and why is the scaling factor important?
— Expected Answer: Scaled dot-product attention includes a scaling factor (typically the square root of the dimension of the queries and keys) to prevent the dot products from growing too large and leading to small gradients during training. This scaling helps maintain stable gradients and efficient training.
4. How would you modify the architecture of a Transformer to handle very long sequences, and what trade-offs would this involve?
— Expected Answer: Techniques like sparse attention, memory-efficient attention, or segmenting the sequence and processing segments independently can be used to handle long sequences. The trade-offs typically involve balancing between model performance, computational efficiency, and memory usage.
5. Describe how you would debug a Transformer model if the attention weights seem to be focusing uniformly across all input tokens.
— Expected Answer: Possible debugging steps include checking the initialization of weights in the attention layers, ensuring the softmax function is applied correctly, validating the input data, and verifying that the model is properly learning positional encodings or handling input sequences effectively.
6. How can attention mechanisms be incorporated into existing architectures like LSTMs or CNNs, and what benefits do they provide?
— Expected Answer: In LSTMs, attention can be added to focus on specific time steps in the sequence, improving the handling of long-term dependencies. In CNNs, attention can be used to highlight important regions of an image, enhancing the model’s ability to detect objects or features. The benefits include improved performance and interpretability.
7. Can you explain the difference between global and local attention mechanisms? When would you prefer one over the other?
— Expected Answer: Global attention considers all positions in the input sequence when generating attention weights, making it suitable for tasks where the entire context is crucial. Local attention, on the other hand, restricts the focus to a subset of the input, reducing computational cost and is preferred for longer sequences where only nearby positions are relevant.
8. What is self-attention, and why is it important in Transformer models?
— Expected Answer: Self-attention allows each element in a sequence to attend to all other elements, capturing dependencies without regard to their distance in the sequence. This is crucial in Transformers for parallelization and handling long-range dependencies effectively.
9. Describe a scenario where multi-head attention is particularly beneficial.
— Expected Answer: Multi-head attention allows the model to focus on different aspects of the input simultaneously, which is beneficial in tasks like machine translation, where different parts of a sentence might correspond to different contexts or meanings in the output.
10. How does the concept of attention relate to the alignment in sequence-to-sequence models?
— Expected Answer: Attention provides a soft alignment between the input and output sequences in sequence-to-sequence models, helping the model to focus on relevant parts of the input sequence for each output token.
11. Question: When might you choose to use additive attention over dot-product attention?
— Expected Answer: Additive attention is generally used when you want more flexibility in the scoring function, especially in tasks where the relationship between the query and key vectors is not purely linear, whereas dot-product attention is computationally efficient and works well in many scenarios.
12. How does the attention mechanism help in dealing with the vanishing gradient problem in RNNs?
— Expected Answer: Attention mitigates the vanishing gradient problem by allowing direct connections between the output and relevant input states, bypassing the need to propagate information through many recurrent steps, which is a common cause of vanishing gradients.
13. Can you explain the difference between global and local attention mechanisms? When would you prefer one over the other?
— Expected Answer: Global attention considers all positions in the input sequence when generating attention weights, making it suitable for tasks where the entire context is crucial. Local attention, on the other hand, restricts the focus to a subset of the input, reducing computational cost and is preferred for longer sequences where only nearby positions are relevant.
14. What is self-attention, and why is it important in Transformer models?
— Expected Answer: Self-attention allows each element in a sequence to attend to all other elements, capturing dependencies without regard to their distance in the sequence. This is crucial in Transformers for parallelization and handling long-range dependencies effectively.
15.Describe a scenario where multi-head attention is particularly beneficial.
—Expected Answer: Multi-head attention allows the model to focus on different aspects of the input simultaneously, which is beneficial in tasks like machine translation, where different parts of a sentence might correspond to different contexts or meanings in the output.
16. How does the concept of attention relate to the alignment in sequence-to-sequence models?
— Expected Answer: Attention provides a soft alignment between the input and output sequences in sequence-to-sequence models, helping the model to focus on relevant parts of the input sequence for each output token.
17. When might you choose to use additive attention over dot-product attention?
— Expected Answer: Additive attention is generally used when you want more flexibility in the scoring function, especially in tasks where the relationship between the query and key vectors is not purely linear, whereas dot-product attention is computationally efficient and works well in many scenarios.
18. How does the attention mechanism help in dealing with the vanishing gradient problem in RNNs?
— Expected Answer: Attention mitigates the vanishing gradient problem by allowing direct connections between the output and relevant input states, bypassing the need to propagate information through many recurrent steps, which is a common cause of vanishing gradients.
19. A tokenized dictionary consisting of 10 tokens and two tokens A and B in a standard LLM model, what is the predicted probability of token B if A follows an argmax function output?
— Expected Answer: P(B|A)=1 If token A follows an argmax function output, it means that A is the most probable token in its context with a probability of 1 (100%). Consequently, if B is the next token after A in this deterministic scenario, the predicted probability of token B given A would also be 1 (100%), assuming the model always predicts B following A in this context.
20. What does the self-attention mechanism in transformer architecture allow the model to do?
— Expected Answer: The self-attention mechanism enables the model to dynamically assign different importance to each word in a sentence based on its relevance to other words in the sequence. This mechanism allows the model to capture dependencies between words, regardless of their distance in the text. It enhances the model’s ability to understand context and relationships within the text, making it more effective at tasks such as translation, summarization, and question-answering.
21.Why is self attention called “Self” ?
— Expected Answer: Self-attention is called “self” because it allows the model to focus on different parts of the input sequence by relating each element to other elements within the same sequence, rather than relying on external information. The “self” in self-attention refers to the mechanism’s ability to capture relationships and dependencies within the input sequence itself.
22. How is Self Attention similar to Bahdanau or Luong Attention?
— Expected Answer:
Similarities:
- Dynamic Weighting of Inputs: All three mechanisms dynamically calculate attention scores to focus on relevant parts of the input sequence, meaning they assign different weights to different input tokens depending on the output being generated.
- Context Vector Creation: In all mechanisms, the attention scores are used to create a weighted sum of the input tokens (referred to as a “context vector”) that influences the output at each step.
- Relevance-based Representation: The core idea behind all three is to capture the most relevant parts of the input, giving more attention to the most significant tokens and reducing noise from irrelevant ones.
Self-Attention allows each token to focus on every other token within the same sequence, enhancing long-range dependencies and parallelism.
Bahdanau and Luong Attention are used in RNN-based encoder-decoder models to align and focus on the most relevant parts of an input sequence during sequential decoding, but they operate step-by-step and are less efficient with long sequences.
9.1 DIY
- What is global attention? How would you describe a transformer model?
- What’s the difference between attention and self-attention in transformer models?
- Why do Encoders have Self-Attention and Decoders have Masked Self-Attention?
- What is the benefit of time-distributed linear layer in attention?
Credits
This blog post has compiled information from various sources, including research papers, technical blogs, official documentation, YouTube videos, and more. Each source has been appropriately credited beneath the corresponding images, with source links provided.
Below is a consolidated list of references:
- https://www.youtube.com/watch?v=o4ZVA0TuDRg&t=1s
- https://lilianweng.github.io/posts/2018-06-24-attention/
- https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3#ba24
- https://erdem.pl/2021/05/introduction-to-attention-mechanism
- https://levelup.gitconnected.com/self-attention-networks-beginners-friendly-in-depth-understanding-0f2d605a8f23
Thank you for reading!
If this guide has enhanced your understanding of Python and Machine Learning:
- Please show your support with a clap 👏 or several claps!
- Your claps help me create more valuable content for our vibrant Python or ML community.
- Feel free to share this guide with fellow Python or AI / ML enthusiasts.
- Your feedback is invaluable — it inspires and guides my future posts.



