
Transfer Knowledge Graphs to Doctor.ai
Expand Doctor.ai with Hetionet, STRING and KEGG
This article shows how to:
1. Integrate three public knowledge graphs into a medical chatbot — Doctor.ai.
2. Ask Doctor.ai about medical histories, pathogens, drugs and genes using natural language via AWS Lex.

The ongoing COVID-19 pandemic has taught us many valuable lessons. One of them is that we need to modernise our healthcare system and make it more accessible to all people. Governments around the world have thrown a huge sum of money into digitalisation (here and here). But two years into the pandemic, rich countries such as Germany still use fax and buggy software in their hospitals to transmit data. This glaring technological gap costs lives.
In December 2021, four Neo4j engineers and I created a chatbot called Doctor.ai based on the eICU database (read details here and here). Doctor.ai can manage a huge amount of medical records for both patients and doctors. Through AWS Lex, users can quickly query their own medical histories, while the doctors can even ask for treatment recommendations. The database contains many different types of data: demographic information, ICU visit details, lab results, pathogen identifications, diagnoses and treatments. Even so, we were able to put them all into just one Neo4j knowledge graph. Unlike the other table-based databases, the graph gave us the freedom to construct and execute highly complex queries with ease.
But this first version of Doctor.ai had a very limited scope of knowledge — just the eICU records and some predefined medical FAQs. So how can we make it more knowledgeable? We can put new data into its graph. Many tutorials in Medium taught us to use natural language processing (NLP) to scrape websites such as Wikipedia for automatic knowledge graph construction. Even though NLP can generate draft graphs quickly, rigorous curation and fact-checking are needed to ensure their correctness. And nowhere else does correctness matter more than in the healthcare domain, where accurate information is often a matter of life and death.
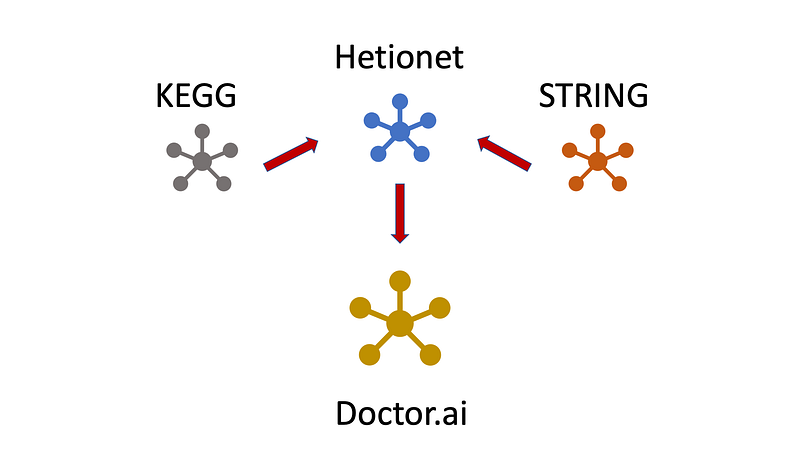
But we can have a second easier approach. There are some public and well-curated knowledge graphs on the internet, such as Hetionet, STRING and KEGG. Why not just transfer these data into Doctor.ai? Doctor.ai will then gain knowledge about drug-drug interactions, drug side effects, gene-gene interactions on top of all its medical records. In this article, I am going to show you how to integrate all these three databases into Doctor.ai. You can find the data and my code in my repository here.
And the integrated knowledge graph dump is here:
https://1drv.ms/u/s!Apl037WLngZ8hhj_0aRswHOOKm0p?e=7kuWsS
1. Data sources
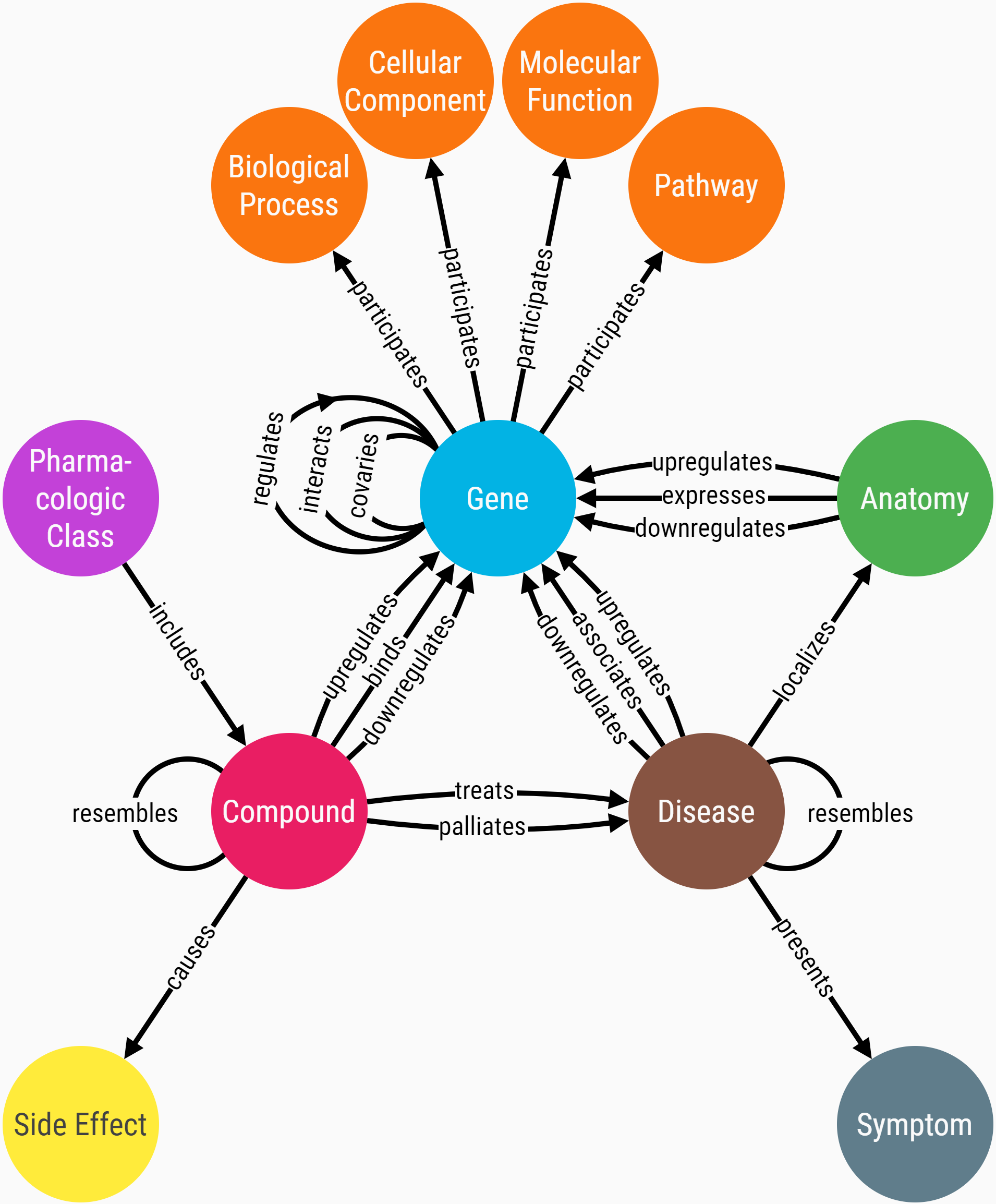
The Hetionet database is a comprehensive medical knowledge graph. It was developed by Daniel Himmelstein and collaborators in the Baranzini Lab at the University of California, San Francisco. It connects 47,031 nodes with 2,250,197 edges of 24 different types: gene, disease, compound, anatomy, side effect and so on (Figure 2). In this article, I will use Hetionet as the backbone.
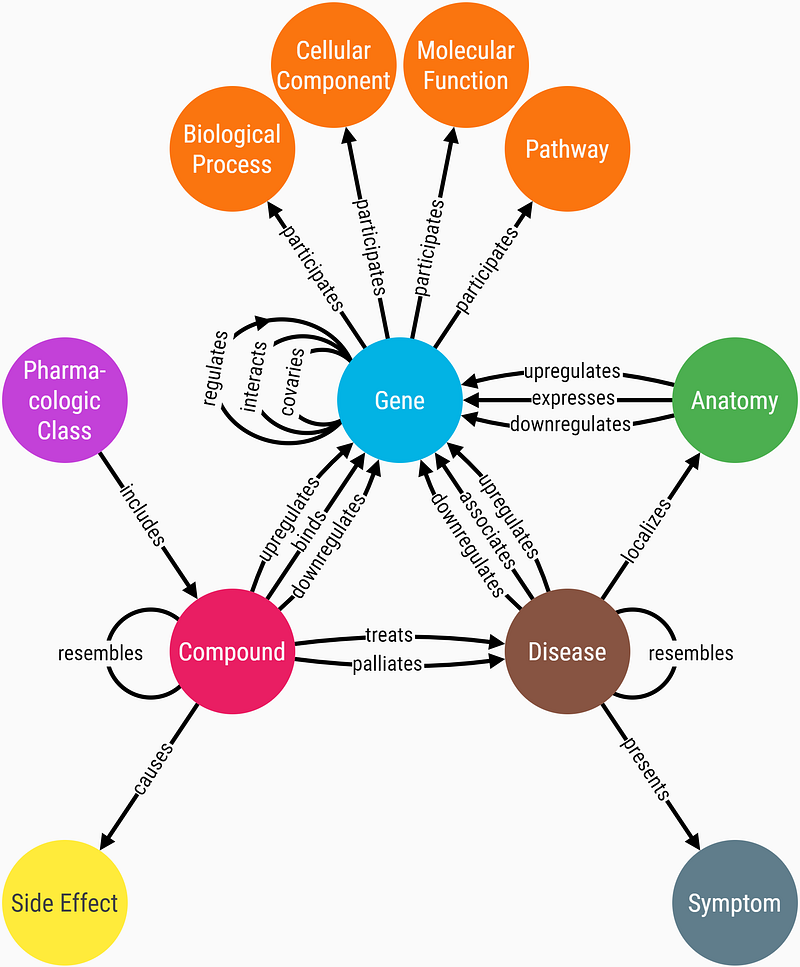
However, Hetionet itself also needs an update. The last update of Hetionet was in 2018. Its Neo4j package is in the 3.x format. We can also greatly enrich its gene-gene interaction with some external data. Finally, it only contains 137 diseases. And data about infectious diseases and their causative pathogens are completely absent.
For this reason, I will bring in two more databases: the STRING database and the KEGG disease database. The STRING database collects data about protein-protein interactions. It contains 67 million proteins and 20 billion interactions. The KEGG disease database currently contains over 2500 diseases, which I also investigated previously in Neo4j. It also contains data about infectious diseases and their pathogens, including COVID-19. Finally, KEGG has also integrated drugs and genes into its knowledge graph.
Hetionet is released as CC0. STRING is freely available under a ‘Creative Commons BY 4.0’ license, while academic users may freely use the KEGG website.
2. Integrate the three data sources
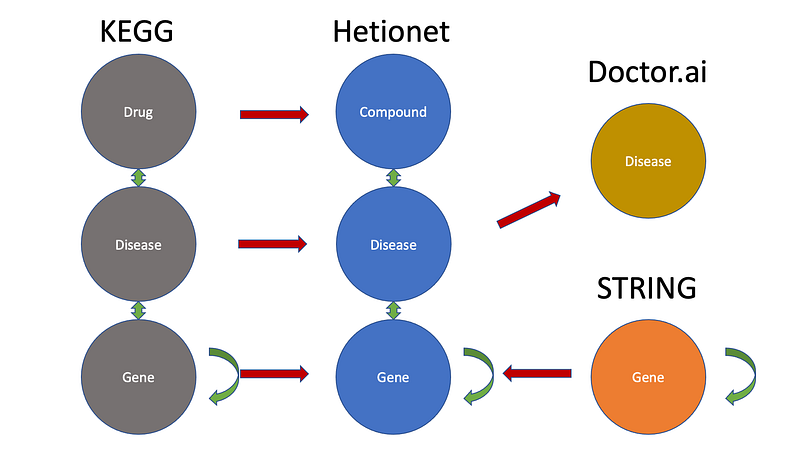
It is not easy to integrate different knowledge graphs because they can use different identifiers to describe the same concept. In our case, the Hetionet database indexes diseases with the DOID, compounds with the DrugBank ID and genes with the Entrez Gene ID. Both KEGG and STRING databases have created their unique identifiers. Fortunately, biomedical researchers have gradually agreed on controlled vocabularies and standardised the naming for genes, pathogens and other concepts. For this reason, I will merge nodes based on their name properties instead of their original identifiers. So I first standardised the names among the three data sources (source code in my repository).
I have attempted to import the Neo4j data dump of Hetionet by following every step in this tutorial. But it failed every time with the “database not cleanly shutdown” error. Then I decided to download its JSON. It turned out to be a better solution because I could edit its content. I have set the node name as identifiers and modified the edge definitions accordingly.
Then I imported this modified Hetionet into Neo4j 4.3.6. The import of 2.2 million relations took hours to complete. I recommend you to do this on AWS EC2 (the CloudFormation template is in my repository). And don’t forget to create a dump for this 4.3.6 version as a backup.
After the import, we can see that there are 20,943 genes, 137 diseases and 1,552 compounds in Hetionet.
Next, download the two STRING datasets for Homo sapiens.
The STRING database assigns a score to each protein-protein interaction based on diverse evidence channels such as experiment, co-expression, homology and others. A score of 0.5 would indicate that roughly every second interaction might be erroneous (i.e., a false positive). In the downloaded links data however, the scores are multiplied by 1,000. In this project, I removed connections with combined_scores below 900 before the import.
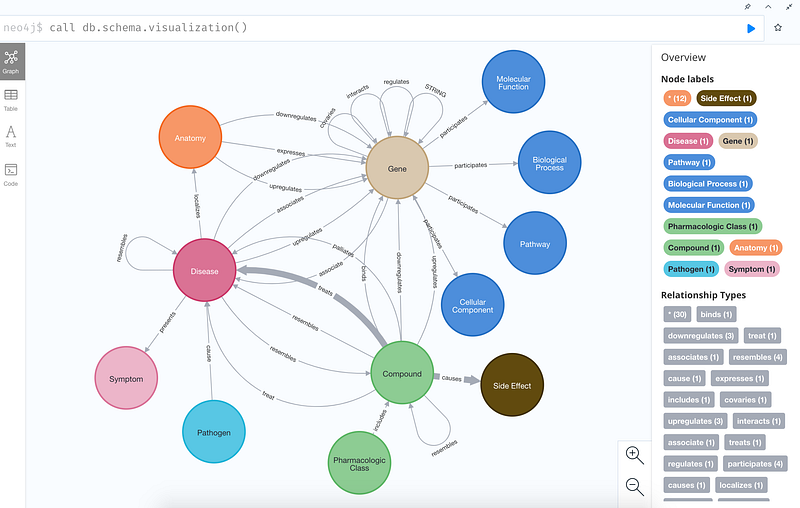
The integration of the KEGG Disease database was more involved. I have downloaded the data via KEGG API as described in my previous project. This time I need to link the entities with names instead of their KEGG identifiers. Afterwards, I import the data into the knowledge graph. After Hetionet gobbled up STRING and KEGG, its amounts of nodes in the “Disease”, “Compound” and “Pathogen” increased substantially (Table 1). Also the amount of connections has increased. 123,577 pairs of STRING gene-gene interactions have been created. The amount of the treats relations increased from 755 to 3,363, while the number of causes increased from 138,944 to 139,376.
3. Connect the knowledge graph with Doctor.ai
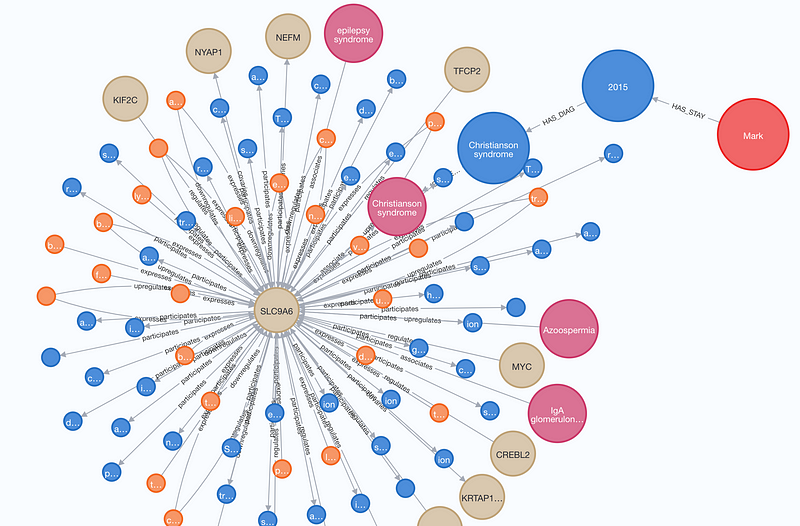
Now my “Hetionet + STRING + KEGG” knowledge graph is complete. It is time to connect it with Doctor.ai. I set up the AWS infrastructure via CloudFormation as described in my previous article (template is in my repository). The original stand-in data in Doctor.ai was the eICU dataset. The applicants must finish an online course and then wait for the approval. In this article, I am going to just create two fictive patients based on the eICU data to demonstrate the new Doctor.ai. Patient №1 Lucy had the Kyasanur Forest disease, while Patient №2 Mark suffered from Christianson syndrome (Figure 6).
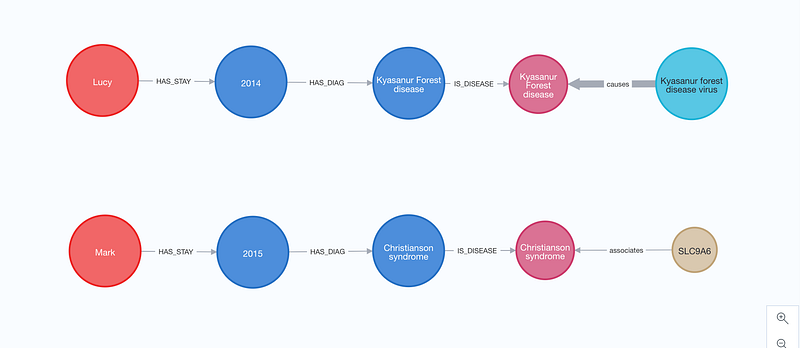
Once their medical records were imported into Doctor.ai, I conducted the following two conversations (Figure 7).
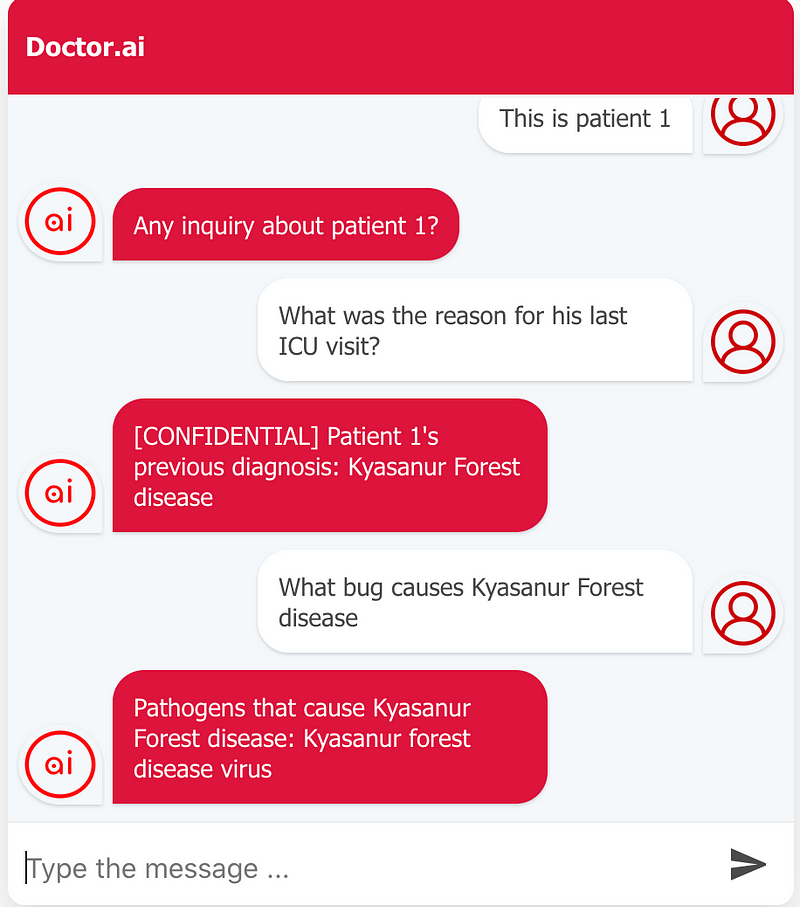
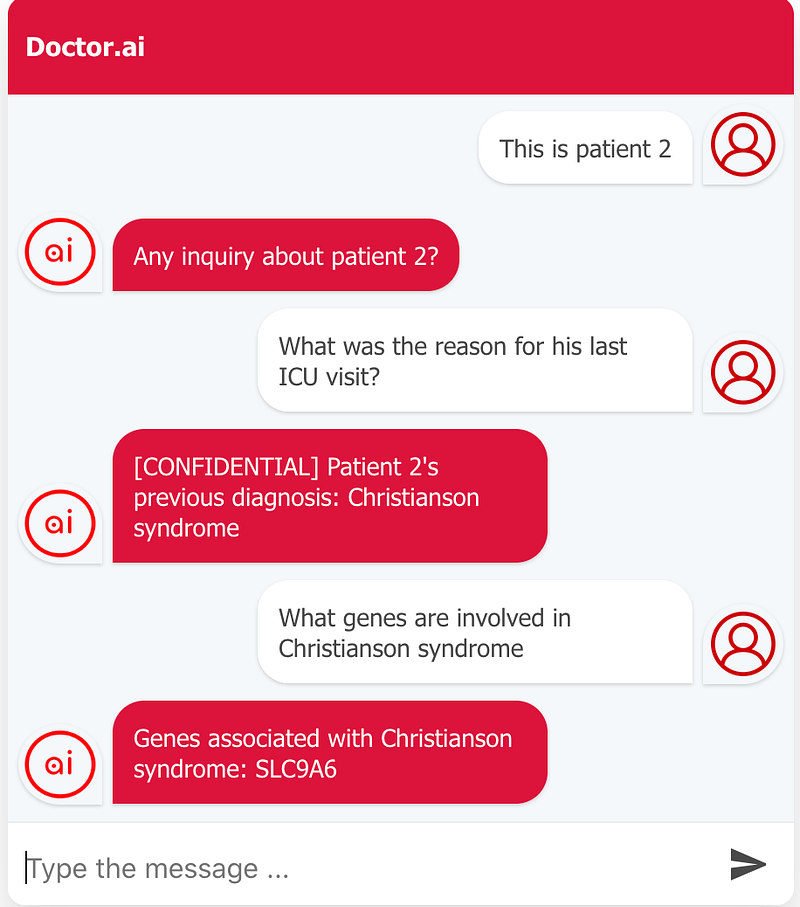
As you can see in Figure 7, Doctor.ai first found their medical records. And thanks to the new knowledge graph, it could then give further details about these ailments, too. In the first case, it reported back the pathogen, while in the second case, it could say the gene SLC9A6 is involved in Christianson syndrome.
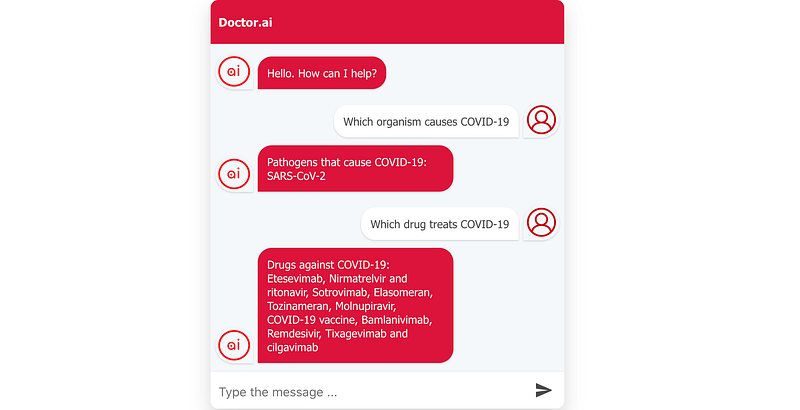
Next, I asked Doctor.ai about the subject of these last two years — COVID-19. As you can see, Doctor.ai could not only name the causal pathogen SARS-CoV-2, but also present a list of drugs against the disease. All this data came from the KEGG database.
Under the hood, we can see the limitation of AWS Lex. Currently, Lex’s built-in slot type Alphanumeric cannot recognize spaces out of the box. So “Staphylococcal infection” or “Herpes simplex virus infection” were not correctly elicited (see post here). I worked around this limitation by defining my own slot type and entering all two thousand disease names as candidate values.
Conclusion
Things are easier to learn when they are in networks. And this small project effectively plugs Doctor.ai into the general medical knowledge universe (Figure 9). And instead of building one from scratch with NLP right away, why not integrate the existing ones first? Doctor.ai was a chatbot that managed one specific type of data — medical records. In its first debut, Doctor.ai answered factual questions with the help of AWS Kendra, which retrieves predefined answers to the users. It is very expensive ($810 per month) too. By embedding research data from Hetionet, STRING and KEGG, it has acquired general medical knowledge very cost effectively. With this enlarged knowledge, Doctor.ai can not only report the details of past hospital visits to the patients and the doctors, but also provide them with information about pathogens, drugs, side effects and genes. Although this still does not make Doctor.ai an open-domain chatbot, it is a solid first step in that direction.
There are rooms for improvement though. The data integration in this project is rudimentary. Data entries can be cleaned further. For example, many diseases in Hetionet and KEGG do not have the ICD-10 classification. That made the data merging difficult. Since the ICD-11 has already come into effect since 1 January 2022 and KEGG has already incorporated this new standard, we’d better quickly adapt it for the future.
You can expand Doctor.ai too. Currently, there is only very little data about psychiatric disorders in our dataset. In fact, compared to physical ailments, data about mental health are scarce everywhere on the internet. So patients with mental disorders have been long underserved. And patients are numerous: nearly one in five American adults lived with a mental illness in 2020. So there is an urgent need for us to collect more data in this area. Also, the drug-drug interaction can be further augmented with data from the DrugBank. The CARD antibiotic resistance data is also a nice integration candidate. In summary, there are many expansion directions for Doctor.ai.
Finally, the idea of combining specific and general knowledge graphs is not limited to Doctor.ai for healthcare. With suitable data, we can use the same infrastructure for other areas: from veterinary medicine to forestry, from bank to HR and from logistics to manufacturing. However, decision makers need to consider not only technology, but also ethics and legislations in each of these new use cases.
Update: in this new article, I made Doctor.ai into a diagnosis tool based on symptoms or gene mutations with data from these transferred knowledge graphs.
This article uses GPT-3 as NLU to improve performance, reduce development time and shrink code.





{kind=link}