
Distributed Data Processing with Apache Spark
Data processing with a general-purpose distributed data processing engine.

Apache Spark, written in Scala, is a general-purpose distributed data processing engine. Or in other words: load big data, do computations on it in a distributed way, and then store it.
Spark provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
To run Spark, you can either spin your own cluster or use Amazon EMR with/without Amazon Glue, or use Google Dataproc.
Apache Spark contains libraries for data analysis, machine learning, graph analysis, and streaming live data. Spark is generally faster than Hadoop. This is because Hadoop writes intermediate results to disk (that is, lots of I/O operations) whereas Spark tries to keep intermediate results in memory (that is, in-memory computation) whenever possible. Moreover, Spark offers lazy evaluation of operations and optimizes them just before the final result; Sparks maintains a series of transformations that are to be performed without actually performing those operations unless we try to obtain the results. This way, Spark is able to find the best path looking at overall transformations required (for example, reducing two separate steps of adding number 5 and 20 to each element of the dataset into just a single step of adding 25 to each element of the dataset, or not actually doing operations on part of the dataset which will eventually will be filtered out in the final result). This makes Spark one of the most popular tools for big data analytics currently.
Hadoop saves intermediate states to disk and communicates over a network. If we consider the logistic regression of ML model, then each iteration state is saved back to disk. The process is slow. Whereas, Spark keeps all data immutable and in-memory. It achieves this using idea from functional programming such as fault tolerance, which works by replaying functional transformations over original datasets.
Spark laziness (on transformation) and eagerness (on action) is how Spark optimizes network communication using the programming model. Hence, Spark defines transformations and actions on Datasets (and RDD) to support this. The transformations (such as where) are lazy, and so their resultant output is not immediately computed. Actions (such as take) are eager. Their results are immediately computed.
The Hadoop ecosystem includes a distributed file storage system called HDFS (Hadoop Distributed File System). Spark, on the other hand, does not include a file storage system. You can use Spark on top of HDFS but you do not have to. Spark can read in data from other sources as well such as Amazon S3.
While Spark doesn’t implement MapReduce, one can write Spark programs that behave in a similar way to the map-reduce paradigm.
For Big Data processing, the most common form of data is key-value pairs. In fact, in a 2004 mapReduce research paper the designer states that key-value pairs is a key-choice in designing mapReduce. During the transformations, a key generally acts as a group against which aggregated value is calculated in a transformation.
Similar to Hadoop, partitioning in Spark(Hash partitioners or Range partitioners) can bring enormous performance gains, especially in the shuffling phase.
Data streaming is a specialized topic in big data. The use case is when you want to store and analyze data in real-time such as Facebook posts or Twitter tweets. Spark has a streaming library called Spark Streaming although it is not as popular and fast as some other streaming libraries. Other popular streaming libraries include Apache Storm and Apache Flink. Kafka or Kinesis are useful when using Spark Streaming.
Handy References:
- Apache Spark Home Page
- Apache Spark Documentation
- Apache Spark Quick Start Guide
- Apache Spark Python API Docs
- Apache Spark SQL and Dataset Guide
- Dask and Spark Comparison
Spark in Local Mode
The easiest way to try out Apache Spark is in Local Mode. The entire processing is done on a single server. You thus still benefit from parallelization across all the cores in your server, but not across several servers.
Spark runs on JVM. It exposes a Python, R, Scala and SQL interface.
For Python, Spark provides Python API via PySpark, which is available in PyPI and so can be installed via pip. It can be imported or directly invoked as pyspark to get an interactive shell.
# install pyspark
pip install --upgrade pyspark# get pyspark help
pyspark --help# invoke pyspark interactive shell
pyspark# or through python or ipython
ipython
>> import pysparkSimilarly, Scala and R also provide interactive shells spark-shell and sparkR respectively.
For other installation options, check spark.apache.org/downloads.html.
Spark in Cluster-Mode
The Spark cluster mode overview explains the key concepts in running on a cluster. Spark can run both by itself (standalone), or over several existing cluster managers (Hadoop, Apache Mesos, Kubernetes).
The system currently supports several cluster managers:
- Standalone — a simple cluster manager included with Spark that makes it easy to set up a cluster.
- Apache Mesos — a general cluster manager that can also run Hadoop MapReduce and service application.
- Hadoop YARN — the resource manager in Hadoop 2
- Kubernetes — an open-source system for automating deployment, scaling, and management of containerized applications
Spark is organized in a master/workers topology. In the context of Spark, the driver program is a master node whereas the executor nodes are the workers. Each worker node runs the same task and returns the results to the master node. The resource distribution is handled by a cluster manager.
Spark applications run as independent sets of processes on a cluster, coordinated by the
Specifically, to run on a cluster, the SparkContext can connect to several types of cluster managers, which allocate resources across applications. Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.
Each application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads. This has the benefit of isolating applications from each other, on both the scheduling side (each driver schedules its own tasks) and executor side (tasks from different applications run in different JVMs). However, it also means that data cannot be shared across different Spark applications (instances of SparkContext) without writing it to an external storage system.
Each driver program has a web UI, typically on port 4040.
Spark gives control over resource allocation both across applications (at the level of the cluster manager) and within applications (if multiple computations are happening on the same SparkContext). The job scheduling overview describes this in more detail.
While

Here:
- The return value is a
SparkSessionobject. master(master)sets the Spark master URL to connect to, such as"local"to run locally, and"local[4]"to run locally with4cores, or"spark://master:7077"to run on the Spark standalone cluster.appName(name)sets a name for the application, which will be shown in the Spark web UI. If no application name is set, a randomly generated name will be used.config(key=None, value=None, conf=None)sets a config option. Options set using this method are automatically propagated to bothSparkConfandSparkSession‘s own configuration.getOrCreate()gets an existingSparkSessionor, if there is no existing one, creates a new one based on the options set in this builder.
Functional programming languages and Distributed systems
Why we need functional programming for distributed systems?
Spark uses functional programming language, Scala. The reason behind this is that functional programming is perfect for distributed systems.
In functional programming, if f(x) = x + 5, then f(3) is always 8. But, this is not always true in non-functional languages such as Python. For example,
w = -2def f(x):
global w
w -= 1
return x + w + 10f(3)
f(3)As a result, running the same code again can give different results. The problem in this example is easy to see, not that easy when you have dozens of machines running code in parallel, and sometimes you need to restart a calculation if one of the machines has a temporary issue. These unintended side effects can lead to a major headaches. The confusion comes from sloppy language.
How DAG and lazy evaluation helps in the running of memory:
Just like bread companies make copies of the starter from their mother dough, every Spark function makes a copy of its input data and never changes the original parent data (that is, original data is kept immutable). Because Spark doesn’t change or mutate the input data, it is known as immutable. This makes sense when you have a single function, but in case you have multiple functions, then you chain together multiple functions that each accomplish a small chunk of the work. You’ll often see a function that is composed of multiple sub-functions, and in order for this big function to be peer, each sub-function also has to be a peer. It would seem that Spark needs to make a copy of the input data for each sub-function. If this was the case, your Spark program would run out of memory pretty quickly.
Fortunately, Spark avoids this by using a functional programming concept called lazy evaluation. Before Spark does anything with the data in your program, it first builds step-by-step directions of what functions and data it will need. These directions are like recipes of your bread, and in Spark this is called a Directed Acyclic Graph (DAG). Once Spark builds the DAG from your code, it checks if it can procrastinate, waiting until the last possible moment to get the data. Thus, spark has the opportunity to optimize the overall transformation process. This is exactly what you would do if you were making bread. You want to grab the flour, bring it back to your bowl, and then go back to the pantry and get some sugar and add it to the bowl, and then go back to the cupboard for the salt, and so on for every ingredient. This would be the cooking equivalent of thrashing. Instead, you look at the recipe before you start mixing ingredients together to see what you can grab and mix together in one big step. In fact, you often mix all your dry ingredients, then mix all your wet ingredients, and combine them together before baking. In Spark, these multi-step combos are called stages.
Functional programming in Python:
Anonymous functions can be thought of as a Python feature for writing functional-style programming.
Declarative Programming vs. Imperative Programming in Spark
Declarative programming is concerned with What and in Spark can be done with Spark SQL using Spark SQL built-in functions. Whereas, imperative programming is concerned with How and in Spark can be done with Spark DataFrames and Python.
Dataset and DataFrame in Spark
Difference between Dataset and DataFrame
A Dataset is a distributed collection of data. Dataset interface provides the benefits of Resilient Distributed Dataset (RDD) with the benefits of Spark SQL’s optimized execution engine. The Dataset API is available in Scala and Java. Python does not have the support for the Dataset API.
A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources. The DataFrame API is available in Scala, Java, Python (
Note that the
Spark vs Pandas
One of the key differences between Pandas and Spark dataframes is eager versus lazy execution. In PySpark, operations are delayed until a result is actually needed in the pipeline. This approach is used to avoid pulling the full data frame into memory and enables more effective processing across a cluster of machines. With Pandas dataframe, everything is pulled into memory, and every Pandas operation is immediately applied. Another key difference is that Spark lets you use parallalization using partitions.
The Parquet Format
Parquet is a columnar file (unlike CSV which is row-based storage) format that saves both time and space when it comes to big data processing, and it is a file format that includes metadata about column data types. Parquet, for example, is shown to boost Spark SQL performance by 10x on average compared to using text, thanks to low-level reader filters, efficient execution plans, and in Spark 1.6.0 improved scan throughput! Refer to this article by IBM.
So, if data is in CSV format, it makes sense to load those files in Spark, convert and save them in parquet format, and then use them whenever they are required.
When using CSV files into DataFrames, Spark performs the operation in eager mode (that is, all of the data is loaded into memory before the next step begins execution), while a lazy approach is used when reading files in parquet format.
Also note that while working with Spark, for distributed clusters it doesn’t make sense to load files (or write files to) from local storage. We should rather be using Amazon S3 or HDFS.
The DataFrame
A pyspark.sql.DataFrame (and pyspark.sql.GroupedData) is equivalent to a relational table in Spark SQL, and can be created using various functions in pyspark.sql.SparkSession.
Use <spark_session>.read to access pyspark.sql.DataFrameReader to load DataFrame from external storage systems.
Use <data_frame>.write to access pyspark.sql.DataFrameWriter to write DataFrame to external storage.
Use sql.types.StructType with a list of sql.types.StructFields to represent a data type representing a row.
For example:


Before we continue further with the example, let’s briefly look at some categories of commonly used functions:
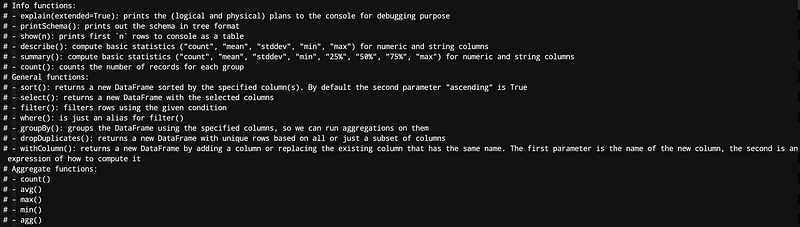
continuing with the example..
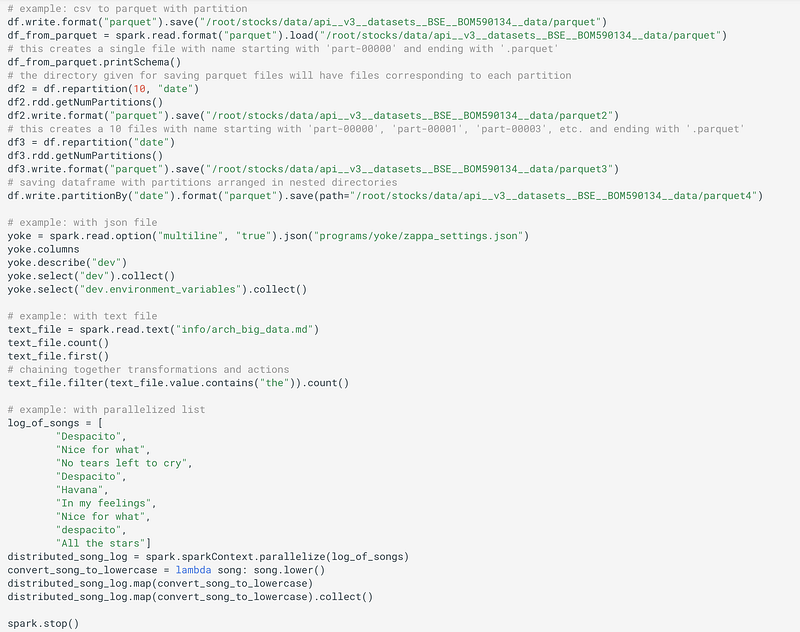
Where to store data? S3 or HDFS
When you use Amazon S3 (preferred), you’re separating the data storage from your cluster. One of the downsides is that you have to download your data across the network which can be a bottleneck (but, it won’t be the case is Spark is running on AWS itself). Another solution is to store the data on your Spark cluster with HDFS.
Spark and HDFS are designed to work well together. When Spark needs some data from HDFS, it grabs the closest copy which minimizes the time data spends traveling around the network. But there is a trade-off to HDFS. You have to maintain and fix the system yourself. For many companies, from small startups to big corporations, S3 is just easier, since you don’t have to maintain a separate cluster. Also, if you rent clusters from AWS, your data usually doesn’t have to go too far in the network since the cluster hardware and the S3 hardware are both on Amazon’s data centers. Finally, Spark is smart enough to download a small chunk of data and process that chunk while waiting for the rest to download.
Submitting Spark Applications
The spark-submit the script in Spark’s bin the directory is used to launch applications on a cluster. It can use all of the Spark’s supported cluster managers through a uniform interface so you don’t have to configure your application for each one.
If your code depends on other projects, you will need to package them alongside your application in order to distribute the code to a Spark cluster. For Python, you can use the --py-files argument of spark-submit to add .py, .zip or .egg files to be distributed with your application. If you depend on multiple Python files, it is recommended to package them into a .zip or .egg.
Once a user application is bundled, it can be launched using bin/spark-submit a script. This script takes care of setting the classpath with Spark and its dependencies, and can support different cluster managers and deploy modes that Spark supports:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]Some of the commonly used options are:
--class: The entry point for your application (e.g.org.apache.spark.examples.SparkPi)--master: The master URL for the cluster--deploy-node: Whether to deploy your driver on the worker nodes (cluster) or locally as an external client (client) (default)--conf: Arbitrary Spark configuration property in"key=value"format.application-jar: Path to a bundled jar including your application and all dependencies. The URL must be globally visible inside of your cluster, for instance, anhdfs://path or afile://path that is present on all nodes.application-arguments: Arguments passed to the main method of your main class, if any
For Python applications, simply pass a .py file in the place of <application-jar> instead of a JAR, and add Python .zip, .egg or .py files to the search path with --py-files.
Spark Streaming
Spark’s Limitation: Spark Streaming’s latency is at least 500 milliseconds since it operates on micro-batches of records, instead of processing one record at a time. Native streaming tools such as Storm, Apex, or Flink can push down this latency value and might be more suitable for low-latency applications. Flink and Apex can be used for batch computation as well, so if you’re already using them for stream processing, there’s no need to add Spark to your stack of technologies.
Debugging and Optimization in Spark
When you are working on a distributed Spark cluster, errors in your code can be very hard to diagnose.
Normally, when a function is passed to a Spark operation (such as map or reduce) is executed on remote cluster worker nodes, they work on separate copies of all the variables used in the function. These variables are copied to each machine, and no update to the variable on the remote worker machines are propagated back to the driver program.
Supporting general, read-write shared variables across tasks would be inefficient. However, Spark does provide two limited types of shared variables for two common usage patterns: broadcast variables and accumulators.
Broadcast Variables in Spark
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication costs.
Spark actions are executed through a set of stages, separated by distributed “shuffle” operations. Spark automatically broadcasts the common data needed by tasks within each stage. The data broadcasted this way is cached in serialized form and deserialized before running each task. This means that explicitly creating broadcast variables is only useful when tasks across multiple stages need the same data or when caching the data in the deserialized form is important.
Broadcast variables can be created from a variable v by calling SparkContext.broadcast(v). The broadcast variable is a wrapper around v, and its value can be accessed by calling the value method.
>>> broadcastVar = sc.broadcast([1, 2, 3])
<pyspark.broadcast.Broadcast object at 0x102789f10>>>> broadcastVar.value
[1, 2, 3]After the broadcast variable is created, it should be used instead of the value v in any function run on the cluster so that v is not shipped to the nodes more than once. In addition, the object v should not be modified after it is broadcast in order to ensure that all nodes get the same value of the broadcast variable (e.g. if the variable is shipped to a new node later).
Accumulators in Spark
Accumulators are variables that are only “added” to through an associative and commutative operation and can, therefore, be efficiently supported in parallel. They can be used to implement counters (as in MapReduce) or sums. Spark natively supports accumulators of numeric type, and programmers can add support for new types.
As a user, you can create named or unnamed accumulators. As seen in the image below, a named accumulator (in this instance counter) will display in the web UI for the stage that modifies that accumulator. Spark displays the value for each accumulator modified by a task in the “Tasks” table.
Tracking accumulators in the UI can be useful for understanding the progress of running stages (NOTE: this is not yet supported in Python).
An accumulator is created from an initial value v by calling SparkContext.accumulator(v). Tasks running on a cluster can then add to it using the add method or the += operator. However, they cannot read its value. Only the driver program can read the accumulator’s value, using its value attribute.
>>> accum = sc.accumulator(0)
>>> accum
Accumulator<id=0, value=0>>>> sc.parallelize([1, 2, 3, 4]).foreach(lambda x: accum.add(x))
...
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s>>> accum.value
10Accumulators do not change the lazy evaluation model of Spark. If they are being updated within an operation on a DataFrame, their value is only updated once that DataFrame is computed as part of the action.
Spark Web UI
Each driver program has a web UI, typically on port 4040, that displays information about running tasks, executors, and storage usage. Simply go to http://<driver-node>:4040 in a web browser to access this UI. The monitoring guide also describes other monitoring options.
The web UI provides the current configuration for the cluster which can be useful for double-checking that your desired settings went into effect.
The web UI also shows you the DAG, the recipe of the steps for your program. A Spark application consists of as many jobs as many actions (like saving DataFrame to a database or taking some records back to the driver for inspection) regarding the code. Jobs are further broken up into stages. Stages are units of work that depend on one another. The smallest unit within a stage is a task. Tasks are a series of Spark transformations that can be run in parallel on different partitions of our DataFrame. So, if we have 10 partitions, we run 10 of the same task to complete a stage. Tasks are the steps that the individual worker nodes are assigned. In each stage, the worker node divides up the input data and runs the task for that stage.
By default, Spark master uses port 7077 to communicate with the worker nodes, port 4040 shows active Spark jobs, the web UI for your master node is on port 8080 (or 4040) .
Here are some related interesting stories that you might find helpful:
- Fluent NumPy
- Fluent Pandas
- Data Streaming With Apache Kafka
- Apache Cassandra — Distributed Row-Partitioned Database for Structured and Semi-Structured Data
- Data Pipelines with Apache Airflow
- Designing Workflows using Argo
- The Why and How of MapReduce
- Observer Pattern vs. Pub-Sub Pattern
Gain Access to Expert View — Subscribe to DDI Intel




