
Create your LLM API: your ChatBOT as a service — part 1
Master FastAPI and upgrade your LocalGPT to your NetworkGPT

We all dream about an AI genie living rent-free on our computer, crafting text magic at command. It may have sound like fiction, few months ago… But thanks to the democratizing power of open-source technology and platforms like Hugging Face, this fantasy is closer than ever.
Hugging Face provides a wide range of pre-trained models, including the Language Model (LLM) with an inference API which allows users to generate text based on an input prompt without installing or downloading very heavy model weights files on your computer.
But what if you want to install in your personal network an AI? And how can you turn the text generation into a service for everyone in your network? I mean, even without turning your projects into commercial use, maybe you want your personal business or organization to be able to make use of the AI powers.
Maybe you are a teacher, you develop a small chat-bot for learning and to make it available to the classroom: easy with fast API!
I tried for weeks testing tutorials and Youtube videos to find a way to create my own fastAPI service using a LLM installed locally: and I failed. So after several trials and error I found a way to do it! I decided to create a full Step to Step guide.
In Part 1 we will explore how to use FastAPI to host a local instance of the Hugging Face LLM. In part 2, that will be released very soon, we will see how to run it from a Streamlit app and from many apps in the same Local Area Network.

What is a FastAPI?
FastAPI is a modern, fast (high-performance), web framework for building APIs with Python 3.7+ based on standard Python type hints.
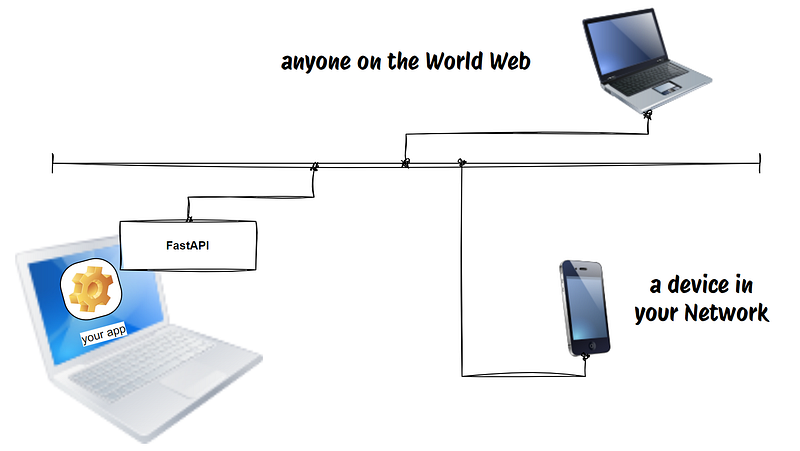
You create an application that does amazing things. The only way to use it is to have the app installed on your PC. Unless you create an API!
Basically you create a web access point where you decide what inputs you want to accept and what the output will be. The web access point (the API) will talk to your beautiful app (that still is only on your computer) and then send back the output to the user from the other part of the line from the web access point itself.
It is designed to be easy to use and to provide high performance, with automatic validation of request and response data, automatic generation of OpenAPI and JSON Schema documentation, and support for asynchronous code.
FastAPI it’s primarily designed for creating APIs, it can also be used to build interactive applications that provide a user interface to interact with machine learning models.
FastAPI is built upon two major Python libraries — Starlette (for web handling) and Pydantic (for data handling and validation).
NOTE: if you use LLMStudio or Ollama you already have this option out of the box. You can go in the settings and fire-up the API server with one single click. This will give you a fully functional OpenAI compatible API endpoint. This article is for any of you who want to learn how to do things from Zero.

Our roadmap
Here is an overview of the steps involved in building an interactive application using FastAPI:
Create a Virtual Environment and Install the dependencies
Download the LLM quantized version of tinyllama-1.1b-1t-openorca.Q4_K_M.gguf
Explore FastAPI basic setup and run the server
Create an endpoint with a LLM inference
Build the FastAPI endpoints to Integrate your LLM
Test the inferences with different applicationsCreate a Virtual Environment and Install the dependencies
As a good practice let’s create a virtual environment to handle our project as a sandbox. All the dependencies will be installed only in the venv.
Create a new folder called YourFastAPI and go into the directory
➜ mkdir FastAPIChat
➜ cd FastAPIChatInside the FastAPIChat folder create the virtual environment and activate it
python3.10 -m venv venv #create the virtual environment
source venv/bin/activate #activate the venv
if you are on Windows
python -m venv venv #create the virtual environment
venv\Scripts\activate #activate the venvNow it is time to install the libraries required:
- The llama-cpp-python library is responsible for running the quantized GGUF LLM and interact with it;
- fastapi[all], asyncio and sse-starlette are responsible for the creation of the API;
- and finally Streamlit will be used to create a webapp with a beautiful interface, in the next article.
pip install llama-cpp-python==0.2.39
pip install "fastapi[all]"
pip install asyncio
pip install sse-starlette
pip install streamlitDownload the LLM weights (tinyllama-1.1b-1t-openorca.Q4_K_M.gguf)
I explained in my previous article about the new series models called TinyLlama: they are tiny and very performing, and they can run on normal consumer CPU only. We will use anyway the quantized version, so that you can tweak the code later and run any other bigger model.
There are many smart ways to download the model weights, but in old school style let’s click on the download icon next to the file tinyllama-1.1b-1t-openorca.Q4_K_M.gguf from the Hugging Face model card page for TinyLlama-1.1B-1T-OpenOrca-GGUF. Save itin a new sub-folder called model.
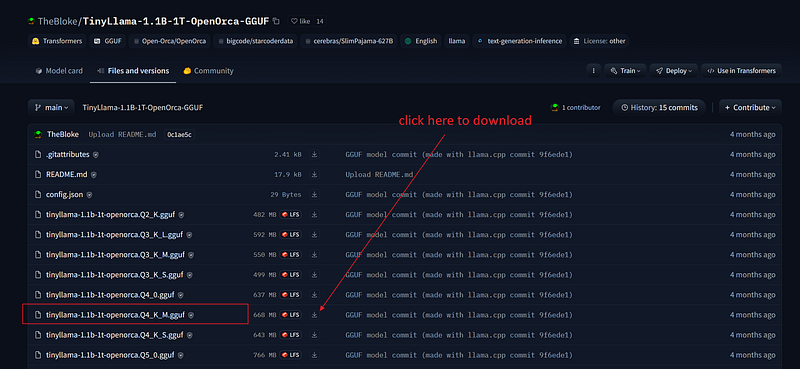
TinyLlama 1.1B 🐋 OpenOrca
This is one of the version of the TinyLlama family, trained on 1 Trillion tokens with the following datasets:
- Open-Orca/OpenOrca
- bigcode/starcoderdata
- cerebras/SlimPajama-627BI picked this model because it is very flexible, understands the instructions, and follows the ChatML template (we ill see about it later)
Create a file in the main folder called main.py and put the import instructions as follow:
# API import Section
from fastapi import FastAPI, Request
import asyncio
# LLM section import
from llama_cpp import Llama
# IMPORTS FOR TEXT GENERATION PIPELINE CHAIN
import copyGo to the terminal, with the venv activated and run python main.py If you don’t see any errors means that everything is set!
Your new folder should have the following files:

Explore FastAPI basic setup and run the server
Our first step is to test if the API server works. So we will create a basic endpoint, basically our point to communicate with the server sending a request and getting a response.
Inside main.py add the following lines to instantiate a FastAPI object:
app = FastAPI(
title="Inference API for TinyLlamaOO",
description="A simple API that use TinyLlama OpenOrca as a chatbot",
version="1.0",
)As you can see we are including some arguments, that are absolutely optional: a title, a description and a version.
Now, similarly to the instructions used in Flask applications, we create a call with the decorator @app.get() including the endpoint address, in our test it will be ‘/’, the root address.
@app.get('/')
async def hello():
return {"hello" : "Artificial Intelligence enthusiast"}And that is all! Really, this is already an API giving a reply when called at the root address.
Let’s test it. Save the main.py file that should look like this:
# API import Section
from fastapi import FastAPI, Request
import asyncio
# LLM section import
from llama_cpp import Llama
# IMPORTS FOR TEXT GENERATION PIPELINE CHAIN
import copy
app = FastAPI(
title="Inference API for TinyLlamaOO",
description="A simple API that use TinyLlama OpenOrca as a chatbot",
version="1.0",
)
@app.get('/')
async def hello():
return {"hello" : "Artificial Intelligence enthusiast"}Go to the terminal window and with the venv activated run:
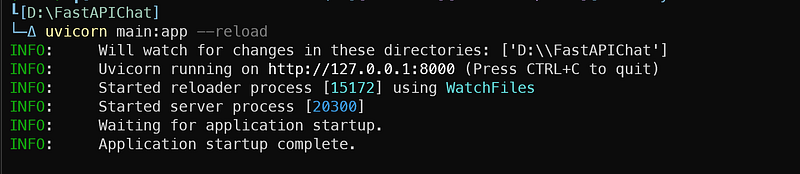
uvicorn main:app --reload
If everything works fine you should get the following messages:
This is the server side: to see the API in action we can open in a browser the mentioned address http://127.0.0.1:8000
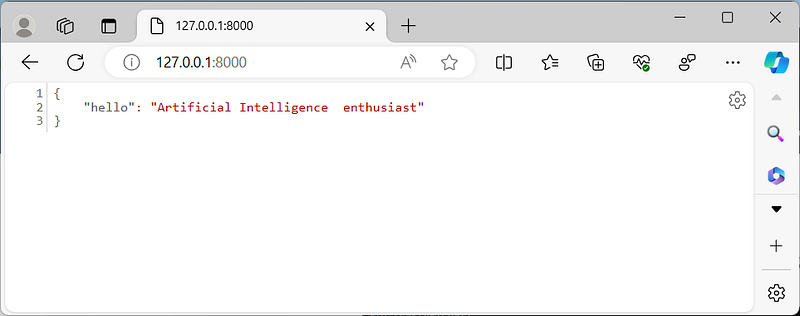
All the details of the API server endpoints are interactive. FastAPI provides an Automatic Interactive API documentation page that works when the server is active. Go in the browser to the address http://127.0.0.1:8000/docs
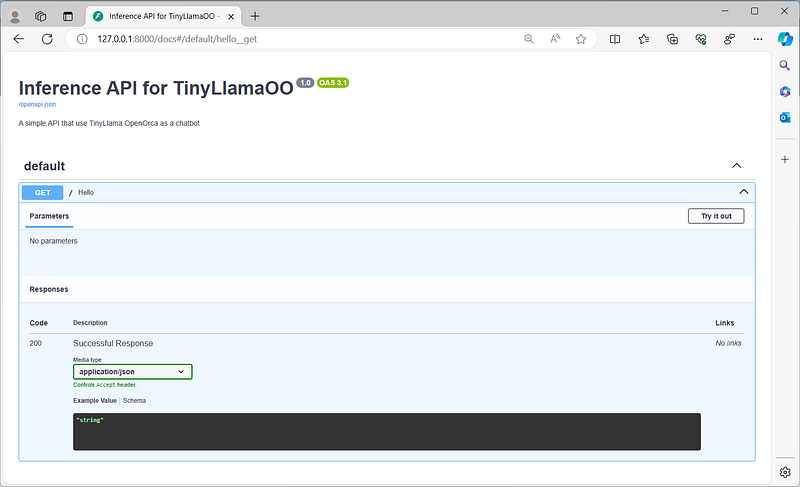
Our API documentation page displays its name, description, version, and a list of routes you can interact with. For now we have only one route. Let’s create a new one that include a fixed inference request to our model.
Create an endpoint with a LLM inference
How can we use FastAPI with our downloaded model? This is exactly what we do in this section. After loading with llama-cpp-python the GGUF model, we make it available for the inferences.
Keep the imports and add the code before the @app.get(‘/’)…
### INITIALIZING TINYLLAMA-OpenOrca MODEL
modpath = "model/tinyllama-1.1b-1t-openorca.Q4_K_M.gguf"
llm = Llama(
model_path=modpath, n_gpu_layers=0,
temperature=0.12, n_ctx=2048,
max_tokens=200,
repeat_penalty=1.4,
stop=["<|im_end|>",'</s>'],
verbose=False, #will not show the cpp loading process
chat_format="chatml",
)If you have ever followed some of my articles you shouldn’t find this too hard: if you are here for the first time… much better!
Here we prepare the model to be loaded. The most important thing here are the parameters:
model_path - is where the model file is
n_gpu_layers - 0 for CPU only, from 1 onward it will oflload
part of the model layers to the GPU
temperature - How creative you want the model to be (0 no creative, 1 creative)
top_p - Low top_p focuses on the most likely choices,
making the text smooth and consistent, but possibly less exciting.
n_ctx - is the context lenght, how many tokens a model is able to understand
at the same time
max_tokens - max number of tokens in the response that is allowed
repeat_penalty - This discourages using the same word repeatedly
stop - words used to avoid the llM goes crazy
verbose - do not show the loading logs
streaming - to allow the text to come during the generation
chat_format - is the prompt template format the model is expectingYou can read more in the article, if you want to go deeper.
Now every time we call llm(yourprompt) the inference will execute and provide you with the result.
We can add now a new endpoint that will reply with the Model text generation chain to a fixed question, simply to test it out.
@app.get('/model')
async def model():
text = "Who is Tony Stark?"
template = f"""<|im_start|>system
You are a helpful ChatBot assistant.<|im_end|>
<|im_start|>user\n{text}<|im_end|>
<|im_start|>assistant"""
res = llm(template)
result = copy.deepcopy(res)
return {"result" : result['choices'][0]['text']}Please NOTE that I am using a dedicate prompt format. For now we will use it like this: later we will use the create_chat_completionmethod with llama.cpp.
Our new endpoint will be at http://127.0.0.1:8000/model and will give us the TinyLlamaOpenOrca reply to the prompt “Who is Tony Stark?”.
I am putting here the file main.py but don’t worry you can find all the code into the GitHub repository.
# API import Section
from fastapi import FastAPI, Request
import asyncio
# LLM section import
from llama_cpp import Llama
# IMPORTS FOR TEXT GENERATION PIPELINE CHAIN
import copy
app = FastAPI(
title="Inference API for TinyLlamaOO",
description="A simple API that use TinyLlama OpenOrca as a chatbot",
version="1.0",
)
### INITIALIZING TINYLLAMA-OpenOrca MODEL
modpath = "model/tinyllama-1.1b-1t-openorca.Q4_K_M.gguf"
llm = Llama(
model_path=modpath, n_gpu_layers=0,
temperature=0.12, n_ctx=2048,
max_tokens=200,
repeat_penalty=1.4,
stop=["<|im_end|>",'</s>'],
verbose=False, #will not show the cpp loading process
chat_format="chatml",
)
@app.get('/')
async def hello():
return {"hello" : "Artificial Intelligence enthusiast"}
@app.get('/model')
async def model():
text = "Who is Tony Stark?"
template = f"""<|im_start|>system
You are a helpful ChatBot assistant.<|im_end|>
<|im_start|>user\n{text}<|im_end|>
<|im_start|>assistant"""
res = llm(template)
result = copy.deepcopy(res)
return {"result" : result['choices'][0]['text']}Save the file, go to the terminal window and with the venv activated run:
uvicorn main:app --reloadIf it was still running you just need to refresh the browser page. Now to test the new inference go to the address http://127.0.0.1:8000/model:
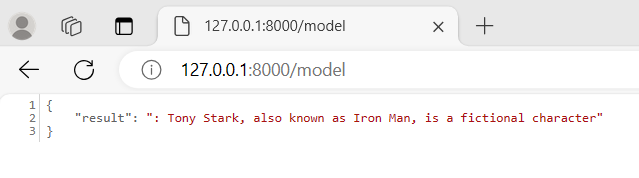
The automatic Doc page will give us some more details. Go in the browser to the address http://127.0.0.1:8000/docs to have a look at them:
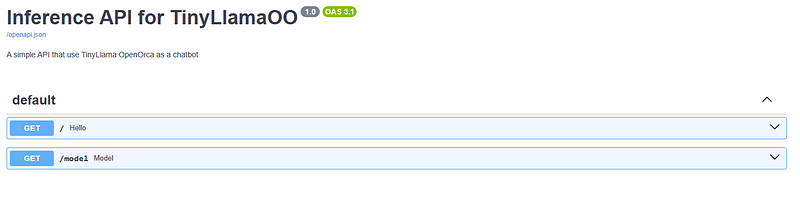
As you can see first of all there are 2 endpoints, and this is good. If we expand the GET method for /model we have something new…
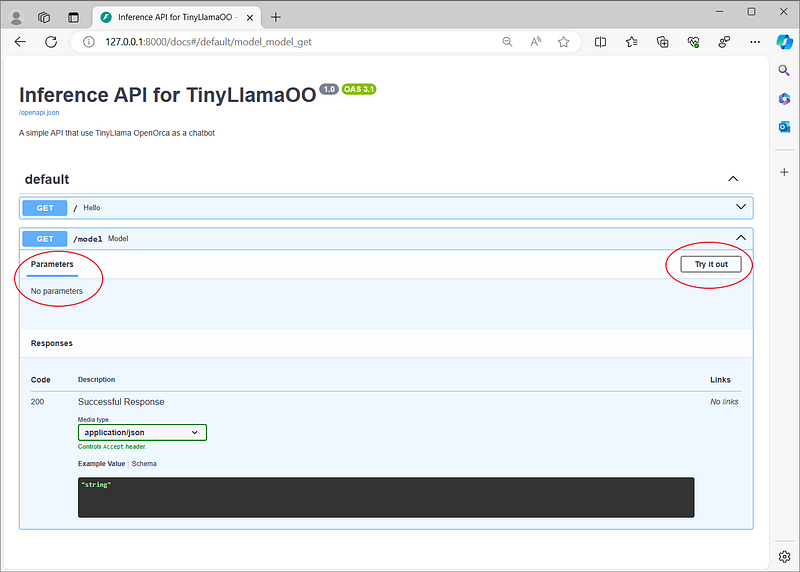
First of all we do not have any Parameters: this means that we cannot interact with the API (in fact we are giving a fixed input “Who is Tony Stark?…). On the right you see a button “Try it out“ but will not work because of no Parameters available.
In the next session we will enable this feature to interact fully with the model endpoint.
Build the FastAPI endpoints to Integrate your LLM
It is time to make the API interactive for us. We create a new endpoint for that, always as an async function (to make sure that is not executed only one time in the top-down execution order of the python script).
After the last endpoint add the following instructions:
@app.get('/tinyllama')
async def tinyllama(text : str):
template = f"""<|im_start|>system
You are a helpful ChatBot assistant.<|im_end|>
<|im_start|>user
{text}<|im_end|>
<|im_start|>assistant"""
res = llm(template)
result = copy.deepcopy(res)
return {"result" : result['choices'][0]['text']}Our entry point (endpoint) is /tinyllama. Now we need to give a Parameter to it that is the string variable text:
async def tinyllama(text : str):Here we still don’t use the chatML method in the endpoint, so we apply again the template to the newly created text parameter. Now we can run llm storing the result into the res variable.
template = f"""<|im_start|>system
You are a helpful ChatBot assistant.<|im_end|>
<|im_start|>user
{text}<|im_end|>
<|im_start|>assistant"""
res = llm(template)
result = copy.deepcopy(res)
return {"result" : result['choices'][0]['text']}NOTE about the indentation: the multi line string is sensible to the white spaces too. for this reason you see that I am not aligning the text in the template variable, trying to keep as much as possible the structure of the prompt as the model is expecting it.
To keep the function free for another request we immediately use copy.deepcopy,that, as stated in official documentation…
Assignment statements in Python do not copy objects, they create bindings between a target and an object. For collections that are mutable or contain mutable items, a copy is sometimes needed so one can change one copy without changing the other. This module provides generic shallow and deep copy operations…
Finally we return the result.
Save the file, go to the terminal window and with the venv activated run:
uvicorn main:app --reloadIf it was still running you just need to refresh the browser page. Now to test the new inference go to the address http://127.0.0.1:8000/tinyllama:
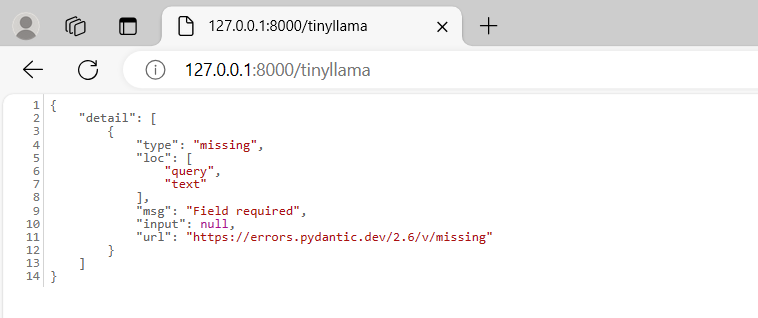
we are getting and error message! Don’t panic! it is normal, because we are not really sending any content to the FastASPI.
Go in the browser to the address http://127.0.0.1:8000/docs and expand the GET method for the /tinyllama endpoint. Now we can see that there is a parameter called text. We can click on Try it out and input a question to send to the API.
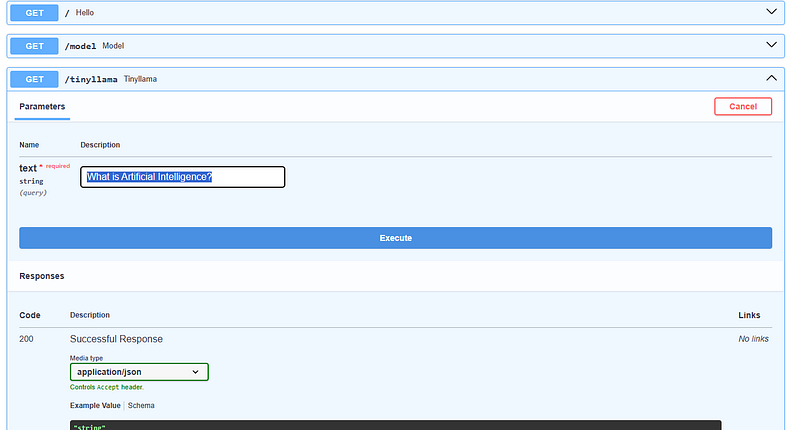
Let’s try with “What is Artificial Intelligence?“ and click on Execute
Clicking on execute will run the LLM inference under the hood. A brand new set of sections will appear, including our reply, a curl instruction and a request URL
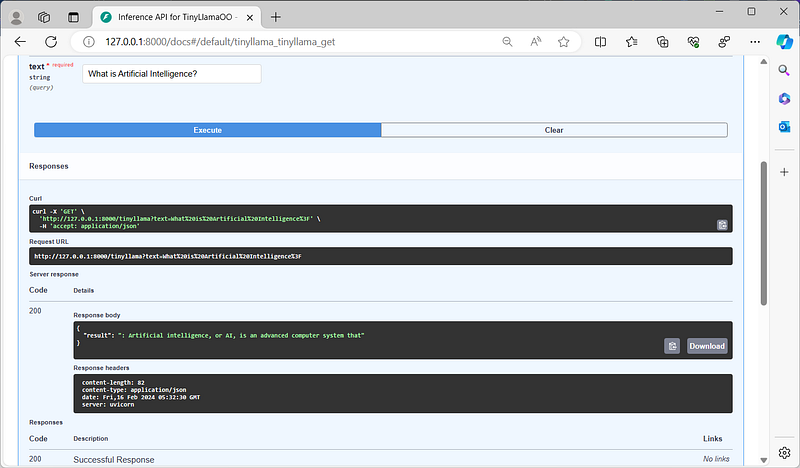
Did you noticed that the response looks like it is truncated? BRAVO! It is indeed cut.
This is because we need to pass the generation arguments during the inference call. It must be something like this:
res = llm(template,temperature=0.42,repeat_penalty=1.5,max_tokens=300)If we don’t include in the inference call llama.cpp will use the default ones. So we can remove them from the instantiation of the class, and simply add them in the /tinyllama endpoint call.
### INITIALIZING TINYLLAMA-OpenOrca MODEL
modpath = "model/tinyllama-1.1b-1t-openorca.Q4_K_M.gguf"
llm = Llama(
model_path=modpath, n_gpu_layers=0,
n_ctx=2048, verbose=False,
stop=["<|im_end|>",'</s>'],
chat_format="chatml",
)
@app.get('/')
async def hello():
return {"hello" : "Artificial Intelligence enthusiast"}
@app.get('/model')
async def model():
text = "Who is Tony Stark?"
template = f"""<|im_start|>system\nYou are a helpful ChatBot assistant.<|im_end|>\n<|im_start|>user\n{text}<|im_end|>\n<|im_start|>assistant"""
res = llm(template)
result = copy.deepcopy(res)
return {"result" : result['choices'][0]['text']}
@app.get('/tinyllama')
async def tinyllama(text : str):
template = f"""<|im_start|>system
You are a helpful ChatBot assistant.<|im_end|>
<|im_start|>user
{text}<|im_end|>
<|im_start|>assistant"""
res = llm(template,temperature=0.42,repeat_penalty=1.5,max_tokens=300)
result = copy.deepcopy(res)
return {"result" : result['choices'][0]['text']}I just pasted it again so you can see. Let’s save the file and re-run uvicorn
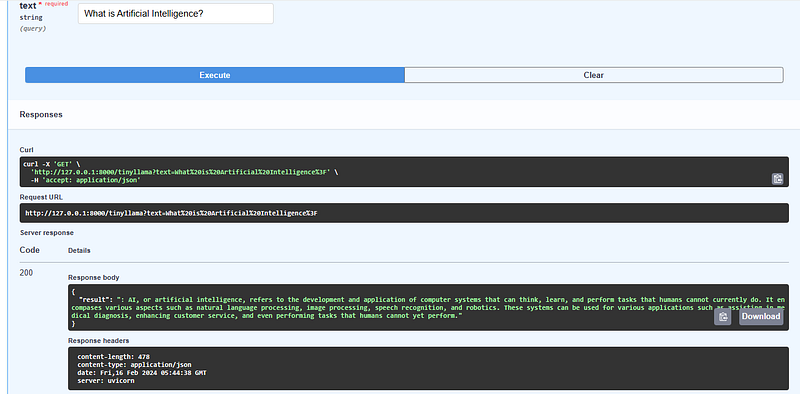
Here the sections. The Server Response with the response body:
AI, or artificial intelligence, refers to the development
and application of computer systems that can think, learn,
and perform tasks that humans cannot currently do.
It encompases various aspects such as natural language processing,
image processing, speech recognition, and robotics.
These systems can be used for various applications such as assisting
in medical diagnosis, enhancing customer service, and even performing
tasks that humans cannot yet perform.and the Request URL
http://127.0.0.1:8000/tinyllama?text=What%20is%20Artificial%20Intelligence%3F
Do you want to know why I pasted the above Request URL here? In the next session you will understand 😏

Test the inferences with different applications
With my surprise you can use a browser to get your response from the LLM FastAPI. So in this section we explore together 2 common methods.
URL Request
The Request URL is amazing: we can open our browser and simply input our question to the LLM writing it in the address bar after ?text=
http://127.0.0.1:8000/tinyllama?text=What%20is%20Artificial%20Intelligence%3F
So if you open a new browser tab with the following address:
http://127.0.0.1:8000/tinyllama?text=generate a paragraph describing why data science is important
We are sending the question “generate a paragraph describing why data science is important“. I got this response
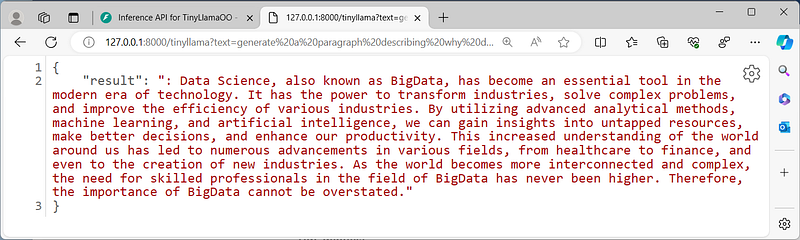
HINT: If you are good at HTML/CSS and JavaScript you can build your web interface handling a simple URL request.
Conclusions and way forward
In my next article we will use the template from my previous project to create a Streamlit Chat app that runs over the FastAPI we created. And you will be able to call it over your Local Network!
You can find the code and resources in my GitHub repo (it will include also the code related to part 2! )
Hope you enjoyed the article. If this story provided value and you wish to show a little support, you could:
- Clap a lot of times for this story
- Highlight the parts more relevant to be remembered (it will be easier for you to find it later, and for me to write better articles)
- Learn how to start to Build Your Own AI, download This Free eBook
- Sign up for a Medium membership using my link — ($5/month to read unlimited Medium stories)
- Follow me on Medium
- Read my latest articles https://medium.com/@fabio.matricardi
If you want to read more on the topic here some resources:
References and inspirations
https://readmedium.com/building-and-deploying-a-fastapi-app-with-hugging-face-9210e9b4a713
https://github.com/mafda/ml_with_fastapi_and_streamlit/tree/main
https://www.freecodecamp.org/news/how-to-deploy-an-nlp-model-with-fastapi/

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together!





