
How I Reduced My Query’s Run Time From 30 Min. To 30 Sec. In 1 Hour
The query optimization steps a senior data engineer took to reduce the process time of a query processing 1 billion+ rows.


Despite the terrifying prospect of increasingly sophisticated cyberattacks, one of the quickest ways to break data infrastructure isn’t at all malicious. All you have to do is introduce your ingestion process to something new, typically in a table’s schema.
A new type. A new field. Or, a field disappearing altogether.
The following query optimization case doesn’t begin with frantic Slack messages signaling a crippled pipeline. It isn’t a response to a carelessly added field upstream. It simply starts with a request fellow data engineers get weekly: “Can you add this new field?”
Since this use case was inspired by work, I can’t provide details about the specific data and request. I can tell you, however, that this was a string field that served as a supplemental id. Prior to adding this field, the view I had previously created would execute in less than 15 seconds since it was processing a very small (less than 10,000 rows) amount of data daily.
This quickly increased to 30 minutes.
Below, is a representation of the jump in (approximate) slot hours consumed.
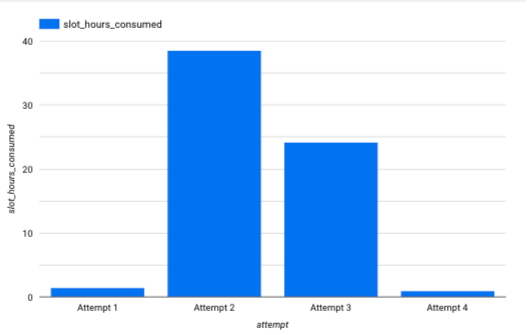
The view was originally comprised of data that lived in 4 source tables. They had a common key that tied them together, which means I was able to create the original view quickly and accurately. I assumed (wrongly) that bringing in the new field would be a quick task. And, on paper, it was.
It’s just 3 new lines:
- A field in the outermost query
- A new table reference
- A new JOIN clause (with key)
-- Pseudo code representation
SELECT *, new_field
FROM (
SELECT
...
-- New row added here
table_5.new_field
FROM table_1
LEFT JOIN table_2 ON table_2.a_id = table_1.a_id
LEFT JOIN table_3 ON table_3.a_id = table_1.a_id
LEFT JOIN table_4 ON table_4.a_id = table_1.a_id
-- New table alias added here
LEFT JOIN table_5 ON table_5.a_id = table_1.a_id
)
GROUP BY ...
-- Adding field to the existing GROUP BY clause
new_field
Unfortunately, this source table was not small. Unlike the other tables that appended a small amount of data daily, this table represented a larger export, somewhere in the neighborhood of 5 mil. rows per day. Depending on your experience with “big” data, you might still consider this small. But let me emphasize that we’re appending that number of rows daily. Historically, there are over 1 billion rows stored. This still isn’t huge in the world of big data, but it can really slow processing when you’re trying to join more than 3 tables, like I was.
Before, I got away with a standard query with a few subqueries, 2-3 layers deep, wrapped in a final SELECT clause, like you see in the pseudo code above.
Once I saw the initial runtime approaching 30 min., I started thinking about taking those query optimization steps everyone from Learning SQL to StackOverflow suggests.
But I’m stubborn so I convinced myself I could keep my original query structure and parameters and just create materialized views for everything I was trying to query. Unfortunately, this quickly became messy because I’d have to conceptualize and then submit code changes for the process that generates the rest of the tables.
I got frustrated pretty quickly and started tweaking the “meat” of the query, alias-ing all my tables and even trying different JOIN types. Tweaking a query with multiple sub queries was getting as messy as my hastily-conceived materialized view strategy, so I took my first refactoring step: Converting my sub queries to CTEs.
-- Pseudo code representation of refactoring
WITH table_1 AS (
SELECT * FROM table_1
),
table_2 AS (
SELECT * FROM table_2
),
table_3 AS (
SELECT * FROM table_3
),
table_4 AS (
SELECT * FROM table_4
),
table_5 AS (
SELECT new_field FROM table_5
)
SELECT
...
FROM
table_1 LEFT JOIN table_2 ON table_1.a_id = table_2.a_id
LEFT JOIN table_3 ON table_1.a_id = table_3.a_id
LEFT JOIN table_4 ON table_1.a_id = table_4.a_id
LEFT JOIN table_5 ON table_1.a_id = table_5.a_id
GROUP BY
...And guess what?
It didn’t help at all.
I mean, it helped with legibility for sure, but not performance. This was annoying because re-writing your query as a CTE is supposed to decrease execution time automatically, right?
While the CTE can help alleviate some of the initial processing load, my problem was still the scope of data I needed to join against. I needed to join multiple smaller tables against a comparably massive data source.
So, instead of making more code changes, I took perhaps the most important query optimization step: I thought about my underlying data. I considered its inherent scope and its relationship to my other data.
As I mentally pieced together the relationships, I realized that there was a lot of redundancy in my process.
- Even though we appended to table 1, it was essentially a mapping table that did not need to be referenced in its entirety
- Tables 2–4 also only appended a small amount of records day-over-day
- Due to the nature of the export, the field in table 5 wouldn’t change day-over-day so there was no reason to pull EVERYTHING
All of this thought led to one critical realization: For any of these tables, I only needed the most recent day’s data. So I used a date filter for each:
-- Pseudo code representation of refactoring
WITH table_1 AS (
SELECT * FROM table_1
WHERE DATE(update_date) = CURRENT_DATE()
),
table_2 AS (
SELECT * FROM table_2
WHERE DATE(update_date) = CURRENT_DATE()
),
table_3 AS (
SELECT * FROM table_3
WHERE DATE(update_date) = CURRENT_DATE()
),
table_4 AS (
SELECT * FROM table_4
WHERE DATE(update_date) = CURRENT_DATE()
),
table_5 AS (
SELECT new_field FROM table_5
WHERE DATE(update_date) = CURRENT_DATE()
)
SELECT
...
FROM
table_1 LEFT JOIN table_2 ON table_1.a_id = table_2.a_id
LEFT JOIN table_3 ON table_1.a_id = table_3.a_id
LEFT JOIN table_4 ON table_1.a_id = table_4.a_id
LEFT JOIN table_5 ON table_1.a_id = table_5.a_id
GROUP BY
...And execution time dropped back down to seconds (see attempt 4).
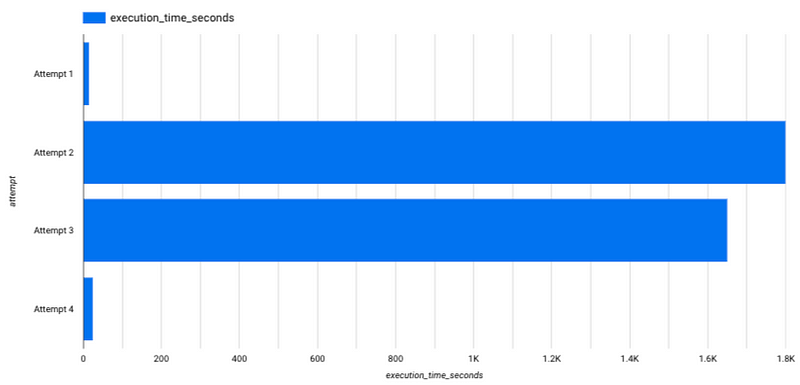
But there was one lingering problem. While I was getting most of the rows I expected in the final output (less than 50 distinct records), my view was omitting some important data and, consequently, underreporting. I initially started troubleshooting within the view definition but, even with the CTEs, this proved illegible and difficult.
Instead, I opened a separate tab with just the two tables I wanted to join. After a few minutes of experimentation, I found that it wasn’t the data or even the join key. My issue was the order of the table aliases in the JOIN clause. I explain a similar issue here.
**Remember that it’s a best practice to put the larger table on the left side of your join.
With that final issue resolved, I regained my confidence in both the performance and, now, accuracy of the data.
Too often, I’ve seen query optimization tips presented in abstract. It’s easy to say (or write) “Convert your query to a CTE” or “Avoid CROSS JOIN.” But, as I hope I’ve demonstrated, just blindly trying one of these tricks is not a catch-all solution to optimization issues.
Really, the best query optimization approach is minimalism. Ask yourself: What is the minimal amount of rows I can process so this data will be timely and accurate?
Don’t overthink it.
And definitely don’t over-process.
Create a job-worthy data portfolio. Learn how with my free project guide.





