
Tortoise-TTS Fully Explained | Part 1 | Architecture Design
In this series, I will take you on a deep dive into the architecture of the Tortoise-TTS model and explain in detail how the Tortoise-TTS model works. This will not only be done theoretically, but will also be accompanied by code.
If you like videos more, feel free to check out my YouTube video to this article:
In previous articles I have already described how to use the Tortoise TTS model, how to generate longer speech with the Tortoise model and how to generate speech 5x faster with the Tortoise TTS model.
Table of Contents
- Part 1 — The Overall Architecture
- Part 2 — The Autoregressive Model
- Part 3 — The CLVP Model
- Part 4 — The Diffusion Model
- Part 5 — The Vocoder Model
The Overall Architecture
Before we get into the details, let’s take a look at the overall architecture to get a better understanding of how the Tortoise-TTS model works and what its main components are.
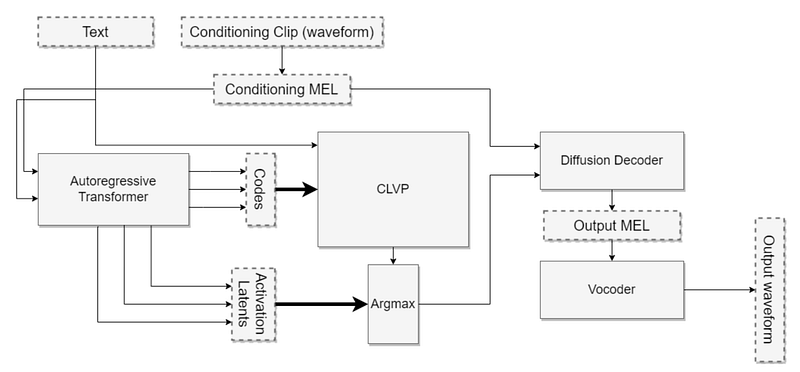
Autoregressive Model (GPT-2): The autoregressive model (GPT-2 architecture) takes as input the text for which speech is to be generated, as well as some audio samples of the voice with which the speech is to be generated. The autoregressive model then outputs many MEL token sequences. The MEL tokens efficiently represent a MEL spectrogram, which is explained in the theoretical background section.
Contrastive Language-Voice Pretrained Transformer (CLVP, similar to CLIP): The CLVP model is based on the well-known CLIP model, which is a discriminative model. Given a generated MEL token sequence and the text for which speech is to be generated, the CLVP model calculates a score that indicates the similarity between the given text and the MEL token sequence. Based on the CLVP scores, only the top_k (e.g. 4) MEL token sequences with the highest score are processed further.
Diffusion Model (DALL-E): Instead of the MEL token sequence itself, the diffusion model takes internal representations of the autoregressive model as input to generate a specific MEL token sequence. This so-called Tortoise Trick will be explained in more detail later. In addition, some audio samples of the voice with which the speech is to be generated are also given as input. The diffusion model then outputs a MEL spectrogram.
Vocoder (UnivNet): Finally, the vocoder takes the generated MEL spectogram as input and converts it into an audio waveform.
Giveaway — Win an NVIDIA RTX 3080 Ti GPU 🎉
I have exciting news for you guys. One of you can win an NVIDIA RTX 3080 Ti GPU with 12GB VRAM, 320 Tensor Cores, 912 GB/s memory bandwidth. What do you need to do to win this GPU? Attend to NVIDIA’s GTC 2024 conference (March 18–21) and send a screenshot as a proof of attendence to me, that’s it! The GTC conference is happening online and in-person. In case you haven’t heard about the GTC conference yet, the GTC conference covers a wide range of topics in the area of AI giving you a great idea of what’s coming next in AI. There are more than 600 sessions and people from all major players in the field of AI like Meta, OpenAI, Google DeepMind, NVIDIA, or RunwayML will be holding talks. Personally, I find the “What’s Next in Generative AI”, “The Fastest Stable Diffusion in the World” as well as the “Human-Like AI Voices: Exploring the Evolution of Voice Technology” talks very interesting. Good luck to everyone and don’t miss out on this one!
Win an NVIDIA RTX 3080 Ti 🎉
Step 1: Register for GTC 2024
Step 2: Send Your Proof of Attendance (Deadline March 22nd)
Theoretical Background
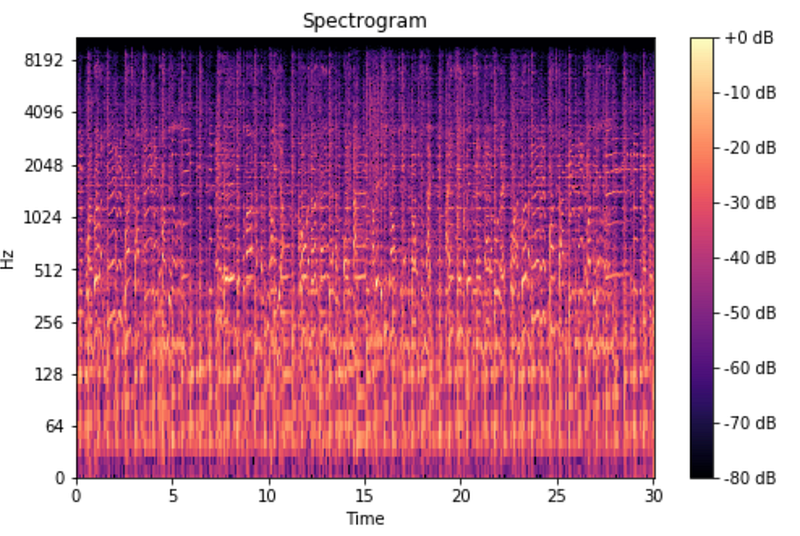
Mel Spectrogram: Mel spectrograms are a popular choice for processing audio data in neural networks because they can reproduce the characteristics of human auditory perception in a very efficient format. As can be seen in the image below, the Mel spectrogram is highly spatially compressed. However, most of the information is still contained in the features that are extracted using the Mel scale. For example, the MEL configuration used by the Tacotron works with a 256-fold compression of the raw audio waveform data sampled at 22 kHz.
Latent Space:
Unprocessed raw audio is very high-dimensional. For example, a 2-channel stereo sound with a sampling rate of 44.1 kHz and 16-bit precision consumes 44,100*16*2 = 1,411,200 bits per second (1.4 Mbps). In comparison, a 512*512 image (8-bit RGB depth) consumes a total of 512*512*8*3 = 6,291,456 bits. To overcome this, it is usually assumed that high-dimensional audio data can be effectively captured by a low-dimensional representation (see Manifold Hypothesis). This low-dimensional space is called latent space and encodes the essential features or variation factors in the high-dimensional data. For speech data, such latent factors could be, for example, intonation, rhythm, pitch, timbre or tone. It is important to note that such latent variables are learned by AI models and not created manually.

Final Thoughts
I hope you enjoyed this article. I will publish more articles about how to use AI models and how they work in the future. Follow me if that sounds interesting to you. :-)
Isn’t collaboration great? I’m always happy to answer questions or discuss ideas proposed in my articles. So don’t hesitate to reach out to me! 🙌 Also, make sure to subscribe or follow to not miss out on new articles.
YouTube: https://bit.ly/3LqA1Os
LinkedIn: http://bit.ly/3i5Sc1g



