

An Insight into the Criteo AI Lab
An article by Morgane Goibert, Alberto Lumbreras & Flavian Vasile from Criteo
The Criteo AI Lab is pioneering innovations in computational advertising. Within this center of scientific excellence, distributed across Paris, Grenoble, and Ann Arbor, our researchers and engineers deliver both fundamental and applied scientific leadership through published research, product innovations, and new technologies powering the company’s products. We are believers of the open internet and we want to shape an adtech industry that has to be open, inclusive, transparent, and privacy-preserving.
Criteo AI Lab in numbers:
- 90 permanent & part-time, 9 PhDs
- DNA: 35 researchers, 55 engineers
- Locations: Paris, Grenoble, Ann Arbor
Our research is focused on providing Criteo with the power and agility to provide best-in-the-world adtech machine learning models that can create better user experiences and help advertisers form deeper connections with their customers. The adtech world has been one of the major fields where machine learning has been pushed to its limits in terms of scale and real-world performance. In our world, many of the classical statistical assumptions do not hold and many algorithms do not scale. Our group is constantly faced with questions such as: How do you deal with 250 billion requests per day? How do you compute a recommendation of 1 billion products and 1.5 billion users in less than 50ms? In this world, everything needs to be rethought, from the models to performance metrics.
Research at Criteo AI Lab
Our Criteo AI Lab research agenda covers a large variety of topics, from ones that are widely studied in the Machine Learning community, to more specific topics highly related to the Criteo business. They range from Optimization, Transfer Learning, Natural Language Processing, and Computer Vision to Recommendation, Incrementality, and Auction Theory.
For the rest of the blog post, we will cover three ongoing research projects that will give you a glimpse into the activities of our group.
1. Helping you avoid crashing your car: Criteo’s got your back
Like many of our peers, many of us work on Deep Learning, an area of Machine Learning that studies Neural Networks (NNs), a class of models that were originally inspired by the biological neural networks. They have shown their ability to perform a large variety of tasks such as image-related problems (image annotation, face recognition, etc) or natural language processing, face recognition. At Criteo for instance, these models are used to do image-based product blacklisting to prevent inappropriate content to be advertised — which is done with an unprecedented level of reliability — and they also are at the core of the engine recommending products to users.
If NN performances are great and widely used when dealing with images, they raise a major challenge: they are vulnerable to small and possibly malevolent perturbations of the original input data (images, but also other types of data like audio, words and so on)
The following images illustrate how this can manifest. With the existing arsenal of NN models, training algorithms, and image collections available, training a model capable of inferring which animal is shown in an image is straightforward. Here, the model predicted the correct label (a panda) to the left image with high confidence (57.7% is a great score, considering the number of different animals in the data). But a slight perturbation, shown in the middle, results in the image on the right. The difference between the leftmost and the rightmost images are imperceptible to the human eyes, because the perturbation is very small. However, for the neural network, the image is now a gibbon, with an overwhelming 99.3% confidence.
Yes, this means that one can lie more efficiently to a neural network than to her mum… or more precisely, the way to lie to an NN and to your mum are not the same, and the former can be done mathematically.
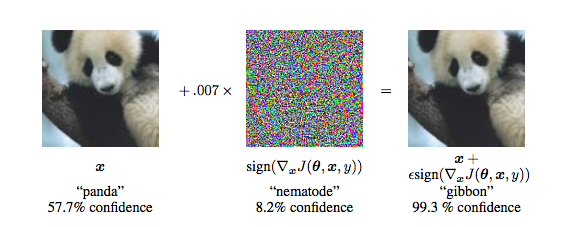
These fooling images are generally called Adversarial Examples, and they can pose major security issues for concrete applications. For example, would you board on a plane if the automatic recognition and security process in the airport might think a rifle is just a teddy bear? The risk for Criteo is to see the performances of our blacklisting models and recommendation systems drop drastically. This could happen if we were to be the target of hackers but, maybe worse, it could be caused “naturally” and unintentionally, by the collection of input data (e.g. user history) that may inherently contain unexpected and “weird” information.
In addition to being able to deploy products and services robust to these examples, investigating this phenomenon may lead to a better understanding of these algorithms. As a result, we could have simpler algorithms that would take less time and energy to solve the same task, we could create smarter models able to better understand what is important in their objective, and so on. In other words, it could help Criteo design better, more reliable, and less expensive components in our AI stack.
Our goal is thus threefold:
- To prevent Neural Networks from being vulnerable
- To create algorithms that can detect when an image is an adversarial example
- To gain a deeper understanding of this phenomenon
One of our latest projects on this topic focuses on providing a very simple and fast robustification method to prevent the algorithm from being vulnerable. The classical training method of Neural Networks consists in showing images as well as labels to the algorithm (meaning that we provide the NN with the answer “this image is a dog”). Our robustification method modifies this training procedure: instead of supplying an assertive label to the algorithm, we give it more uncertain labels (e.g. “I’m 80% sure it’s a dog, but there is a small chance it’s a cat or a horse”).
The NN algorithm gets used to being uncertain in its predictions, and as a result, gets more careful less vulnerable to problematic adversarial examples.
This project materialized into a research paper submitted to ICML 2020, a major conference in the field of Machine Learning, and will be integrated into our image processing pipeline. The main strength of this method is that not only does it help to regularize and robustifying the Neural Network, but it is also very fast, and therefore cost less in terms of computing time and power. It is thus very easy to use in production without any unwanted side effects.
2. Domain Adaptation, or how to train for the Olympic Games in a hotel pool
In the 2000 Summer Olympics, the name of Éric Moussambani hit the headlines. This swimmer made the slowest 100m freestyle in history. “The first 50 meters were OK”, he said, “but in the second 50 meters I got a bit worried and thought I wasn’t going to make it”. Éric’s Olympic training started a few months before, in a 20m hotel pool in his hometown. He had never swum in a 50m pool before the day of the competition. Once in Sydney, he had to transfer the swimming expertise he acquired in the 20m pool to the Olympic 50m pool — -something he wasn’t able to do gloriously.
This problem of seeing expertise acquired in some situations carrying over to another one is known, in machine learning, as the Domain Adaptation problem (a particular case of Transfer Learning). Machine learning mostly relies on the hypothesis that the statistical properties of the data on which a model is trained are identical to the one on which the model will make its predictions. Violation of this condition is not the monopoly of sports.
In medical diagnosis, for instance, models are often trained over a subset of the population that is not representative of the full population. We say that the domains are different. For example, if the people in the training set are younger or healthier than the average population, we should be able to somehow tell the model, such that it takes this bias into account. Domain adaptation is a subfield of machine learning that seeks to address this problem in its general form.
At Criteo, this problem appears in almost every product, both in space and time. For instance, consumer behavior can change from one country to another, as well as our users’ past activity may not be representative of their future behavior.
Furthermore, we are expanding the toolbox of domain adaptation to address additional issues, such as having missing features in all or part of the test data. Technically speaking, the problem is caused by a change in the distribution of features, such as temperature and pool length, from one domain to another. One of the approaches to solve this uses Optimal Transport (OT). Imagine we are learning a classifier that is able to distinguish between two classes (crosses and circles in the figure below, where horizontal axes represent temperature and vertical axes represent length). The Optimal Transport approach to Domain Adaptation learns which function T should be used to transport the source features into the positions of the target features. Then, it applies the same transformation T to the learned classifier (green line).
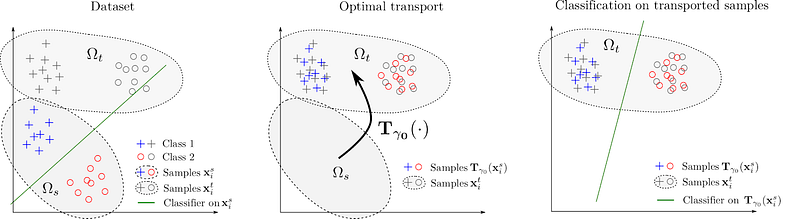
Another approach is to automatically learn a set of features that has similar statistical properties across the different domains. How can you train a model that makes a feature domain-invariant if you don’t know how it will look like in the test domain? Most domain adaptation approaches make hypotheses that do not hold in some real-world datasets.
For instance, when deploying an automated diagnosis system, they assume that the proportion of the population that will contract a given disease is similar across the world. Similar situations hold for computational advertising as some categories of users behave differently across ages and countries.
Our current work consists of designing algorithms able to account for these discrepancies. As the next steps, we plan to submit the result of our work to NeurIPS 2020, so stay tuned!
3. Representation Learning: Fighting prosopagnosia
In November 1944, Dr. Bodamer received a German soldier that was injured at the rear of the brain. Among many other cognitive disorders, the soldier could not recognize faces. Dr. Bodamer would show him several pictures of people, but the soldier only saw blurred faces. After exhaustive experiments, the soldier was able to recognize three people. His wife -by her eyes — , a nurse — by her teeth — and Hitler — by his mustache and his side-parting hairstyle. Dr. Bodamer called this prosopagnosia (from Greek prósōpon, meaning “face”, and agnōsía, meaning “non-knowledge”). People with prosopagnosia can detect some particular local features of a face, but they can not see them as a whole.
Machines are born prosopagnosic. They see a vector of features as a collection of values with no relation between them. In the simplest cases, notably in the realm of so-called linear problems, this is enough to make predictions. Unfortunately, you can hardly distinguish a dog from a cat in a picture if you look at it pixel by pixel and if you do not consider spatial (even distant) relations between them. Representation learning, or automated feature engineering, is the machine learning approach to overcome prosopagnosia.
At Criteo, one of the applications of representation learning is the enrichment of our description of the data (the feature vectors). First, our feature engineering pipeline discretizes each feature into a set of categories or modalities. Then, it combines some of them to create new features, a process known as feature crossing. Hopefully, the new set of features, that contains the crossed and the original ones, is more informative than the original ones alone, and patterns are easier to detect by models trained on them. In case you are thinking you can use brute force and try all possible crossings, you should know that some features have up to ten million modalities. Crossing two of those features generates a new feature of 10^14 modalities. As many as the number of synapses in a human brain! The generation of cross features is therefore infeasible or not handable in a learning process using a brute force approach.
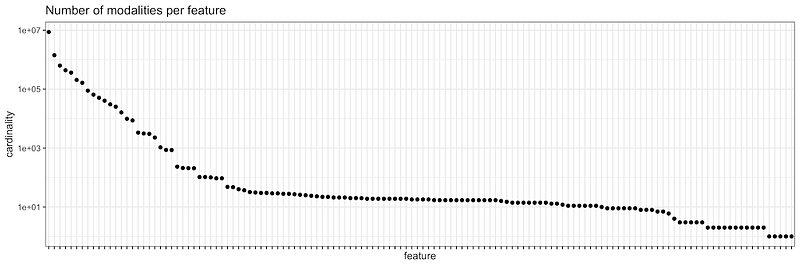
After years of continuous feature engineering, we have found very good crosses and our predictions are incredibly good, but unfortunately, this is a costly, time-consuming task, and many informative crosses might never be found. Modern representation learning tools are helping us reduce this burden. We are currently exploring deep generative models, such as Variational Autoencoders, that learn representations of the data in a smaller latent space.
The better we get at this, the more we can reduce costs, increase models performance, and build new products.
We close this blogpost with one of our guiding principles, which is…
Sharing with the community!
As you saw with this excerpt of a few topics, our group’s research is diverse and impactful.
And, for each one of our research projects, we do our best to share our findings with the research community, either through a paper publication or by open-sourcing software, releasing datasets or organizing workshops and giving specialization courses. In the Criteo AI LAB, we strongly encourage publications on both fundamental or applied research tracks, with a totally open publication policy and a simple dataset releasing methodology.
To the date, we hold the record for releasing the world’s largest public machine learning data set at one terabyte in size and 4 billion event lines.

Just in 2019 alone, our group published more than 14 full papers at top-tier conferences and venues (NIPS, ICML, AAAI — for more see here) and organized conferences and workshops such as Machine Learning in the Real-World or REVEAL at RecSys, organized a Machine Learning challenge, gave courses at summers schools such as DS3 and RecSys Summer School.

Beyond publications and organizing events, we encourage our group to attend conferences because we believe having contact with their peers at large and exchanging ideas helps them grow as researchers and frankly because it is tons of fun!


At Big Data Convergences days 2019 Patrick presented his work entitled Connections between Deep Learning models and Differential Equations for modeling dynamical systems have recently motivated several developments for the industry.
We hope you enjoyed this short overview of our group research activity and we close with a couple of links to our open research activities:
Thank you and see you soon!
Interested in joining the fun of the Criteo AI Lab? Check out our open roles:
Or, take an insight into our other teams in similar articles: