
Data Warehouse vs. Data Lake vs. Data Fabric
What is what and how do they differ from each other?

While the Data Warehouse is now quite a standard in the enterprise context and the Data Lake has also arrived in many companies, the Data Fabric is still a bit more unknown and not yet as widespread, but where do the difference lie and what are the use cases?
Data Warehouse vs. Data Lake
Let’s break down these two architectures right away in one step. Both, Data Lakes and Data Warehouses are established terms when it comes to storing Big Data, but the two terms are not synonymous. A Data Lake is a large pool of raw data for which no use has yet been determined. A Data Warehouse, on the other hand, is a repository for structured, filtered data that has already been processed for a specific purpose [1].
While Data Warehouses use the classic ETL process in combination with structured data in a relational database, a Data Lake uses paradigms such as ELT and a schema on read as well as often unstructured data [2].
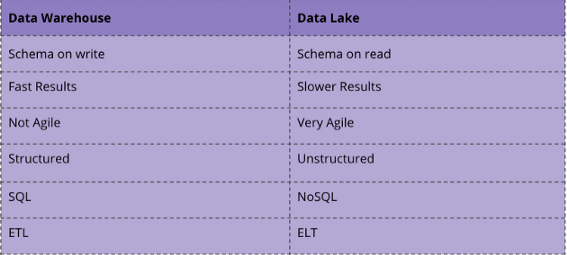
So it’s actually not about Data Lake vs. Data Warehouse. Even though Data Lakes are gaining in importance and the classic Data Warehouse has lost some of its prominence, both solutions are still needed. As you can see above, both solutions have different use cases. Solutions such as Data Lakehouses combine the Data Lake and the Data Warehouse.
Famous Data Warehouse solutions are: Snowflake, Amazon Redshift, Google BigQuery, Azure Synapse Analytics or Databricks. It must be said here that these solutions basically also support the Data Lakehouse approach. Famous Data Lake solutions are: Google Cloud Storage, Azure Data Lake, Amazon S3 or Apache Hadoop.
Data Warehouse vs. Data Lake vs. Data Fabric
A Data Fabric is designed to help organizations solve complex data problems and use cases by managing their data regardless of the types of applications, platforms, and where the data is stored. Data Fabric enables seamless access and data sharing in a distributed data environment. It is similar to the Data Lakehouse, which combines the Data Warehouse and the Data Lake, but goes one step further and also integrates data from applications with each other and offer you services that facilitate control, monitoring, etc. for you and the company.
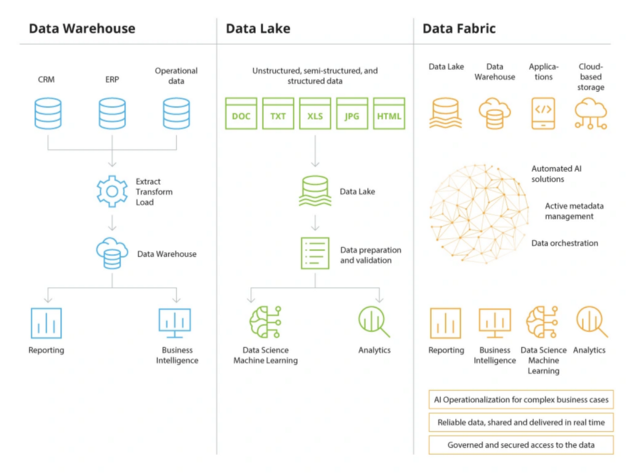
Famous Data fabric solutions are: Talend Data Fabric, IBM Data Fabric, Google Cloud Dataplex.
Summary
So while the Data Lake and the Data Warehouse complement each other very well to form a Data Lakehouse, the Data Fabric goes a bit further and complements such data platforms with apps and ensures the complete exchange of data in the company, while the other solutions are more responsible as a target system for data analysis.
Sources and Further Readings
[1] talend, Data Lake vs. Data Warehouse
[2] IBM, Charting the data lake: Using the data models with schema-on-read and schema-on-write (2017)
[3] infopulse.com, The Many Faces of Cloud Data Platforms: Data Warehouse, Data Lake, and Data Fabric (2022)