
Deep Learning Architecture Search and the Adjacent Possible

What is the biggest problem with deep learning networks? I propose that it is: “learning how to forget”. Deep learning networks are very good at remembering things, it is so good at this capability that it has no trouble learning random labels.
Its biggest problem, however, is that it does not know how to forget. This may surprise many, but learning to forget is critically important in a cognitive system. Forgetting is critical in building persistent abstractions. This is essentially a more complex form of attention.
Advanced deep learning systems employ attention mechanisms to reduce the complexity of the input space and to focus on what is important. The side-effect of attention is that information is ignored (or basically thrown away). It is a general form of invariance or even covariance. What does not change, can effectively be ignored.
Forgetting is analogous but it is an attention mechanism that throws away information in the form of existing memory. Memory in the context of cognitive machines are the mental models that are stored through experience. Throwing away memory (or forgetting) is the process of pruning and consolidating experiences into a form that leads to generalization. The problem with neural networks is that memory is poorly encapsulated. It is one uniform collection of neural weights where the only kind of encapsulation is enforced per layer through the mechanism of an activation function. An activation function is a threshold function that modulates the flow of information. This has its effect in the forward flow of inference as well as the backward flow of learning (i.e. back-propagation). It is a deep learning network’s crude way of modulating memory changes.
Previously, I wrote that biological evolution’s memory mechanism comes in the form of modularity. Evolution is a learning process that incorporates both exploitation and exploration strategies. These strategies are manifested in the competition and cooperation of its modular units. The evolutionary cycle can be broken into a competition phase and consolidation phase. The cycle leads towards the emergence of more complex modularity.
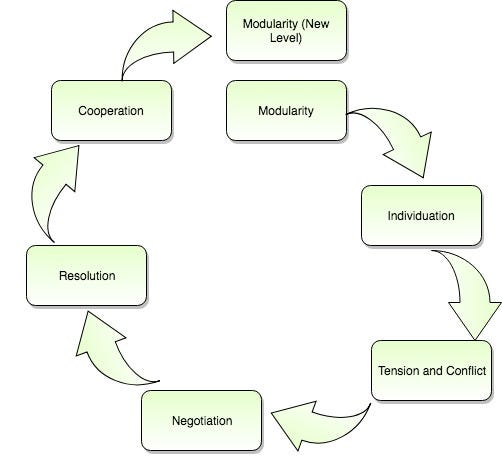
This kind of bootstrapping towards more complex modularity can also be observed in deep learning systems. The evidence of this can be found in the phase transitions we see while training networks.
In the cyclic learning rate (CLR) method pioneered by Leslie Smith, training undergoes many exploratory and optimization phases. The CLR approach is so effective that the team at Fast.ai trained ResNet50 in less than 3 hours with a cost of only $72.40. This was only bested by AmoebaNet, which we will mention later.
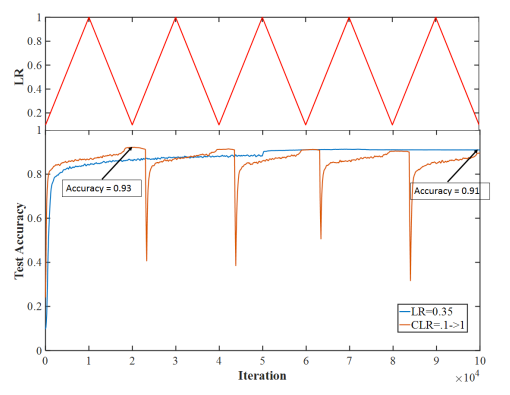
The theoretical explanation for this behavior has not yet been formulated. However, I highly suspect that it exhibits the same kind of mechanism as found in the evolutionary cycle. There is a competition among sub-networks for better inference accuracy and a subsequent consolidation among sub-networks that leads to higher abstractions and thus generalization. The cyclic learning rate approach has a disruptive phase where the learning rate is rapidly increased. This has the effect of a mass extinction event where the original configuration begins again its exploration process. Similar to mass extinction events in evolution, this approach leads to a much better network that has higher accuracy and converges faster than the previous network. We shall see later a generalization of this method where something more sophisticated than the learning rate is changed.
The role of mass extinctions in evolution is quite perplexing. It has been argued that mass extinction leads to greater diversity (and thus creativity) in an eco-system by leveling the playing field and allowing new species to thrive in previously vacated niches.
The layering in deep learning is what is usually attributed to its generalization capability. Layers introduce a natural modularity into a neural network. The problem, however, is that the modularity of layers is static. That is during training, no new layers are added into a network, and no new layers are removed from the network. To circumvent this rigidity, residual networks where introduce that effectively are equivalent to layers being sliced into many sub-parts. This supports a more fine-grained evolution of the modularity of a layer. The abstraction boundaries of a residual network are now much richer. The problem, however, is that there is no encapsulation mechanism that is present. There is no mechanism that modulates forgetting in the network.
There are few compelling solutions proposed for the forgetting problem in deep learning. These proposals come in several variants (1) bulk freezing of entire layers (2) higher capacity networks that remember everything and never forget and (3) some kind of gating mechanism. The first two are static decisions that are too rigid. The gating mechanism certainly controls forgetting but does not do so in the process of creating higher abstractions. The reason to forget should not be motivated by the need to reduce information, but rather it should be driven by the need to create higher abstractions. Forgetting should be a side-effect of learning higher abstractions.
The problem is that a neural network has to forget only as part of a competitive process. In the evolution cycle, there is a negotiation and resolution phase that serves as to the determination of whether an abstraction is consolidated into a higher abstraction. There is a cooperative process that determines what needs to be consolidated. This is a process where creating something new exceeds the cost of recycling. What we need is a forgetting process that is a natural part of this cooperative process.
The memory of evolution are the species that survive. Evolution forgets through extinction. Marvin Minsky once remarked that Evolution remembers what it did right, but forgets what it did wrong. This is a process that does not have a global control process that decides what to forget. Rather, it is a decentralized process where what is forgotten are the ones that have not used. Those that are most adaptable and useful for the ecosystem are those that survive. Similarly, the most adaptable and useful cognitive structures are the ones most likely to survive.
Events that cause extinctions are events that are not anticipated. These are the anomalies in the environment and the faults in the machinery. The key characteristic of mass extinctions is that not everything goes extinct. Evolution creates richer diversity from what has survived, it doesn’t start from scratch.
Recent experiments on biological brains have shown that the strategy for learning new tasks is not to forget, but rather to reuses existing neurons.
Brains don’t forget, but rather recycle its wiring for newer tasks. To do this efficiently, cliques of neurons should have a kind of modularity that maximizes their reusability.
This strategy of recycling existing networks has been profitably leveraged in the area of Neural Architecture Search (NAS). Neural Architecture Search is a black-box optimization method that attempts to discover new neural architectures by sampling over the space of network configurations. I’ve described this brute force method for discovering the state of the art architectures previously.
Efficient Architecture Search (ENAS) by Google achieved 1000x fewer resources by simply reusing subnetworks. Conventional hyper-parameter search is performed by simulating unique random models with the assumption that the parameter space is too large for any search method. ENAS ignores this conventional wisdom and simply recycles previous subnetworks across all models in the search. Resource Efficient Neural Architect (RENA) by Baidu also employs a recycling approach. Rather than sharing subnetworks, it uses existing models progressively to circumvent the effort from starting from scratch. These results provide evidence that a network recycling approach, not only works but is actually more effective than random parameter search.
The effectiveness of recycling subnetworks is indeed perplexing. That is, innovation exists within the space of what’s adjacent. One would think that innovation would have to happen elsewhere! What if we take this idea to its ultimate conclusion and restrict our search space to only what is adjacent. That is, to perturb on slightly the parameter space from an existing configuration. Would such an approach be effective?
Surprisingly, it turns out that applying a gradient descent approach to a black box optimization method works exceedingly well. A recent paper by Hanxiao Liu, Karen Simonyan and Yiming Yang (“DARTS: Differentiable Architecture Search”) reveals that this approach requires three orders of magnitude fewer resources than the most effective known architecture (i.e. AmoebaNet)! (Note: AmoebaNet is also a NAS with a peculiar rule: removing the oldest individual to prevent over-fitting) The DARTS paper describes a bilevel optimization method where a continuous parameter is used to drive architecture selection. This is reminiscent of the CLR method, that is an outer loop, however with greater parameter sophistication.
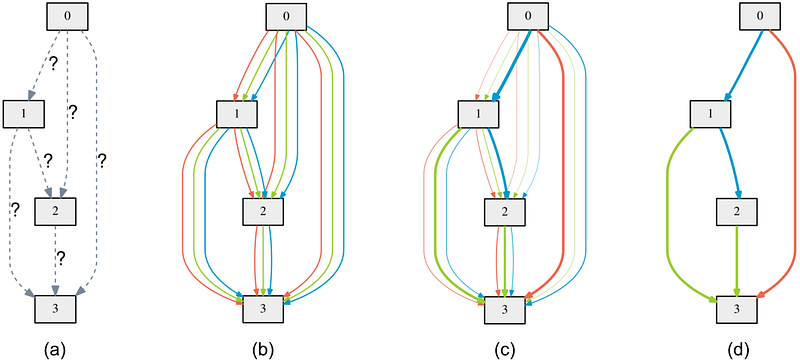
The commonality of ENAS, RENA, and DARTS is that they all maintain modularity boundaries within the learning process. As we’ve seen in the evolution cycle, learning with modularity boundaries involves negotiation and resolution phases. What modules remain and what modules are to be combined.
Proteins are linear strings of twenty different kinds of amino acids. A typical protein is of length 300. There is a combinatorial explosion that tells you that evolution can only explore a ridiculously minuscule subspace of all viable proteins. Yet we have an earth that is teeming with life. Stuart Kauffman argues that this emergent innovation, as a consequence of the adjacent possible, is a phenomenon can’t be explained by mathematics but we know with certainty that it exists. Evolution exhibits behavior that is hard to explain. Neural network learning also exhibits similar behavior that also is difficult to explain.
To summarize, the mechanism for forgetting should happen during the consolidation of existing modules. This is what evolution does and this is also what the brain does. Both systems, re-purpose what already exists. Evolution and the brain aren’t reinventing new parts all the time, rather it is rewiring what already exists. In evolution, this is known as pre-adaptation. When you re-wire you don’t forget, you just repurpose. You save what was useful for another context where it might be eventually useful. This may not be optimal but seems to be the laziest thing that can be done (conforms to the principle of least action). Anything that can be done with the least effort is likely the most natural. This is the adjacent possible at play. This is evolution’s meta-learning in action!
Further Reading

.




