
Feature selection techniques for data
Heuristic and Evolutionary feature selection techniques
“Data Literacy includes the ability to read, work with, analyze, and argue with data”-(Jordan Morrow, Qlik)Data Literacy
The meaning of feature selection is to select the most informative feature from the dataset. When a dataset is huge, it's hard to build the model. The huge datasets take a lot of time and computational power to work and they exhaust the model. Feature selection is the method where we can select only the important or most contributing features to train with the expense of very less or no loss of accuracy. Lots of people misunderstood the concept of feature selection and feature extraction.
The basic difference between both is, in feature selection, you used a combination of features or a subset of features to get maximum performance/accuracy. whereas in feature extraction we create a whole new set of features from the existing one depending on the dataset’s or feature’s variance and other things.
Choosing features in the dark is a very complicated thing. I picked out two socks from my sock drawer this morning! It was still dark, but that shouldn’t matter, right? After all, they are the same size...THE SAME ?!? The Era of Big Data represents the END OF DEMOGRAPHICS (i.e., our models should no longer be based on and biased by a limited selection of attributes and features)
Uses of feature selection
- To train the algorithm faster
- Improve efficiency
- Reduce redundancy
- Reduce overfitting
- Domain understanding
- The simple interpretation of the model and data
We use two approaches
- Heuristic Approach and Evaluation in ML Algorithm
- Wrapper & filter methods
Filter methods
Filter methods use exact ranking information about features. According to ranking, features are arranged and there is no need to use machine learning algorithms repeatedly. Its accuracy is a little lesser than wrapper methods but still, you can set your trade-off for features and accuracy.
Filter methods: Correlation Filter
Correlation can be defined as a statistical relationship between two entities. In Machine learning, correlation is among two or more features or attributes to check how much they are related to each other.
If any of the two features are highly correlated or both carry the same information then one of them is redundant.
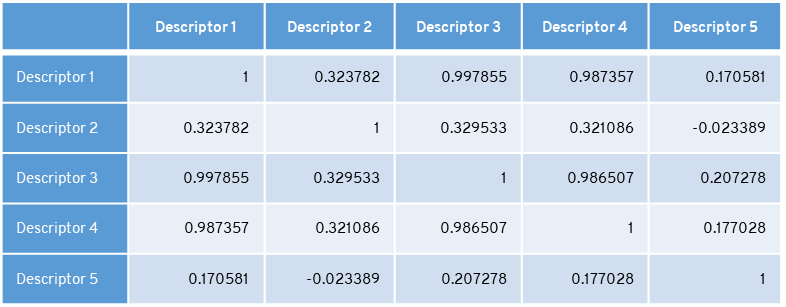
In the table, descriptors 1 & 3 are highly correlated as well as descriptors 1 & 4 and descriptors 3 & 4. Remove the feature which has less variance. Here descriptor 4 carries the least variance and 3 carries the highest variance. 4th descriptor is removed. like this, we reduced the set of features.
Mutual Information
Mutual information (MI) measures the dependency between the input and the target variables. Mutual information should be always >= 0. MI = 0; i.e no relation between input variables and target variable that is input variable is independent of the target variable. Higher values mean higher dependency.
Information Gain
Information gain calculates the reduction in entropy from the dataset.
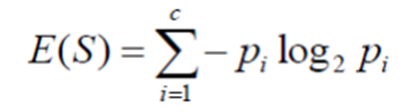
For the training dataset, by evaluating the information gain for each variable, and selecting the variable that maximizes the information gain, i.e. minimizes entropy. Maximum information gain which splits the data into groups for effective classification. Evaluating the gain of each variable in the context of the target variable
Chi-square method for feature selection:
Compute chi-squared stats between each non-negative feature and class. The statistical test was applied to the groups of categorical features to evaluate the likelihood of correlation or association between them using their frequency distribution. Measures the discriminating power of the feature in classifying the data point into one of the possible classes Quantifies the lack of interdependence between a given feature and classification category. A higher value of χ2 implies higher information given by the feature.
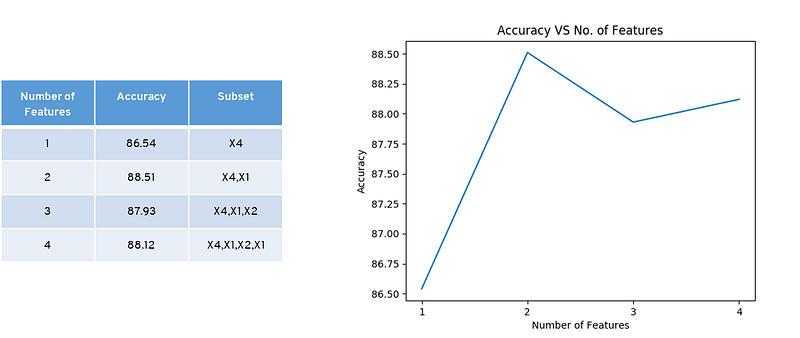
Wrapper Method: Forward Selection
It is an iterative method that starts with having no feature in the model. In each iteration, we keep adding the feature which best improves our model till an addition of a new variable does not improve the performance of the model.
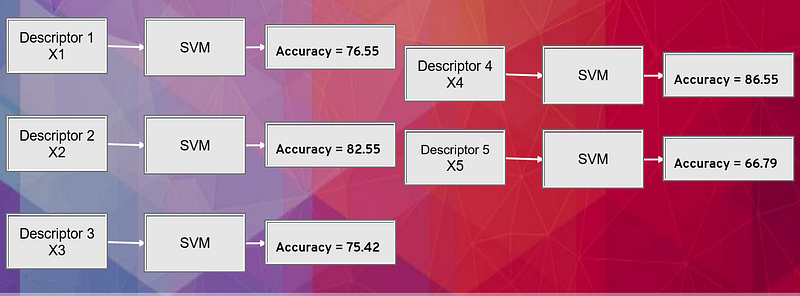
Here we believe in the individual accuracy of Each descriptor. Descriptor 4 has the highest accuracy taking its combination with descriptors. Descriptor 4, 1 has the highest accuracy taking its combination with descriptors. Descriptor 4, 1 & 2 has the highest accuracy taking their combination with descriptors.
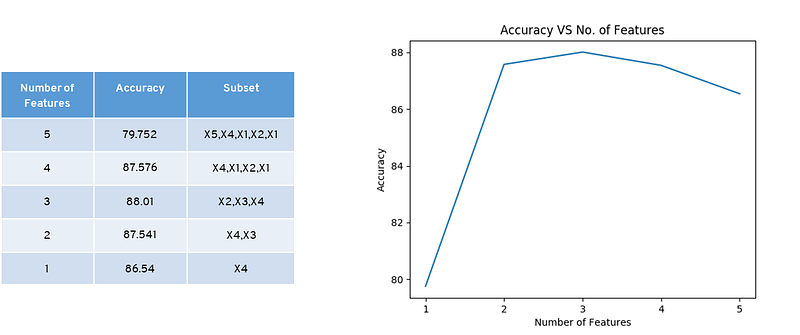
Wrapper Method: Backward Selection
It starts with all the features and removes the least significant feature at each iteration which improves the performance of the model. We repeat this until no improvement is observed in the removal of features.
Accuracy is calculated by removing one feature at a time. When we removed X5, we get an improvement in accuracy.
Embedded Methods
Embedded methods combine the qualities of filter and wrapper methods. It is implemented by algorithms that have their own built-in feature selection methods. Feature selection in embedded methods has a deeper connection to learning algorithms and is part of the classification itself. Embedded methods are less time-consuming and are less prone to overfitting. E.g. LASSO regression and RIDGE regression which have inbuilt penalization functions to reduce overfitting.
Random Forest Feature Importance
Random forests provide two methods for feature selection:
● Mean decrease impurity: For classification trees measure is Gini impurity or information gain/entropy and for regression trees measure is variance. Training a tree, decreases in the weighted impurity are computed. For a forest, the impurity decrease from each feature is averaged and the features are ranked according to this measure.
● Mean decrease accuracy: For every tree grown in the forest, find OOB [out of bag] examples & count the number of votes cast for correct examples. Randomly permute values in features in OBB examples and put these cases down the tree. Subtract the number of votes for the correct class in the variable permuted OOB data from the number of votes for the correct class in the untouched OOB data. The average of this number of all trees in the forest is the raw importance score for variable
Evolutionary Algorithms for Feature Selection
Nature has always been a source of inspiration. It has sparked the development of numerous effective computational tools and algorithms during the past few decades for tackling challenging optimization problems. Evolutionary optimization algorithms are used for feature selection. Some examples are as follows
- Genetic Algorithm
- Ant Colony Optimization
- Simulated annealing
- Swarm Based Algorithms
- Black Hole Algorithm
The biggest advantage of Evolutionary algorithms is they don't require derivative information to work with. We can Sample a subset of the solution near the global optimum.
I tried a simple filter feature selection method on the famous analytics vidya loan prediction problem with much less effort but eventually, the results got improved.
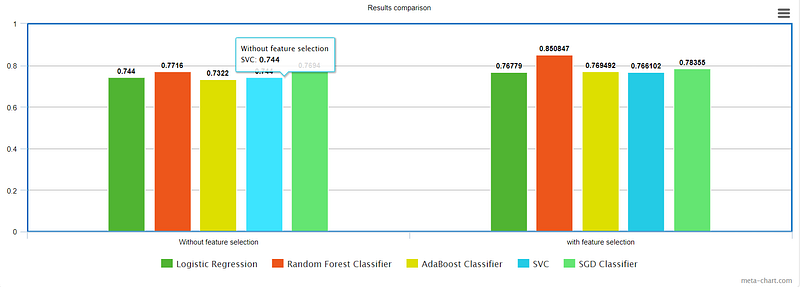
So like this, you can improve your results with the use of the same model that you have. Interestingly, feature selection currently drawing a lot of attention due to its effectiveness.
If you find this insightful
If you found this article insightful, follow me on Linkedin and medium. you can also subscribe to get notified when I publish articles. Let’s create a community! Thanks for your support!
If you want to support me :
As Your following and clapping is the most important thing but you can also support me by buying coffee. COFFEE.





