
Google launches Powerful Data Science Functions for BigQuery
How you can now use more advanced Mathematical Functions in BigQuery
Google just launched very useful functions which you can use for various mathematical and statistical Data Science cases.
Just last week Google already announced the availability of more advanced text analysis functions in BigQuery and BigQuery ML with that you can realize Tokenization and Bag of Word with SQL. Now they also launched new mathematical functions — namely[1]:
you can use these distances in various fields such as Machine Learning, data analysis, and natural language processing. Each metric serves a different purpose and is suitable for specific types of data — here a small what is what and how to use them[2][3][4][5]:
Cosine Distance
The cosine distance measures the cosine of the angle between two vectors in a multidimensional space. It is often used to compare the similarity between two vectors. Use Cases: Cosine distance is commonly used in natural language processing (NLP) tasks, such as text similarity and document clustering. It is particularly useful when the magnitude of the vectors is not important, and the focus is on the orientation of the vectors.
Euclidean Distance
The euclidean distance is the straight-line distance between two points in Euclidean space. In other words, it measures the length of the shortest path between two points. Use Cases: Euclidean distance is a general-purpose distance metric and is widely used in various applications, including clustering, classification, and regression. It is suitable for scenarios where the absolute magnitude of the vectors is significant, and the spatial relationship between data points matters.
Edit Distance or Levenshtein Distance
The Edit or Levenshtein distance measures the minimum number of single-character edits (insertions, deletions, or substitutions) required to transform one string into another. Use Cases: Edit distance is commonly used in applications related to string similarity and spell checking. It is suitable for scenarios where the similarity between sequences of characters needs to be assessed, such as in DNA sequence analysis, spell correction, or comparing words.
Example in BigQuery
So now from the theory back to a practical example with BigQuery SQL. In this example Iwill use the Euclidean Distance. But is had to be said that they work pretty similar to each other — please also use the links below to dive deeper.
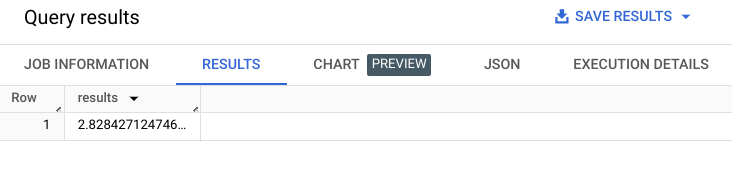
SELECT EUCLIDEAN_DISTANCE(
[(1, 1.0), (2, 2.0)],
[(2, 4.0), (1, 3.0)])
AS results;Which will provide:
Summary
These new mathematical functions are very powerful and often used in Data Science use cases, so a pretty awesome update for all Data Scientists and Analysts who work with BigQuery. Google follows here the path of bringing more and more statistical and Machine Learning capabilities to it’s Data Warehouse BigQuery and using only SQL. Other lately updates for BigQuery:
Sources and Further Readings
[1] Google, BigQuery release notes (2023)
[2] Asking ChatGPT about Cosine, Euclidean and Edit Distance (2023)
[3] Google, COSINE_DISTANCE (2023)
[4] Google, EUCLIDEAN_DISTANCE (2023)
[5] Google, EDIT_DISTANCE (2023)




