
Data Mesh vs Data Fabric
What is what and what are the Differences?

While Data Lake and Data Warehouse are already relatively well-known terms and are established in many companies, Data Meshes and Data Fabrics are still somewhat lesser-known terms.
Let’s first define both terms or technologies and then see where the differences are.
The Data Mesh
It is important to understand that the Data Mesh concept primarily establishes a new organizational perspective and is less based on technical problem solving. Therefore, you should consider this four principles when building up a Data Mesh organization [1]:
- Domain-oriented decentralized data ownership and architecture: A Data Mesh should serve the individuals business units. Therefore, one or different Data Lakehouses could be build.
- Data as a product: The Data Lakehouse architecture helps to manage data as a product by providing different data team members in domain-specific teams complete control over the data lifecycle.
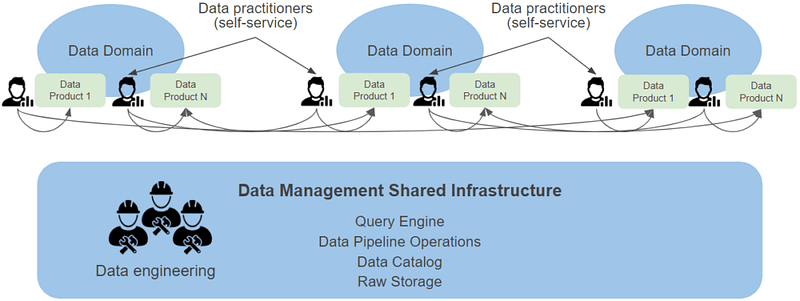
- Self-serve data infrastructure as a platform: Users can supply themselves with data in a self-service BI tool, while Data Scientists, for example, access the same data and develop models.
- Federated computational governance: The data should be backed up and distributed with a role concept. Data catalogs are also helpful here, for example.
A Data Mesh can, for example, be set up on the technical basis of a Data Lakehouse. A Data Lakehouse combines the advantages of a Data Lake and a Data Warehouse. Read more about it here:
The Data Fabric
A Data Fabric is designed to help organizations solve complex data problems and use cases by managing their data regardless of the types of applications, platforms, and where the data is stored. Data Fabric enables seamless access and data sharing in a distributed data environment. It is similar to the Data Lakehouse, which combines the Data Warehouse and the Data Lake, but goes one step further and also integrates data from applications with each other.
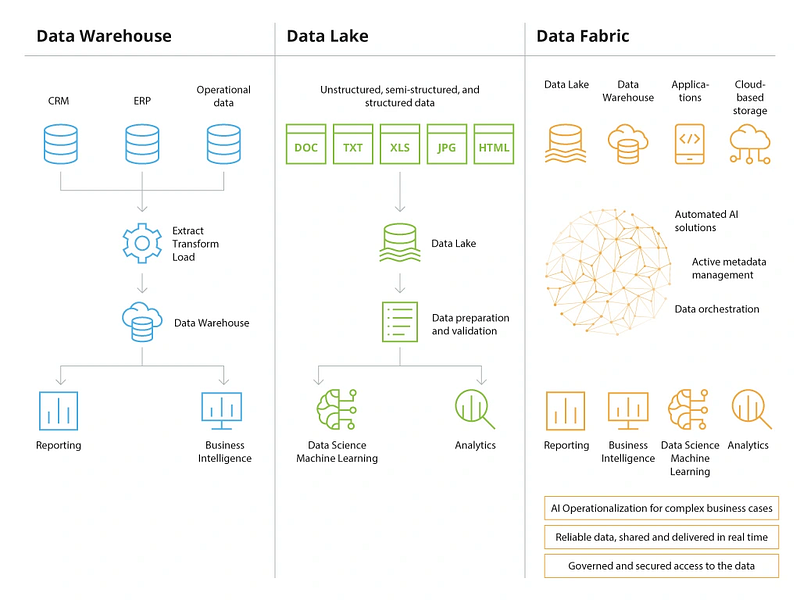
So the idea is to integrate databases and forms such as Data Warehouses and Data Lakes better maybe also by using Data Hubs and to be able to share data better. Data Fabrics go one step further and offer you services that facilitate control, monitoring, etc. for you and the company.
Summary
While Data Mesh focuses on the organizational aspects of a data analysis platform, Data Fabric focuses not only on data integration and analysis, but also on the distribution of data across systems. In addition, unlike the Data Mesh, the Data Fabric is a technical approach.
Sources and Further Readings
[1]Michael Armbrust, Ali Ghodsi, Bharath Gowda, Arsalan Tavakoli-Shiraji, Reynold Xin and Matei Zaharia, Frequently Asked Questions About the Data Lakehouse (2021)
[2] upsolver.com, Demystifying the Data Mesh: a Quick “What is” and “How to” (2022)
[3] infopulse.com, The Many Faces of Cloud Data Platforms: Data Warehouse, Data Lake, and Data Fabric (2022)




