
Using Collation in Google BigQuery
How to Compare and Sort Strings easily with SQL

After Google has made headlines with new tools in the area of Data Lakehouse (click here for more info), there are now again novelties for Data Analysts working with BigQuery SQL. Google now offers the functionality of case-insensitive collation [1].
What is Collation?
Collation determines how your data is sorted and compared. It’s for example important when working international texts and chars. Collations provide sorting rules, case, and accent sensitivity properties for your data. Collations that are used with character data types, such as char and varchar, dictate the code page and corresponding characters that can be represented for that data type [2].
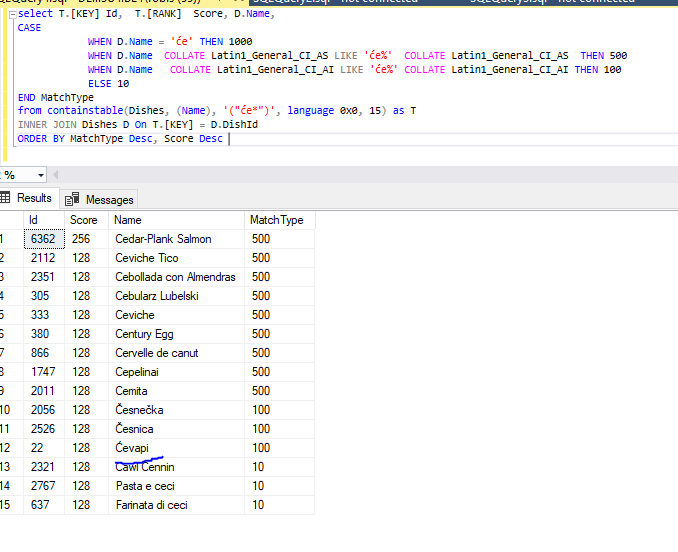
Example
Here is a small example of how to use it within BigQuery with distinctive representation of the letter ‘c’. One time lowercase, one time uppercase and one time the Czech letter Č.
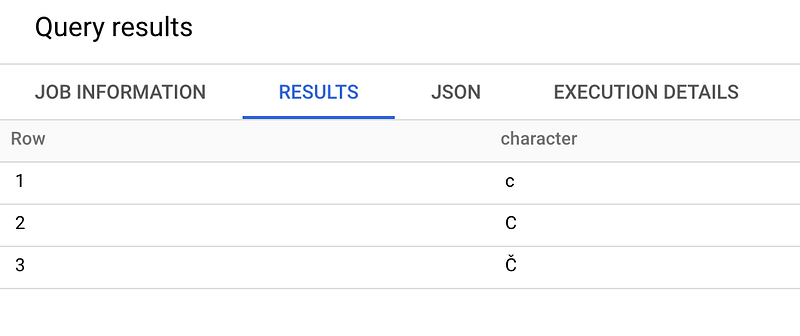
SELECT * FROM UNNEST([
COLLATE(‘Č’, ‘und:ci’),
‘c’,
‘C’
]) AS character
ORDER BY characterCollation ensures that these are sorted according to their encoding.
The Language Tag
When using collation you will need to use the language tag like you can see in the example. It determines how strings are generally sorted and compared. Allowed values for language_tag are[4]:
und: A locale string representing the undetermined locale.undis a special language tag defined in the IANA language subtag registry and used to indicate an undetermined locale. This is also known as the root locale and can be considered the default Unicode collation. It defines a reasonable, locale agnostic collation.
The Collation Attribute
Additional to the language tag, the unicode collation specification must have a collation_attribute, which enables additional rules for sorting and comparing strings. ci: means that the Collation is case-insensitive [4].
Summary
A very handy feature that Google now provides in BigQuery. I hope the example helps you with the first steps. For all further information feel free to use the links below. Especially the documentation of Google should help you here, e.g. with which functions, expressions and operators you can use with this. You might be also interested in “NORMALIZE AND CASEFOLD” in BigQuery.
Sources and Further Readings
[1] Google, Release Notes (2022)
[2] Microsoft, Collation and Unicode support (2022)
[3] Github, SQL Server Latin Accent Sensitive collation (2019)
[4] Google, Working with collation (2022)



