
YOLO v8! The real state-of-the-art?
My experience & experiment related to YOLO v8
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi introduced YOLO (You Only Look Once) a family of computer vision models that are seeking the attention and fanfare of many AI enthusiasts. On January 10th, 2023, the latest version of YOLO which is YOLO8 launched claiming advancements in structure and architectural changes with better results.
Introduction :
I experimented with the brand-new, cutting-edge, state-of-the-art YOLO v8 from Ultralytics. YOLO versions 6 and 7 were released to the public over a period of 1–2 months. Both are PyTorch-based models.
Even its predecessor YOLO v5 also has one PyTorch-based model. A few days ago [or we can say a few hours ago] YOLO v8 launched. I thought what if I try to check it on the same parameters? Last time I used the coco dataset but this time, I have used a license plate detection problem.
Dataset :
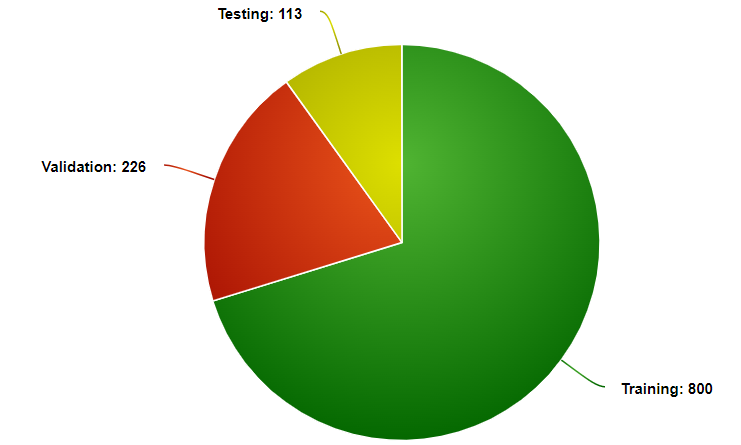
The dataset had almost 800 images for training,226 for validation, and 113 images for testing. All images we use were pure and not augmented.
Epochs:
We purposefully kept epochs to 100 to see its performance in warm-up iterations.
Models:
Pytorch-based YOLO v5, YOLO v6, YOLO v7 & YOLO v8
As docs say, YOLOv8 is a cutting-edge, state-of-the-art (SOTA) model that builds upon the success of previous YOLO versions and introduces new features and improvements to further boost performance and flexibility.
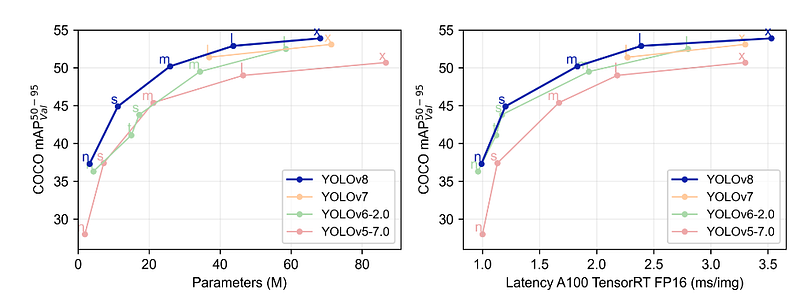
It uses anchor-free detection and new convolutional layers to make predictions more accurate.
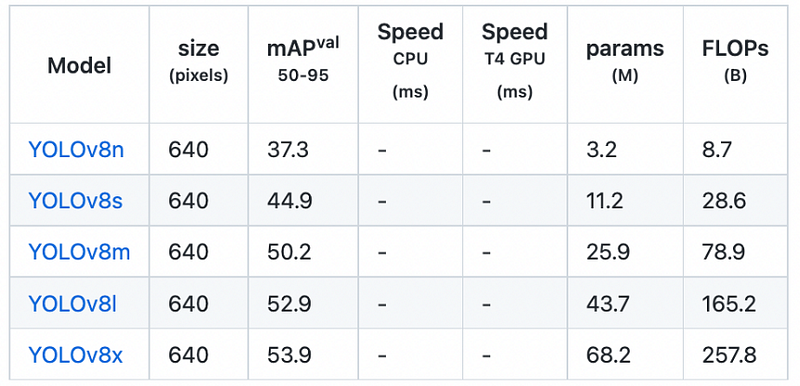
Results:
The results that YOLO 8 got on RF100 were improved from other versions.
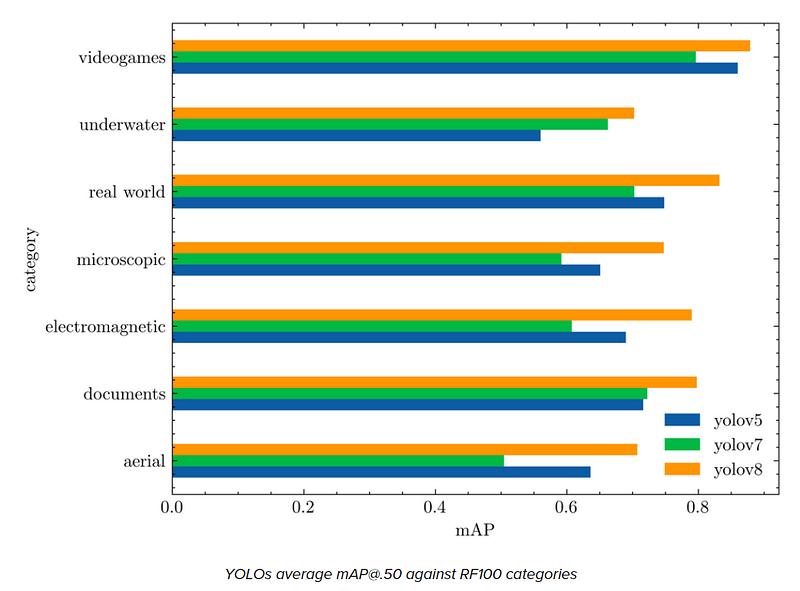
Results on the custom dataset:
Now let's see if this YOLO v8 really works or not on custom datasets. Below are the results of YOLO v8 on the Licence plate detection problem.
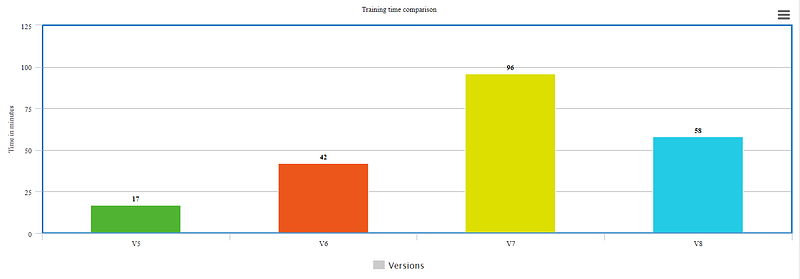
After training for predefined epochs, I calculated the mean average precision for all.
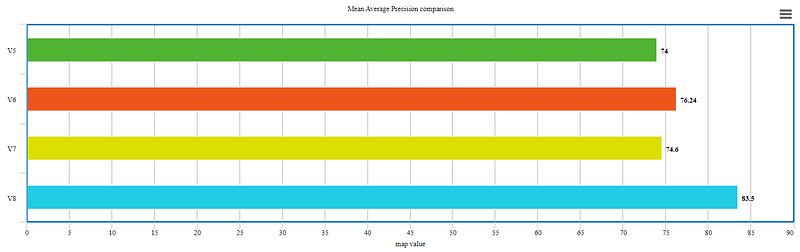
The above figures show us how v8 is outperforming. It is giving us maximum map value at the expense of reduced time for training. Anchor-free detections are faster and more accurate than the previous version.
The working and performance of any model are completely data-dependent & problem statement dependant thing but new additions make things better. This time we didn’t work on latency but those results can be useful for further analysis.

If you want to peer into the code yourself, check out the YOLOv8 repository and view this code differential to see how some of the research was done.
Improvement:
The extensibility of YOLOv8 is an important characteristic. It is created as a framework that works with all prior YOLO iterations, making it simple to switch between them and assess their performance. Because of this, YOLOv8 is the best option for those who wish to benefit from the most recent YOLO technology while keeping their current YOLO models functional.
Observations:
- As we can see training time was a big concern if we consider the exponential growth from v5 to v7 but v8 is taking almost 60% time to train while producing outcomes with higher mean average precision. Here, the issue of prolonged training is somewhat addressed.
2. The trade-off between training time and precision is achieved more in v8.
3. New backbone network, a new anchor-free detection head, and a new loss function making things much faster
Want more on YOLO v8? use the below links.
- YOLOv8 repository — V8
- code differential — V8
- Understanding YOLOs
- Understanding V8
- Docs V8
- Understanding V8- Video
If you find this insightful
If you found this article insightful, follow me on Linkedin and medium. you can also subscribe to get notified when I publish articles. Let’s create a community! Thanks for your support!
If you want to support me :
As Your following and clapping is the most important thing but you can also support me by buying coffee. COFFEE.




