
YOLOv9: New Object Detection King
Anyone who has worked with object detection knows about YOLO, it has been one of the most popular frameworks for object detection for years. Despite being this popular, it’s still very complex to understand why it performs so well. Most blogs and writing I’ve come across just discuss how to use it rather than explaining the principle behind YOLO's awesome performance. This is our third blog in the YOLO series, I would highly recommend reading the other two in order to make sense of these new advancements. So, without further ado, let’s start.
Topics Covered
- Evolution of CNN architectures
- Reversible Architectures
- Deep Supervision
- Efficient Layer Aggregation Networks
- PGI (Programmable Gradient Information)
- Conclusion
Evolution of CNN architectures
To understand YOLO, we need to first understand what we try to optimize with the discovery of every new architecture. Basically with every passing year we are trying to do two things primarily, make better abstractions as we go deeper in the network and second is to better combine the data from different layers or parts of the network.
Simpy put, we want to make the gradient flow smooth and richer with every new architecture design.
We started our journey with Lenet, and then we increased the depth of the network in VGG, giving us better abstractions. Next, we added skip connections that help us to carry forward more features (less distorted) deeper into the network. As we move forward in a network we keep making more and more abstraction and the network keeps forgetting how the original image feature looks like. ResNet was a big leap in architecture design, and it greatly helped us to solve the problem of exploding and vanishing gradients.
Next, we invented the inception type of networks where we were able to make the gradients flow parallelly and then combine that information later on, this helps in a smoother and more rich flow of gradients. This also helps in reducing the computing required to achieve a similar level of abstraction. MobileNet was a big achievement in this space, quite fast in the inference.
Later we designed, ResNext, Densenet, and many more, but the principle was the same, reducing the information bottleneck and giving more context to the later layer of the networks, giving smoother and richer abstractions, while trying to keep the network from going into over parameterization.
Information bottleneck
At its core, the information bottleneck principle posits that when data (X) undergoes a series of transformations, there’s an inherent tendency for information loss to occur. This loss is expressed in Eq. 1, where the mutual information between the original data (X) and its transformed representations decreases as it passes through the functions fθ(X) and gϕ(fθ(X)).
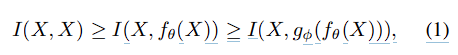
In deep neural networks, each layer acts as a transformation function like fθ or gϕ. Here's how the bottleneck principle manifests itself:
- Information Loss and Degradation: As input data propagates through deeper layers, the likelihood of losing valuable information increases. This degradation is due to the successive, often non-linear, transformations applied at each layer.
- Unreliable Gradients and Convergence Issues: Since the output of a deep network relies on progressively less complete information about the original input, the gradients calculated during backpropagation (to update network weights) become less reliable. This can hinder optimization and lead to poor convergence of the model.
Over parameterization
The idea is that an overly complex model (one with too many parameters) tends to memorize the training data with its specific noise patterns rather than learning the true underlying patterns. This leads to superb performance on the training set but dismal results on unseen data.
With enough parameters, a deep network theoretically has the capacity to simply memorize the training set. However, the choice of optimization algorithms, the order in which data is presented, and potentially early stopping can prevent this pure memorization and instead guide the model towards solutions that generalize.
So the goal for us to is create performant models with as less parameters as possible. This challenge is quite big when we look into LLMs as well, we don’t know what model just memorized and what it understood.
Check out this great article talking about the evolution of CNN architecture:
Reversible Architectures
I’m once again reiterating that you will not understand the YOLO framework without understanding the entire object detection pipeline, please check the above two blogs. They cover everything in super detail.
Let’s try to focus our attention on reversible architectures and why we need such architectures.
The fundamental principle in these architectures is reversibility. In a traditional neural network, as data propagates through layers, information loss can occur due to transformations. Reversible architectures aim to mitigate this by ensuring each layer’s output can theoretically be used to reconstruct the original input perfectly. This helps preserve valuable information for more accurate predictions.
- Res2Net: Employs a hierarchical residual-like structure where input data is split into smaller partitions. Each partition undergoes transformations, and the results are concatenated before being passed to the next module. This allows for the extraction of features at multiple scales.
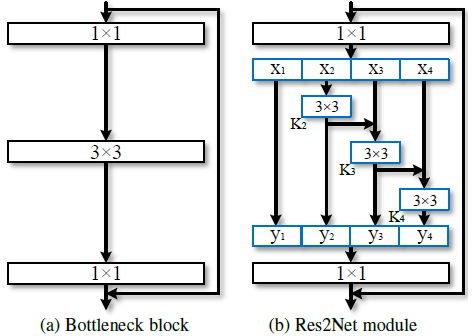
RevCol: This architecture introduces multi-level reversibility. Different units within a layer operate on distinct data partitions, providing a richer hierarchical representation of the original information.
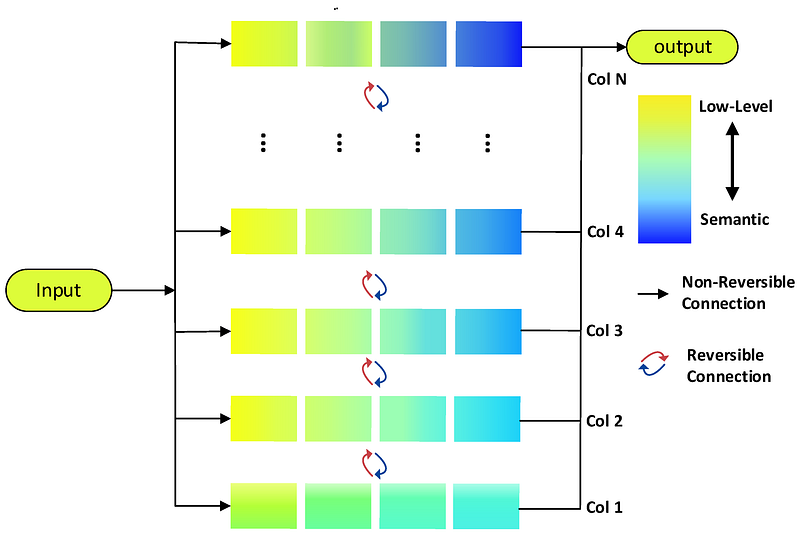
YOLOv9 introduces the DynamicDet architecture as the basis for designing reversible branches. DynamicDet combines CBNet and the high-efficiency real-time object detector YOLOv7 to achieve a very good trade-off between speed, number of parameters, and accuracy.
Deep Supervision
Deep supervision is a technique commonly used to improve the training of deep neural networks. It involves adding extra “prediction layers” within the network’s intermediate stages. These additional layers provide direct supervision signals to earlier layers, forcing them to learn meaningful representations. Examples in transformer-based architectures often use multi-layer decoders for this purpose.
Beyond Simple Predictions: Additional Tasks
Another form of auxiliary supervision uses additional metadata to guide the learning process:
- Metadata Guidance: Relevant task-specific information can be used to shape the feature maps generated by intermediate layers. This forces the model to extract features relevant to the target task even in the earlier network stages.
- Examples: Using segmentation or depth loss to improve object detection models exemplifies this approach.
Auxiliary Supervision and Model Size
- Benefits for Large Models: Recent research suggests clever label assignment strategies combined with auxiliary losses can accelerate model convergence and even improve model robustness (making them less sensitive to noise or adversarial attacks).
- The Under-parameterized Problem: The downside is that these mechanisms often work best in large models. When applied to smaller, lightweight models, they can lead to under-parameterization — the model doesn’t have enough capacity to properly learn the information from the new auxiliary tasks, leading to a performance decrease.
To solve these above-mentioned problems, YOLOv9 introduces the PGI (Programmable Gradient Information) Explained below.
Efficient Layer Aggregation Networks
The design of an efficient architecture primarily focuses on the number of parameters, amount of computations, and computational density of a model. The VovNet model goes a bit further and analyses the influence of the input/output channel ratio, the number of branches of the architecture, and the element-wise operation on the network inference speed. The subsequent prominent development in architecture search is called ELAN and YOLO v7 extends that and calls it E-ELAN. The conclusions drawn from the ELAN paper were that by controlling the shortest longest gradient path, a deeper network can learn and converge effectively.
Regardless of the gradient path length and the stacking number of computational blocks in large-scale ELAN, it has reached a stable state. If more computational blocks are stacked unlimitedly, this stable state may be destroyed, and the parameter utilization rate will decrease. E-ELAN uses expand, shuffle, and merge cardinality to achieve the ability to continuously enhance the learning ability of the network without destroying the original gradient path. E-ELAN only changes the architecture in the computational block, while the architecture of the transition layer is entirely unchanged.
E-ELAN strategy is to use group convolution to expand the channel and cardinality of computational blocks. It applies the same group parameter and channel multiplier to all the computational blocks of a computational layer. Then, the feature map calculated by each computational block is shuffled into g groups according to the set group parameter g, and then concatenated together. At this time, the number of channels in each group of feature maps will be the same as the number of channels in the original architecture. Finally, add g groups of feature maps to perform merge cardinality. In addition to maintaining the original ELAN design architecture, E-ELAN can also guide different groups of computational blocks to learn more diverse features.
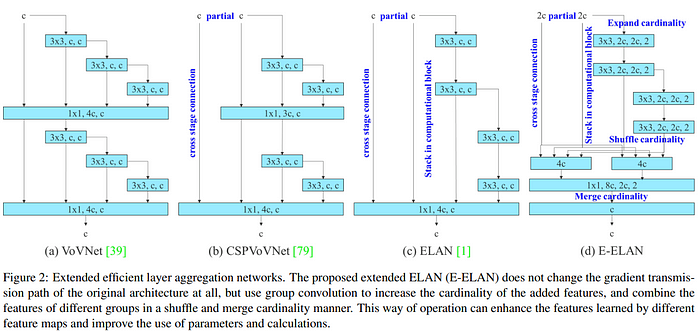
YOLOv9 introduces a method called Generalized ELAN.
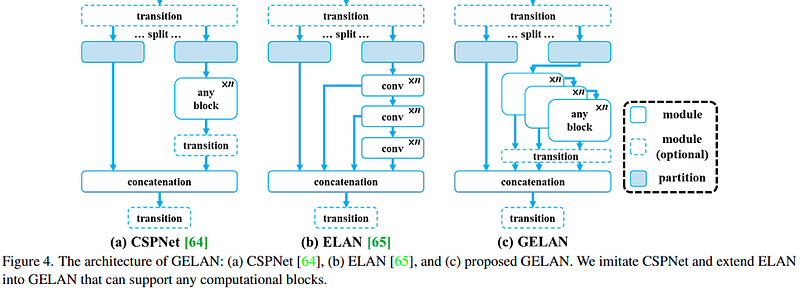
- GELAN Combines the strengths of CSPNet (known for its lightweight design and efficiency) and ELAN (focuses on gradient path management for effective learning).
- Generalizes the concept of ELAN by allowing the use of any type of computational block within the network, not just convolutional layers. This provides more flexibility in designing efficient network architectures.
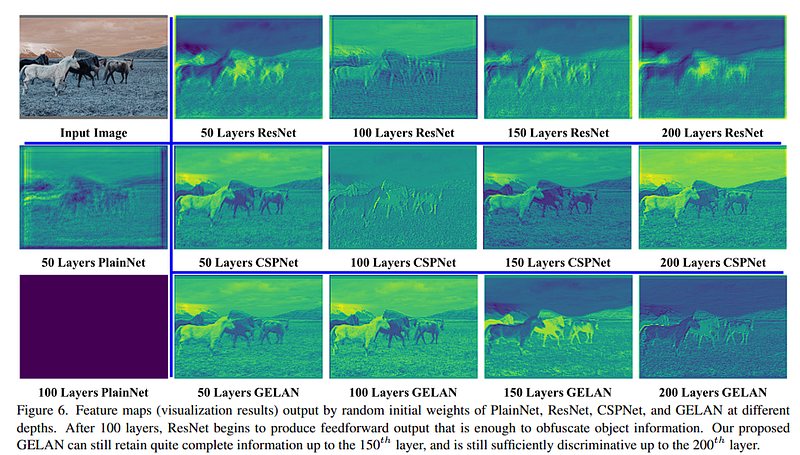
PGI (Programmable Gradient Information)
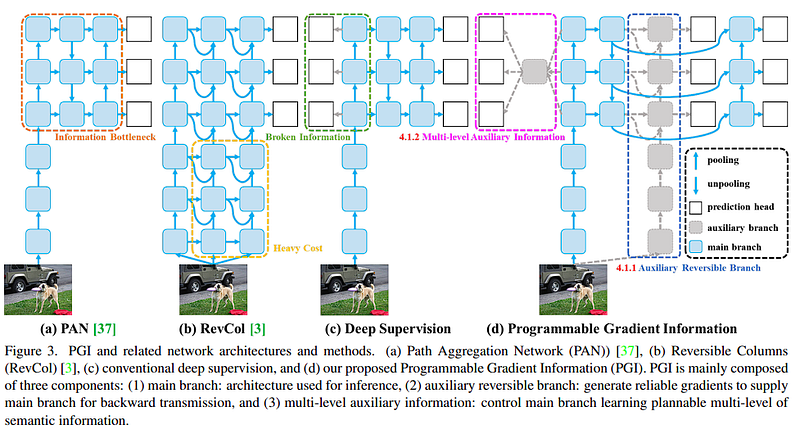
PGI basically addresses two main problems:
- Information bottleneck
- Deep supervision limitations: Deep supervision adds additional prediction layers to the network to help with training. However, it can sometimes lead to the network focusing too much on specific features or objects and ignoring others.
To clarify how PGI is used in YOLOv9 and tie it with the other concepts explained above, let’s break down the elements of PGI shown in the above figure and relate them to the network design and training process:
1. Main Branch: This is the primary pathway through which data flows during inference. In YOLOv9, the main branch consists of the layers and blocks that directly contribute to the final output during the forward pass without additional inference cost. The main branch is composed of the standard neural network layers (represented by blue squares) used for forward propagation and backpropagation during training, but only for forward propagation during inference.
2. Auxiliary Reversible Branch: This component provides an alternative path to ensure that the gradients propagated back during training are reliable and complete. It addresses the issue of the information bottleneck that can occur in deep networks, which might prevent the loss function from generating informative gradients. In YOLOv9, this branch allows the network to benefit from deeper layers’ information during training without adding computational burden during inference, as it can be removed post-training.
3. Multi-Level Auxiliary Information: This addresses issues related to deep supervision, where different levels of the network may focus too narrowly on specific tasks (like detecting objects of a certain size) at the expense of the overall learning process. In YOLOv9, multi-level auxiliary information would help integrate gradients from various prediction heads across different levels of the network, ensuring holistic learning that considers all object sizes. This integration is visualized in the pink dashed area in the above figure, indicating the flow of gradients from multiple levels that inform the main branch.
— During Training: The main branch, auxiliary reversible branch, and multi-level auxiliary information are all active. The auxiliary reversible branch ensures that the backpropagated gradients are informative and reliable, while the multi-level auxiliary information ensures that gradients from various levels of the network are integrated and inform the main branch effectively.
— During Inference: Only the main branch is used, which means the model operates without the additional computational overhead introduced by the auxiliary reversible branch. This allows YOLOv9 to remain efficient during inference, benefiting from the enhanced learning during training without paying the computational cost.
Conclusion
By integrating PGI, YOLOv9 aims to benefit from the advantages of a deep and complex network in terms of learning capacity while avoiding information bottlenecks and error propagation. This leads to a more robust model that is capable of detecting objects with high accuracy and efficiency, both critical factors for a state-of-the-art object detection system.
This marks the end of this blog.
Writing such articles is very time-consuming; show some love and respect by clapping and sharing the article. Please support good AI content, content beyond the Hype. Happy learning ❤
Please don’t forget to subscribe to AIGuys Digest Newsletter
Also, check out my new book on AI: AI Book
References
[1] https://arxiv.org/pdf/2402.13616.pdf
[2] https://readmedium.com/yolo-v4-explained-in-full-detail-5200b77aa825
[3] https://readmedium.com/yolov7-making-yolo-great-again-7b1ec1f6a2a0
[4] https://readmedium.com/how-cnn-architectures-evolved-c53d3819fef8




