
Data Clustering — how to gain insight if you have unlabeled data?
I realized people usually underestimate the importance of clustering algorithms while trying to learn machine learning. This time, I would like to explain a bit about what clustering is, to list down some of its advantages and disadvantages, and to give examples about where they are mostly used. Let’s dive in!
This story was written with the assistance of an AI writing program.
Data clustering is an unsupervised machine learning model. Clustering mainly aims to divide a finite unlabeled data set into a finite and discrete set of natural, hidden data structures instead of providing an accurate description of unobserved samples produced from the same probability distribution.
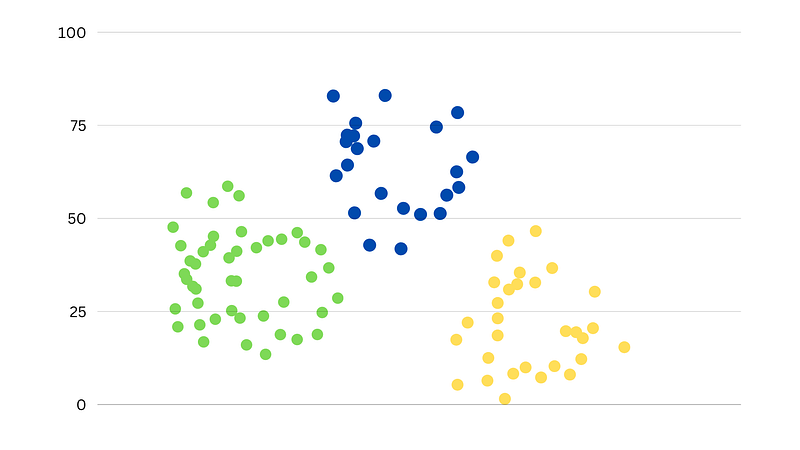
In this extremely basic chart I prepared, you can see 3 clusters. This is what the data should look like as you cluster it. But if you have many features, it would be more difficult to visualize it like this one.
There are several reasons why someone might use clustering:
- To discover patterns or relationships in the data: Clustering can help to identify groups of points that are similar to each other, which can reveal patterns or relationships in the data that may not be immediately apparent.
- To reduce the dimensionality of the data: Clustering can be used to identify a smaller number of groups or clusters within the data, which can make it easier to visualize and analyze the data.
- To identify outliers or anomalies: Clustering can be used to identify points that are significantly different from the other points in the data, which may be of interest for further investigation.
- To generate hypotheses or research questions: Clustering can help to identify groups of points with similar characteristics, which can be used to generate hypotheses or research questions about the relationships between the variables in the data.
- To serve as a preprocessing step for other machine learning algorithms: Clustering can be used to group similar points together, which can be useful as a preprocessing step for algorithms such as classification or regression.
- To group similar items together: Clustering can be used to group similar items together, which can be useful for recommendation systems or other applications where it is desirable to group similar items together.
- To identify subgroups within a population: Clustering can be used to identify subgroups within a population, which can be useful for market segmentation or other applications where it is desirable to understand the characteristics of different subgroups within a larger population.
Let’s look a bit closer to different types of clustering.
- Partitioning methods: These algorithms divide the data into a predefined number of clusters by iteratively reassigning points to the cluster that is most similar to them. Examples of partitioning methods include k-means and k-medoids.
- Hierarchical methods: These algorithms build a hierarchy of clusters by creating a tree-like structure, with the clusters at the leaves of the tree. Examples of hierarchical methods include single-linkage, complete-linkage, and average-linkage.
- Density-based methods: These algorithms identify clusters as regions of high density surrounded by regions of lower density. Examples of density-based methods include DBSCAN and OPTICS.
- Grid-based methods: These algorithms divide the data into a grid and identify clusters as groups of points that fall within the same grid cells. Examples of grid-based methods include STING and CLIQUE.
- Model-based methods: These algorithms model the data using a probabilistic model and use an optimization algorithm to find the model parameters that best fit the data. Examples of model-based methods include Gaussian mixture models and latent Dirichlet allocation.
- Neural network-based methods: These algorithms use artificial neural networks to identify clusters in the data. Examples of neural network-based methods include self-organizing maps and competitive learning.
Advantages of Clustering
- Clustering can identify patterns and relationships in data that may not be immediately apparent by examining individual data points.
- Clustering can help to reduce the dimensionality of data, making it easier to visualize and analyze.
- Clustering can be used to identify outliers or anomalies in a dataset, which may be of interest for further investigation.
- Clustering can be used to generate hypotheses and generate new research questions.
- Clustering can be used as a preprocessing step for other machine learning algorithms, such as classification or regression.
- Clustering can be used to group similar items together, which can be useful for recommendation systems or other applications where it is desirable to group similar items together.
- Clustering can be used to identify subgroups within a population, which can be useful for market segmentation or other applications where it is desirable to understand the characteristics of different subgroups within a larger population.
Disadvantages of Clustering
- Determining the appropriate number of clusters can be difficult and may require domain-specific knowledge or experimentation.
- Different clustering algorithms may produce different results, making it difficult to compare results across studies or to replicate findings.
- Clustering results can be sensitive to the initial conditions or the choice of distance metric, which can affect the quality of the clusters.
- Clustering can be computationally intensive, particularly for large datasets or when using algorithms that do not scale well.
- Clustering assumes that the data points within a cluster are more similar to each other than they are to points in other clusters, but this may not always be the case in practice.
- Clustering does not provide a prediction or a model of the relationships between the variables in the data, which may be necessary for certain types of analysis or decision-making.
- Clustering results may not always be meaningful or interpretable, particularly if the data is noisy or if the clusters are not well-defined.
I was asked in an interview for a data science position, what is the difference between the principal component analysis and clustering.
Both are unsupervised methods. The principal component analysis seeks a lower dimensional dataset so that this dataset can still explain the variance of the data. On the other hand, clustering techniques try to find the subgroups in the data.
Applications
5 main applications of clustering that I find important to mention can be listed as below.
- Collaborative filtering: Clustering in collaborative filtering techniques summarizes people that share similar interests. Collaborative filtering is carried out using the ratings that the various users provide one another. In a number of applications, clustering may be utilized to offer suggestions just like on Netflix or Spotify. You can check my post about collaborative filtering below!
- Customer segmentation: This application is very similar to collaborative filtering, but instead of using rating information, arbitrary attributes about the objects may be used for clustering purposes. It can be used in stores with loyalty cards, telecommunication service providers or banks.
- Data summarization: Many clustering techniques are strongly connected to dimensionality reduction techniques. With the aid of data summarization, the creation of concise data representations is possible.
- Dynamic trend detection: Trend identification may be carried out in a range of social networking platforms using a variety of dynamic and streaming methods. In these applications, the data is streamed dynamically grouped and may be utilized to identify significant patterns of change. Clustering techniques may be used to identify important patterns and events in the data.
- Social network analysis: In these applications, a social network is used in order to determine the important communities in the underlying network. Because it helps to understand the community structure in the network, community detection has vital applications in social network analysis. You can check my post about social network analysis below!

This was all from my side about clustering. If you want to learn more about clustering, check this out!
Keep learning!
This post may contain affilliate links.




