
Introduction to Clustering
Clustering is an unsupervised learning technique that groups a set of objects such that objects in the same group (cluster) are more similar to each other than to those in other groups.
Clustering helps in understanding the structure of the data and revealing hidden patterns. It can also be used in combination with supervised learning algorithms when labeled data is scarce or expensive to obtain, in what is known as semi-supervised learning.
Cluster analysis dates back to the 1960s, where it was used as part of numerical taxonomy in biology for classification of species. Since then, it has evolved and expanded across various fields, from marketing to social network analysis, becoming a fundamental tool in pattern recognition, data analysis and interpretation.
This article provides an overview of clustering, including its types, applications, main challenges, and common algorithms.
Clustering Definition
Formally, we are given a set of n data points: {x₁, …, xₙ}, where each xᵢ is a m-dimensional vector, and we would like to partition the points into k sets (clusters) {C₁, …, Cₖ}, such that:
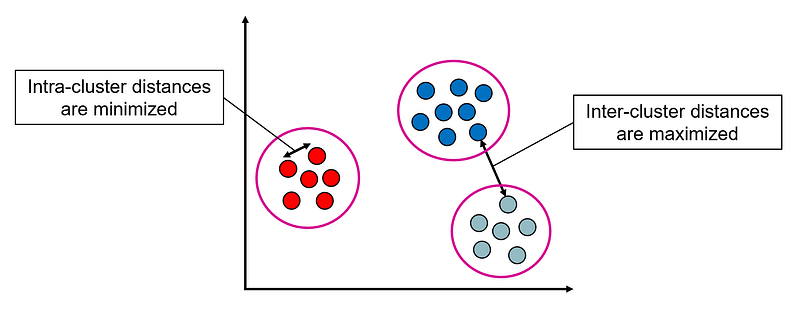
- Intra-cluster distances are minimized: data points within the same cluster are as close as possible to one another.
- Inter-cluster distances are maximized: data points in different clusters are as far as possible from one another.
The entire set of clusters {C₁, …, Cₖ} is referred to as a clustering.
Determining the ideal number of clusters or the optimal clustering is often subjective, or as the saying goes “clustering is in the eye of the beholder”. For example, one can argue that the following dataset consists of two, four, or even six clusters:
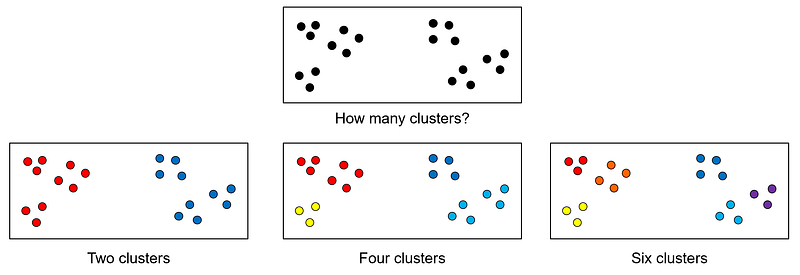
The lack of a precise definition of clusters as well as the computational difficulties in finding an optimal grouping give rise to many different approaches to cluster analysis, which are discussed in the next section.
Types of Clustering
Clustering methods can be categorized into various types based on their approach for identifying clusters and their underlying clustering model. Each type is suitable for different kinds of datasets and applications. The main types of clustering include:
- Partitioning clustering: Divides the dataset into a set of non-overlapping clusters in a way that optimizes a certain criterion, such as minimizing the distances between points within clusters. Examples for partitioning clustering techniques include k-means and k-medoids (PAM).
- Hierarchical clustering: Constructs a hierarchy of clusters, represented as a tree-like structure called dendrogram. Hierarchical clustering can be implemented as agglomerative (bottom-up) or divisive (top-down).
- Density-based clustering: Defines clusters as dense regions of points separated by regions of lower density. DBSCAN is a prime example for a density-based clustering.
- Model-based clustering: Assumes that the data points in each cluster are generated by a statistical model, and fits the data to these models. A prominent example of model-based clustering is Gaussian Mixture Models (GMM), where each cluster is modeled as a Gaussian distribution, and the entire dataset is considered as a mixture of these distributions.
- Graph-based clustering: Treats the data as a graph, where data points are nodes, and edges represent similarities between these points. Spectral clustering is an example for a graph-based clustering method.
- Grid-based clustering: Divides the data space into a finite number of cells that form a grid structure, and clustering is performed on this grid instead of the data points themselves. Examples for grid-based algorithms include CLIQUE and STING.
In addition, we distinguish between hard and soft clustering:
- Hard clustering: Each data point is assigned to exactly one cluster. In this case, there are distinct boundaries between clusters, with no overlapping. The k-means algorithm is a classical example of a hard clustering algorithm.
- Soft (or fuzzy) clustering: Each data point can belong to multiple clusters with varying degrees of membership or probability. In this case, clusters can overlap, and a single point can be shared across multiple clusters. GMM is an example for a soft clustering algorithm.
Challenges in Clustering
Clustering algorithms face several challenges that can affect the quality and effectiveness of the clustering results:
- Determining the number of clusters: Many clustering algorithms, such as k-means, require specifying the number of clusters in advance, which is not always apparent and may require iterative experimentation.
- Varying cluster shapes and sizes: Clusters can vary greatly in their shape, density or size, and not all algorithms handle these variations well.
- Scalability: Handling large datasets efficiently is a challenge for many clustering algorithms, whose runtime and memory requirements may not scale well with the increase in dataset size.
- Handling high-dimensional data: Clustering algorithms typically rely on measuring distances between points to form clusters. In high-dimensional datasets, the data becomes sparse and distances between points become increasingly uniform and less informative (a phenomenon known as the curse of dimensionality).
- Sensitivity to noise and outliers: The presence of noise and outliers can significantly affect the clustering results, leading to incorrect clusters or misclassified data points.
- Hyperparameter tuning: Many clustering algorithms have parameters that need to be fine-tuned for optimal performance.
- Interpretation and validation: The interpretation of clusters can be subjective and may vary depending on the perspective of the domain expert. Clustering evaluation involves various methods and metrics that measure how well the data points have been grouped into clusters. Evaluation of the clustering results can be as hard as the clustering itself.
- Ethical and privacy concerns: Clustering algorithms may unintentionally reflect biases in the input data. In addition, they may raise privacy concerns, especially in applications involving sensitive personal data, such as customer segmentation and medical data analysis.
Clustering Applications
Clustering has a wide range of applications in diverse areas such as:
- Market research and customer segmentation: Identify customer groups based on purchasing patterns and preferences for targeted marketing and personalized service offerings.
- Social network analysis: Detecting communities and understanding social dynamics.
- Biological data analysis: Grouping genes or proteins with similar functionalities.
- Finance: Grouping stocks into sectors based on various financial metrics and market behaviors.
- Urban planning: Clustering helps in urban planning by grouping areas with similar land use or demographic characteristics.
- Information retrieval: Grouping similar documents to facilitate efficient retrieval of relevant information based on user queries or interests.
- Web search: Search engines use clustering to group similar results, enhancing user experience by providing categorized information.
- Image segmentation: Segmenting images into meaningful clusters, such as separating objects from the background or identifying similar features in images.
- Recommender systems: Recommending products or content by grouping similar users based on their preferences or past behavior.
- Anomaly detection: Clustering can be used to detect unusual patterns or anomalies in areas such as fraud detection and network monitoring.
Thanks for reading!
Feel free to to check out my other articles on clustering for more insights and in-depth discussions:




