
You Can Be Identified by Your Netflix Watching History

On October 2, 2006, Netflix announced the $1-million Prize for improving its movie recommendation algorithm. Netflix released an anonymous dataset containing movie ratings by 500,000 subscribers. Netflix asserted that all personally identifiable information (PII) has been removed. Is the removal of PII sufficient to protect data privacy? One year later, Arvind Narayanan and Vitaly Shmatikov (Narayanan & Shmatikov), two researchers at the University of Texas at Austin, proved the removal of PII is useless in protecting data privacy. They used the Internet Movie Database (IMDb) as the external source to identify the anonymous Netflix subscribers. Sensitive individual information such as subscribers’ political preferences can be uncovered. How do they do that? This sobering truth alerts the academia as well as practitioners, and paths significant research literature called Differential Privacy and Private-Preserving Machine Learning. This article explains how the two researchers open the floodgate.
It is worth mentioning that there are two emerging trends in AI: “Differential Privacy” and “Explainable AI”. On Differentiated Privacy, Dataman published “You Can Be Identified by Your Netflix Watching History” and “What Is Differential Privacy?” and more to come in the future. On Explainable AI, Dataman has published a series of articles including “An Explanation for eXplainable AI”, “Explain Your Model with the SHAP Values”, “Explain Your Model with LIME”, and “Explain Your Model with Microsoft’s InterpretML.
You Can Be Identified by What You Watch
Removing identifying information is not sufficient for anonymity. A computer geek can use external information about a few movies and maybe approximate dates of movie watching, to identify a particular subscriber to reveal the entire watching history. You may argue it is hard to match the records for a large number of subscribers. However, such privacy invasion poses a serious threat even if there is only one record matched. For example, suppose your boss has the access to the anonymous Netflix Prize dataset. In a hallway conversation, you casually exchanged what movies you liked and disliked. This boss may be able to find your entire movie viewing history and infer your private options.
The algorithm can use the trace evidence — what you have watched in approximate periods — to identify you. These data points are unique to you. (It is literally “you are what you watch”.) The same approach can be applied to all other data around you — shopping data, medical visit data, GPS data, and so on. Suppose you jog in a certain routine at a certain hour every week. Assume you use a running app, and you carefully use a fake name. However, the street camera database may have your routine data and even facial images. The two databases can be matched to identify you. Sounds very scary? I agree. I certainly advocate strict laws to protect data privacy.
How Did Researchers “Un-Anonymize” the Netflix database?
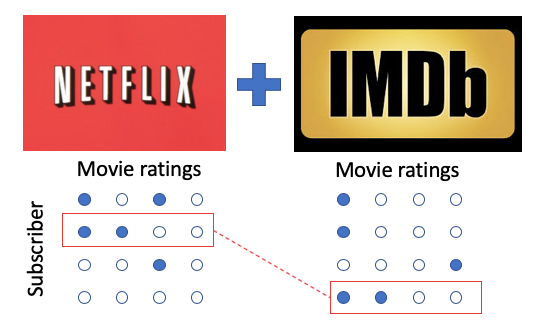
The Internet Movie Database (IMDb) has a large number of personal movie ratings. For Netflix subscribers who use IMDb, it is expected that there is a strong correlation between their private Netflix ratings and their public IMDb ratings. Yes, indeed, not all movies rated by the Netflix subscriber have also rated on IMDb, or vice versa. But this is very trivial. Narayanan & Shmatikov found that “even a handful of movies that are rated by a subscriber in both services would be sufficient to identify his or her record in the Netflix Prize database.”
How about using multiple fake names to protect privacy? Narayanan & Shmatikov explain it is still useless. They give a scenario that a subscriber Alice later opened a new account named Ecila. Since the algorithm can identify Alice through part of the movie rating history, it can identify Ecila as well by the rating history without knowing Ecila.
There are thousands of movie titles on Netflix as well as the IMBd datasets. These movie titles are the columns or the attributes and the subscribers are the rows. A large number of movie titles makes the data matrix very sparse. How likely it is to find one record of a subscriber in the Netflix dataset and one in the IMDb dataset that shows very similar ratings for the same set of movies? Narayanan & Shmatikov, therefore, developed a Similarity Measure that measures the similarity of two records. What if the match is just a spurious match? They explained on their FAQ page that the match quality was so precise that the second-best match was 28 standard deviations away. It is exceedingly improbable that this is a spurious match.
There Are Many Ways to Uncover an Anonymous Account
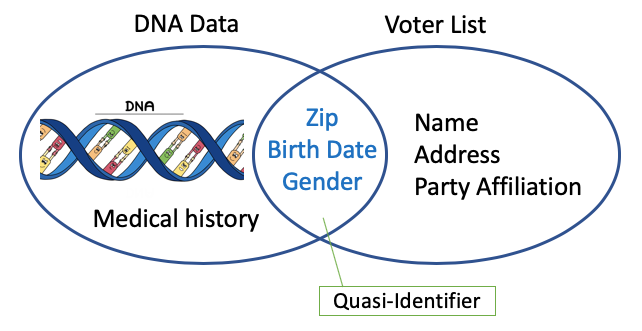
According to Data Privacy Lab by Latanya Sweeney, a Harvard Professor, 87% of the U.S. population had unique combinations of date of birth, gender, and 5-digit Zip code. Even without your name and address, you can be uniquely identified by the above three keys, called the quasi-identifier. This data vulnerability was shown in an evident example that the anonymous medical information of William Weld, former governor of Massachusetts, can be easily identified by linking the medical data to a voter list. So this is called the Linkage Attack.
If you are concerned about the disclosure of your private medical records, you should be even more concerned about the disclosure of your DNA information. Sweeney proved that more than 40% of the anonymous voluntary genome data can be identified by linking to the voter list with the three keys. The Personal Genome Project (PGP) profile, offered by anonymous volunteers, contains detailed DNA information.
K-Anonymity Is One Effective Remedy
The issue of data privacy can challenge all kinds of collected data like surveys or e-mail responses. How can we prevent this? In most survey research there is no need for a very precise value. For example, a marketer just needs to know the target age is 20–25 years old. It does not matter if the mean age is 22.4 years old or 22.8 years old. Latanya Sweeney and Pierangela Samarati 1998 proposed an effective solution called the K-Anomymity. The concept is to make the quasi-identifiers of row k look like those of the k-1 other rows. I illustrate the k-Anonymity in the following graph. The zip code can be recorded as the approximate zip code and “Age” be the range of age. This preserves the data integrity and the use of data. This also makes the linkage attack impossible.

Differential Privacy and Privacy-Preserving Machine Learning
Disguising personally identifiable information does not guarantee any data privacy. There must be new ways to protect data privacy. In recent years an important research line called Differential Privacy and Privacy-Preserving Machine Learning offers salient solutions. Stay tuned for more of Dataman’s writings!




