Google launched Bag of Word for BigQuery & BigQuery ML
How you can now do Text Analysis easily

A few days ago, I had written about how Google now offers the possibility to use Tokenization and Bag of Word within BigQuery. Corresponding to that, they have now also added functions to BigQuery ML.
When working with BigQuery, you can now use the function of Tokenization and Bag of Words — the latter was also added for BigQuery ML[1].
A tokenized document is something that is pictured as a collection of words (tokens) which is utilized for text analysis. You can make use of tokenized documents to recognize complex tokens in text, such as web addresses, emoticons, emojis, and hashtags[2]. In the next step, you can create a Bag of Words model which is a technique used in natural language processing (NLP) to represent text data as a set of numerical features.
So Google added the Bag of Word functionality in BigQuery and BigQuery ML. In BigQuery ML, you can use the ML.BAG_OF_WORDS function to compute a representation of tokenized documents as the bag (multiset) of its words, disregarding word ordering and grammar. You can use ML.BAG_OF_WORDS within the TRANSFORMclause[3].
ML.BAG_OF_WORDStakes the following arguments:
tokenized_document:ARRAY<STRING>value that represents a document that has been tokenized. A tokenized document is a collection of terms (tokens), which are used for text analysis. For more information about tokenization in BigQuery, seeTEXT_ANALYZE.
top_k: Optional argument. Takes anINT64value, which represents the size of the dictionary, excluding the unknown term. Thetop_kterms that appear in the most documents are added to the dictionary until this threshold is met. For example, if this value is20, the top 20 unique terms that appear in the most documents are added and then no additional terms are added.
frequency_threshold: Optional argument. Takes anINT64value that represents the minimum number of documents a term must appear in to be included in the dictionary. For example, if this value is3, a term must appear at least three times in the tokenized document to be added to the dictionary.
Terms are added to a dictionary of terms if they satisfy the criteria for
top_kandfrequency_threshold, otherwise they are considered the unknown term. The unknown term is always the first term in the dictionary and represented as0. The rest of the dictionary is ordered alphabetically.
Here’s a little example:
WITH Example AS (
SELECT 1 AS id, [‘a’, ‘b’, ‘d’, ‘c’] AS f
UNION ALL
SELECT 2 AS id, [‘a’, ‘d’] AS f
)
SELECT ML.BAG_OF_WORDS(f, 32, 1) OVER() AS results
FROM Example
ORDER BY id;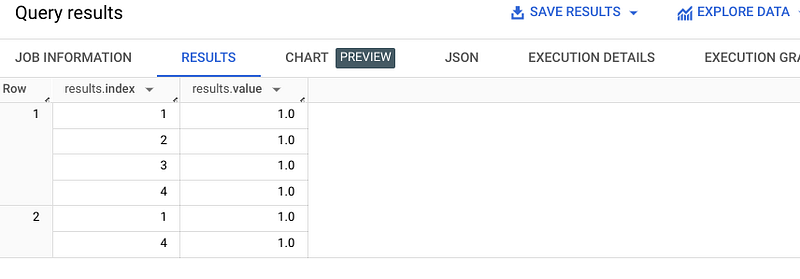
So after adding the functionality of Tokenization and Bag of Word to BigQuery, they now also included this into BigQuery ML. This makes sense, since from here on, you can use the BigQuery ML feature for Machine Learning tasks that are working with text. So a very useful update which enables Data Scientists to realize such use cases by only using SQL.
Sources and Further Readings
[1] Google, BigQuery release notes (2023)
[2] MathWorks, tokenizedDocument (2023)
[3] Google, The ML.BAG_OF_WORDS function (2023)