
Google’s MusicLM: from text description to music
A new model is generating impressive music from just text prompt

Google has released a new model capable of generating music from a textual description. The result? impressive.
Actually, the idea of applying generative AI to music is not a new concept. There have been several attempts in recent years, including Riffusion, Dance Diffusion, Microsoft’s Museformer, and OpenAI’s Jukebox. Google itself had previously released a model called AudioML. Why would this model be different?
Why is hard to generate music with AI?

Meanwhile, previous models showed obvious technical and quality problems. The result was stale, the songs were not very complex, often repetitive, and still not high-fidelity.
Generating music is not easy, as numerous attempts have shown. Authors often use MIDIs, but generating high-fidelity music is another matter. Music also has a complex structure, you have to consider melodies and harmonies, and there are patterns that repeat over time and over a long distance.
As the authors of the article point out, it is easier to generate text-to-image, and text-to-music was attempted for: “simple acoustic scenes, consisting of few acoustic events over a period of seconds.”
Here we are talking about starting with a single text caption and generating complex audio with a long-term structure. How did they accomplish this?
Meanwhile, as they explain AudioLM was used as a starting point. The previous model was able to take a melody and continue it in a coherent way. Nevertheless, there are several technical limitations to overcome:
- The first main limitation of such a model is the “scarcity of paired audio-text data.” In fact, text-to-image training was facilitated by the fact that there are so many images, and alt text can be used as captions.
- It is not easy to be able to describe in a few words the salient features of music such as acoustic scenes or the timbre of a melody.
- Also, the music unfolds on a temporal dimension, so there is a risk of a weak link between the caption and the music (in contrast, an image is static).
MusicLM: structure, training, results and limitations

The first component of this model is MuLan (and also the core part). This model is used to construct a music-text joint embedding and consists of two embedding towers (one for textual input and one for musical input. The two towers are pre-trained BERT and a variant of ResNeT-50 for audio.
MuLan was trained on pairs of music clips and their corresponding textual annotations.
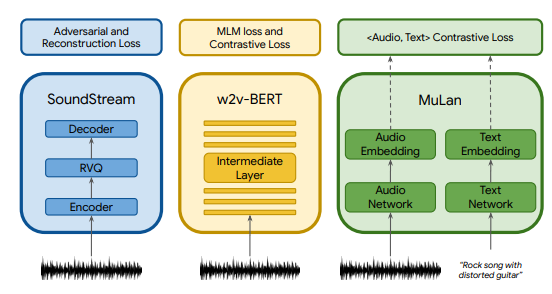
As we saw in the image the authors there are two other components. As the authors explain:
We use the self-supervised audio representations of SoundStream as acoustic tokens to enable high-fidelity synthesis, and w2vBERT , as semantic tokens to facilitate long-term coherent generation. For representing the conditioning, we rely on the MuLan music embedding during training and the MuLan text embedding at inference time.
As complicated as, this system may seem, it allows several advantages: it can scale quickly, and the use of contrastive loss for embedding training increases robustness. In addition, having pre-trained models separately allows for better conditioning of music with textual input.
During training, the model learns to convert the token mapping produced by MuLan to semantic tokens (w2w-BERT). Then the acoustic token is conditioned on both the MuLan audio tokens and the semantic tokens (SoundStream).
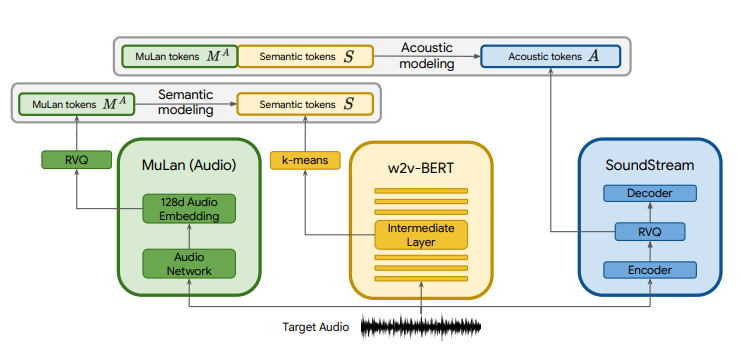
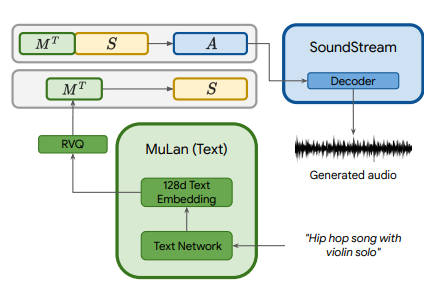
During inference the process is to provide a textual description to MuLAn which transforms it into conditional signaling, this in turn is transformed into an audio token by w2w-BERT and then transformed into waveforms by the SoundStream decoder.
What also makes MusicLM so capable is that it has been trained on 5 million audio clips (a total of 280,000 hours of audio). In addition, the authors have created a dataset of 5.5 thousand music clips with captions written by professional musicians (this dataset has been released here). Each of these captions describes the music with four sentences and is followed by a list of music aspects (genre, mood, rhythm, etc.)
As the results show, MusicML proves to be superior to previous models (Mubert and Riffusion), both in terms of audio quality and text faithfulness. Moreover, in terms of listening quality as well. In fact, listeners were shown clips and asked to choose which clip best represented the textual description (a win means that the listener preferred the model in a side-by-side comparison)
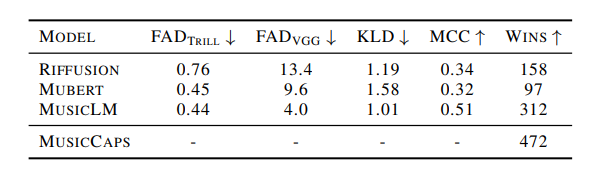
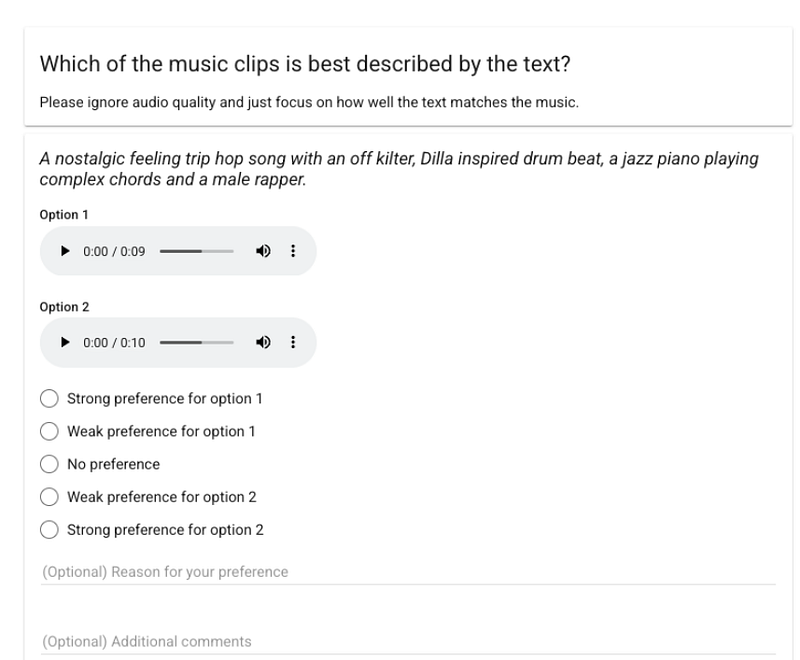
Listening to the results, it is hard not to be impressed, considering that there are no musicians in the loop. After all, the model manages to capture musical nuances such as instrumental riffs and melodies.
Moreover, the model is not limited to textual descriptions but can take other audio as input and continue them (“which is provided in the form of humming, singing, whistling, or playing an instrument”).
The authors also describe an approach called “story mode”, which is to generate long audio sequences where the textual description changes over time. The model generates musical sequences with “smooth transitions which are tempo consistent and semantically plausible while changing music context according to the text description.” These descriptions can also contain descriptions com “time to meditate” or “time to run” creating a narrative in which appropriate music is associated.
The model in short is not limited to the description of an instrument or genre but can be conditioned with descriptions that are inspired by activities, epochs, places, or moods. MusicLM could therefore also be used for movie soundtracks, workout apps, etc.
At this link, you can also read the captions and listen to the model result.
Though impressive the model is not perfect, and some of the audio clips have a distorted quality (but this could be improved in the future with training modifications). In addition, the model can also generate choirs and people singing, but often the lyrics are not even in English but in a kind of gibberish and the voice sounds more like an amalgam of singers than a coherent human voice. Thus, how the authors state:
Future work may focus on lyrics generation, along with improvement of text conditioning and vocal quality. Another aspect is the modeling of high-level song structure like introduction, verse, and chorus. Modeling the music at a higher sample rate is an additional goal.
Google decided not to distribute the model: “there are several risks associated with our model and the use-case it tackles.” As the authors note, the model reflects the biases that are present within the training data, posing problems for generating music for cultures that are underrepresented within the dataset. They also point out that the model raises ethical questions about cultural appropriation.
Another problem is that in 1% of cases, the model generates music that it has heard during training, replicating parts of existing songs (even elements that are copyrighted). TechCrunch suggests that this is enough to discourage Google from releasing the model (especially now that institutions are interested in regulating AI and generative tools).
They acknowledge the risk of potential misappropriation of creative content linked with the use case and further highlight the necessity of deep studies and analysis, concluding:
We strongly emphasize the need for more future work in tackling these risks associated to music generation — we have no plans to release models at this point
Conclusions
MusicLM is impressive in its ability to generate music from the textual description, a quantum leap compared to previous models. It generates coherent music, long sequences capable of capturing music nuances. Although it has been trained with an impressive amount of data, it is still not perfect.
Also, as described by the authors since the model produces copyrighted music they have no plans to release it. This is probably also derived from the fact that some programmers recently have sued GitHub Copilot and Getty images filed lawsuits against Stability AI and MidJourney.
Moreover, as noted by the authors, generative music models are incorporating bias from the training set. MusicLM is not only generating instrumental music but can also generate vocals and chorus, which can lead to incorporating bias and harmful content in the generated music.
In addition, as noted by several musicians, streaming has thinned the earnings of musicians and composers, and generative AI could reduce their income still further.
Instead, the authors suggest that rather than replacing musicians and composers these models will soon be a set of tools to assist humans.
if you have found it interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. Thanks for your support!
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.





