
Microsoft’s Museformer: AI music is the new frontier
AI art is exploding, music can be next.

Transformers have revolutionized natural language processing. In recent months, however, we have seen how AI has been applied to art and image generation. A few days ago, Microsoft announced Museformer, a model for music generation.
Music can be represented as an organized and discrete sequence of tokens (after all, music consists of a series of sounds in sequence). Transformers have been shown to be efficient in text generation, and in other words, transformers can be said to do nothing more than generate a sequence of text. The success of the Transformer lies in the fact that the self-attention mechanism allows long dependencies to be captured in a text. To model music, we need to be able to capture long dependencies and the correlation between various parts of the musical sequence. This lays the foundation for using a transformer to generate music.

Of course, it is not that easy:
- Long sequence modeling: musical sequences are very long (especially when there are several instruments). This is a problem because the attention mechanism has quadratic complexity and thus the computational cost becomes exponentially higher.
- Music structure modeling: music has its own unique structure, there are definite patterns that are repeated and can have variations. These patterns recur sometimes long distances in the sequence, making it more complicated.
This is not the first time that attempts have been made to handle long sequences with transformers. There are two approaches that have been used primarily:
- Local focusing, as in the case of Transformer XL and Longformer, where basically the focus is only on part of the input sequence and the rest is dropped. In the case, of music, the retained sequence may not contain the important part of the musical structure.
- global approximation, used by Linear Transformer where there is a sequence compression, although this compression reduces complexity, it does not capture the correlation between the various parts of a musical sequence.
The insight of this paper, and that although these two approaches are inadequate one can take the best of the two. Indeed, not all parts of a musical sequence are important (and this information is not evenly distributed). So we need to safeguard and focus on these parts, and when generating music we focus on the important repetitions. The rest, those less important passages can be approximated. So the idea, in summary, is to focus on the important parts but reduce the complexity and computational computation.
This mechanism is put into practice by a mechanism called fine and coarse-grained attention (FC-Attention) that replaces the classical self-attention module:
The general idea is that we do not need to focus on the whole sequence with the same importance level given that the complexity of pair-wise full attention is unacceptably high, but instead we combine two different attention schemes — fine-grained attention for the structure-related bars, and coarse-grained attention for the other bars.
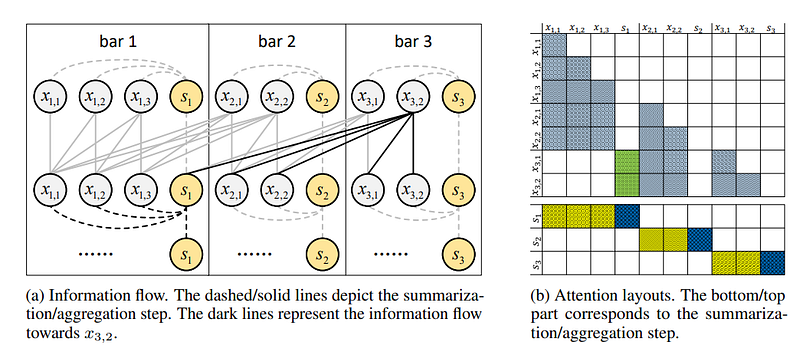
In other words, there are two steps: summarization, and aggregation. The first step reduces the complexity and creates a kind of “summary token” for part of the sequence, and then the information is subsequently aggregated (as in classical attention this allows contextualization of the information):
The basic idea of FC-Attention is that, instead of directly attending to all the tokens which causes the quadratic complexity, a token of a specific bar only directly attends to the structure-related bars that are essential for generating structured music (fine-grained attention), and for the other bars, the token only attends to their summary tokens to obtain concentrated information (coarse-grained attention). To achieve this, we first summarize the local information of each bar through the summarization step, and then aggregate the fine-grained and coarse-grained information through the aggregation step.
These bars simply represent part of the sequence. The last important step is to figure out which ones represent the important information and are likely to be repeated in the musical sequence. For this, the authors used simple summary statistics by calculating the similarity between two different bars along the entire sequence.
They applied the same approach to analyze different styles, finding that some patterns are repeated across different genres and styles:
We further conduct the similarity statistics on different datasets involving music of various genres and styles. The results shown in Appendix A interestingly indicate that this pattern is universally applicable to the music of the great diversity. We believe that it can be regarded as a general rule applicable to most music in our daily life.
The authors state that this structure allows the model to comply with music characteristics and cover the structure-related information (both short-term and long-term). In addition, the model preserves information as opposed to models that use sparse attention to reduce complexity (this leads to losing a large amount of information).

The authors used to train the model the Lakh MIDI (LMD) dataset, which contains multi-instrument music in the format of MIDI (in total they used nearly thirty thousand songs or 1,700 hours of songs, which contain several instruments).
The model includes 4 layers with hidden size 512, 8 attention heads, and a feed-forward layer of size 2,048. To evaluate it in addition to using perplexity and similarity error, they invited 10 people (including seven with musical backgrounds) to evaluate 100 randomly generated music pieces. People had to evaluate according to several criteria: musicality (whether the piece was pleasant and interesting), Short-term structure, Long-term structure, and overall.
They also compared their model with other previous models showing that their model was superior:
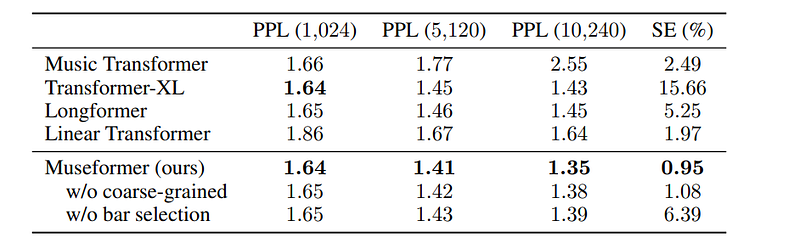
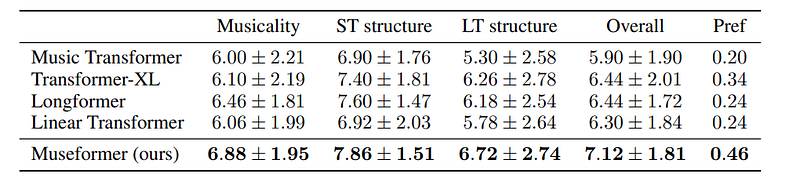
Although the model manages to generate music with good quality and structure, it is still far from perfect.
First, since Museformer takes random samplings during inference and does not receive manual control, it can hardly ensure that every generated music piece is well-structured in an expected way. Techniques to enhance its reliability and controllability can be further explored. Furthermore, the musicality and creativity of the generated music are still far behind that of human-made music, which remains a problem for all the existing music generation models.
Here you can listen to some of the musical examples that have been created:
In addition, Museformer is part of a larger project by Microsoft. the project called Muzic (GitHub repository here).

The project aims to understand music (recognize, find, transcribe) and then at a later time generate it. There are already several projects in the repository that can also be tested.
Microsoft is not the only one engaging in projects dedicated to music. In fact, a few days ago Google also produced its own model that can continue a song or speech between people. Will what happened with AI art happen with music? what do you think?
If you have found it interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. Thanks for your support!
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
Or feel free to check out some of my other articles on Medium:





