
OCR : The Incredible reading capability of Machine

What if you have thousands of paper documents and forms and you want to store it digitally! typing each word can help right ? but it will be very tedious, hectic and time-consuming task to type each and everything manually. OCR can help here. OCR stands for “Optical Character Recognition”. An area of computer vision, OCR processes images of text and converts that text into machine-readable forms. It is a technology that recognizes text within a digital image. OCR is used to convert the non-editable soft copies into the editable text documents. Due to this, it can be referred as “The wizardous reading capability of Machine.”

Basically all Optical Character Recognition engines follow basic steps as :
- Noise elimination
a. It removes dusts, graphics
b. It aligns text
c. Converts any type of color combinations into black and white
2) Character recognition
a. Compares each scanned letters pixel by pixel
b. Works on knowing what possible font it can be
c. Decides closest match
3) More sophisticated algorithms work on finest levels. They break each character into different segments and then identify its curves, intensities, corners and look for physical matching to actual shape of characters.
4) On the basis of extracted features and matching, OCR engine decides which character this can be.
5) After identifying characters indivisibly, it aligns them into word sequence .
6) Many times, OCR engines have data or dictionary for mapping a word for which engine is skeptic about or if formed word from characters is not making sense.
Basic steps of working of OCR tools are quite similar. But according to product and its organization, there are many changes in high level processing. I won’t describe all methods in this blog because each method will require separate blog to describe. But I will provide names and references to understand OCR tools in more detail.
You can refer detailed OCR overview for more sound understanding .
Most famous OCR tools are:
1) Tesseract or Pytesseract

— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
2) Keras OCR

— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
3) Microsoft OCR API

— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
4) Omni page

— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
5) Easy OCR

— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
6) Abby cloud OCR

— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
7) Google vision OCR

— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
8) UI path document OCR

— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Then which OCR technique we should use ?
There is a comprehensive comparison for all famous text extraction models
by “Nisarg Kadam” in his YouTube video . I will show his last conclusion,
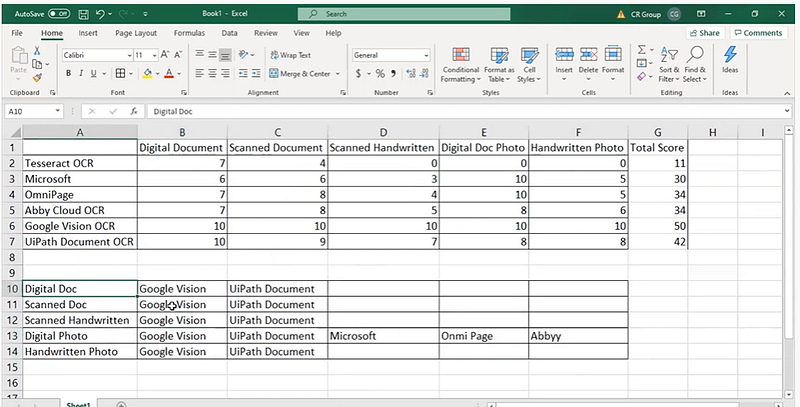
In this particular video series, he compared all models taking in consideration of Digital document, scanned document, Handwritten scanned document, digital photo and handwritten photo. Google Vision and UiPath Document seems work very well in all types of documents. But still most of things are problem statement dependent .
links for Nisarg Kadam’s videos :
part 1:Which OCR is best ?
part2: Which OCR is best?
What if we applied OCR model and didn't get good results ?
There can be many reasons as well as few ways by which you can improve text extraction’s performance .
ways to improve accuracy of OCR model:
1) Select only that language which are present in your source document
This reduces wrong interpretations of characters and patterns and helps to reduce noise. Like in Tesseract, you can select language package.
2) Text rotations
Most of OCR engines work well with horizontal and vertical alignment. It gets harder when there is skewness or angled rotation in text. Some OCR engines have PSM (page segmentation mode) where we can select the orientation of scanning.
3) Lighting of image
Brightness and contrast are the two things which enhance the readability and explicitness of features for text extraction. there are many apps which can help to adjust contrast and brightness of image. Proper lightning condition can improve results of OCR.
4) Image extension
Compressions, resizing and other image manipulations tends to loose image information. .JPG format tends to loose more data after such operations where as .PNG and .TIFF don’t loose data in such extent. Choosing image format wisely can improve OCR’s efficiency. Below mentioned python code can be useful to convert image into desired DPI.
from PIL import Image
img = Image.open("IMAGE.png")
img.save("Converted_IMAGE-600.png", dpi=(300,300))5) Image quality
Dots per inch or DPI is main factor while considering quality of image. Resolution less than 300 DPI can make image unclear. There are many DPI conversion tools online which can get you required DPI. So try to use higher DPI image.
For more understanding of concepts like DPI, Resolution, PNG,JPG & other image formats, PPI, Lossless formats etc. you can refer my previous blog.
| Useful materials |
- I found one pretty good series to understand OCR by Python Tutorials for Digital Humanities . This is link for video series on OCR.
- One interesting GitHub account I found was of Kba for OCR. Here is the link : kba /awesome OCR . You will get to know many things as well as interesting projects with source code from this account.
- I found one excellent book “OCR with Tesseract, OpenCV, and Python” by Dr.Adrian Rosebrock .link for book : Book link
Dr.Adrian Rosebrock Former Founder/CEO at PyImageSearch.com and did his PhD in Computer Vision .
So these all things which can help you to solve your OCR related problem statements at basic levels.
4. A project for “OCR models reading Captchas” you can refer this video.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
|| Read my previous stories ||
Object detection lite : Template Matching
Calibration in Image Processing
Types of Edge detection algorithms
Follow me for more such content on LinkedIn & Medium .
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
THANK YOU!!





