Whisper: Transcribe & Translate Audio Files With Human-Level Performance
An AI model compatible with 97 languages — and how to use it

It is now clear that the general direction of Deep Learning research has fundamentally changed.
A few years ago, the modus operandi of most innovative papers was this: Select a dataset X, build and train a novel model on that dataset, and prove your model was the best by reporting SOTA results. But what happens if we test the model on dataset Y?
For example: Train a powerful ResNet on the ImageNet dataset. The model will excel in classifying cats and dogs, but it will have trouble classifying images such as cartoon dogs, hand-drawn dogs, or Van Gogh-style dogs.
OpenAI has embarked on this paradigm shift with models that generalize well, such as CLIP[1]. To do this, they use meta-learning methods, focusing on zero-shot classification:
Zero-shot classification is the ability of a model to classify unseen labels, without having specifically trained to classify them. This learning method better reflects the human perception.
Following the same steps, OpenAI released Whisper[2], an Automatic Speech Recognition (ASR) model. Among other tasks, Whisper can transcribe large audio files with human-level performance!
In this article, we describe Whisper’s architecture in detail, and analyze how the model works and why it is so cool.
Let’s dive in!
Whisper — An overview
Let’s briefly describe some of Whisper’s characteristics:
- Open Source: The model is created and open-sourced by OpenAI. We will later see a programming tutorial on how to use it.
- Multitask Training: The model features a novel architecture, suitable for multitask training. Whisper is trained for i) language identification, ii) voice activity detection, iii) transcription, and iv) translation.
- Multilingual: Apart from English, Whisper was trained in 96 other languages.
- Diverse Data: The model is trained on 680,000 hours of audio. 65% of those hours are used for English speech recognition, 17% for multilingual speech recognition, and 18% for English translation.
- Superior performance: The authors state that Whisper achieves human-level performance in English speech recognition.
- Whisper vs Commercial Products: Experiments show that Whisper directly challenges commercial competitors such as Amazon Alexa & Siri, and even outperforms them — although their names are masked in the paper.
Limitation: To the best of my knowledge, OpenAI do not disclose their training dataset. They only report the evaluation datasets.
How Whisper Benefits Us
The model can have remarkable applications across many industries — including our everyday lives: For example:
- We can instantly transcribe large audio files, such as podcasts.
- We can transcribe a speech effortlessly.
- Creating accurate subtitles for our Youtube videos or other content will be much easier. Also, using a non-English language is not a limitation. If we want translation, Whisper can handle that too!
- Students won’t have to take notes during a lecture anymore!
- People with hearing impairment will have a much better quality of life. Imagine if you could transcribe your words super-accurately.
Bonus: There’s a chance that OpenAI will utilize Whisper to seamlessly create a much better and diverse dataset for its next GPT model, the GPT-4.
Whisper Architecture
Figure 1 shows the top-level architecture of Whisper. Let’s describe this Figure step-by-step:
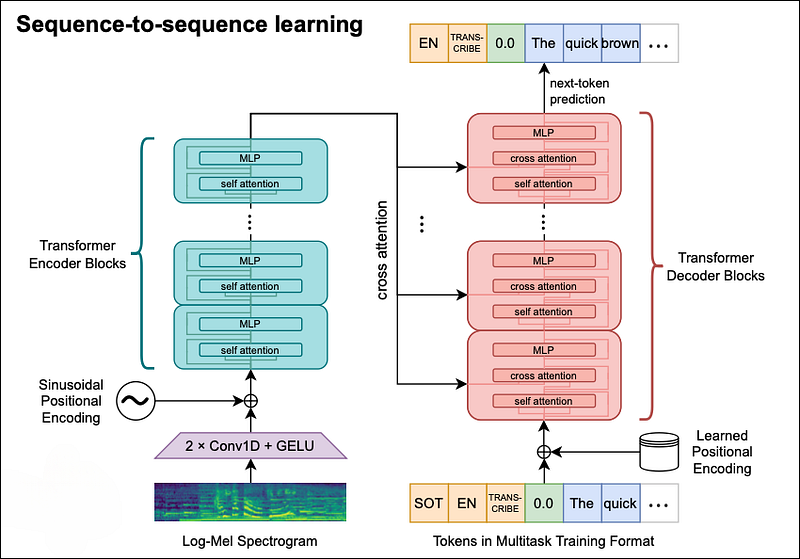
The core of Whisper’s implementation is the well-known Encoder-Decoder Transformer of [4]. The authors chose to use the original version instead of a newer sophisticated version — they didn’t want to make Whisper great through model improvements.
As for the input, the audio is split into 30-second chunks and transformed into a log-Mel Spectogram [Apendix A]. Then the spectrogram is processed by a 2-layered CNN with GELU activation functions and enriched with sinusoidal position embeddings. The input is now ready to be processed by the Encoder part of the Transformer. When the Encoder is done, it sends the K andV attention encoded vectors, to be cross-attended by the Decoder.
The Decoder has more work to do. Remember, Whisper is a multitask architecture — the Decoder must first decide what to do, and then proceed to make predictions. The flow of each different task is better illustrated in Figure 2:
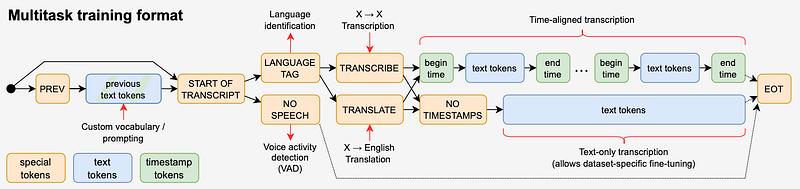
I highly suggest to go to the paper’s url and access the higher-quality image there.
So, the Decoder starts with SOT (<|start-of-transcript|> token). Then, it has to decide whether there is actual speech in the audio. If there is, the Decoder predicts the language-specific token of this speech e.g EN for English. If not, the Decoder predicts the <|nospeech|> token. The user can also explicitly specify the language.
Next, the Decoder decides (per user request) whether the preferred task is transcription or translation — specified by the <|transcribe|> and <|translate|> tokens. Finally, the model specifies whether to predict timestamps or not by including a <|notimestamps|> token for that case.
To recap, the flow of every possible task is:
- Input Audio → No Speech
- Input Audio → Language Identification → Transcription → Timestamps
- Input Audio → Language Identification → Transcription → No Timestamps
- Input Audio → Language Identification → Translation → Timestamps
- Input Audio → Language Identification → Translation → No Timestamps
And that’s it! We have now concluded how Whisper works end-to-end.
The authors have created 9 model variants, each one having a different size. Also, some of these models are English-only, while others are multilingual.
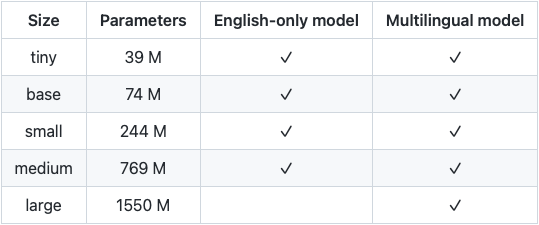
Feel free to go to the paper’s Appendix and check the training configurations and hyperparameters of each model.
The Competitive Advantages Of Whisper
The Automatic Speech Recognition task is not new to Deep Learning. Let’s see why Whisper stands out:
The Large-Scale Weakly Supervision Approach
This approach defines the core philosophy of Whisper — in fact, this phrase is included in the paper’s name.
The conventional approach for training ASR systems is to let them learn from raw audio format, in an unsupervised way. This approach eliminates the need for human intervention, but the model may require extra fine-tuning for more specific tasks (also called downstream tasks).
Of course, there is always the supervised way. However, this hinges on the ability to find a vast amount of high-quality audio data, carefully labeled by humans. Again, this is challenging.
The authors of Whisper became creative and thought: Let’s try using a large amount of data (large-scale) to train our model that aren’t necessarily of gold-standard quality (weakly supervision). The key here is the amount and the diversity of data. Eventually, this approach was successful — Whisper can scale remarkably and generalizes very well.
The MultiTask Pipeline
The authors wanted to build a model capable of doing more than Speech Recognition.
There was a potential concern that jointly training a single model on many tasks may cause interference. What if a task is better learned by a single model instead of being integrated into a parent model that tries to learn other tasks simultaneously?
After some experiments, the authors found that not only there is no interference among different tasks, but also Whisper benefits from learning all of them in parallel!
Experimental Results
Next, the authors put the above claims to the test and show how Whisper compares against other models.
English transcription evaluation
Remember, the authors don’t just want to create a model that outperforms all SOTA models on a Dataset X. Their goal is also to create a model that comfortably generalizes on similar datasets. In other words, they want to create a model resilient to distribution shift [Apendix B].
First, let’s take a look at Table 1:
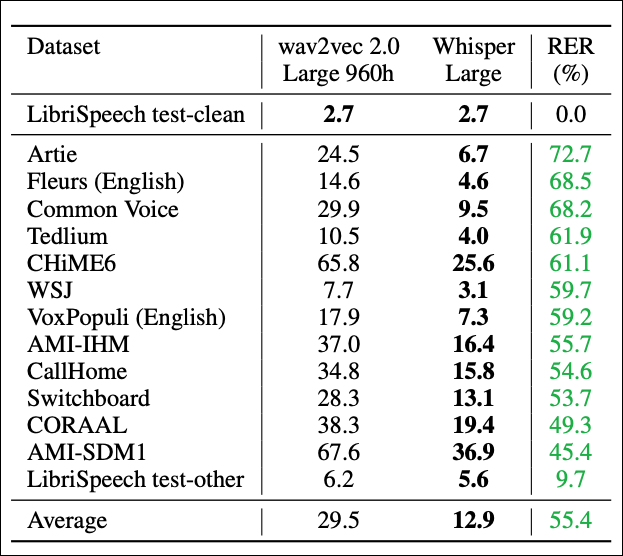
The paper compares Whisper against a variant of the Wav2vec[4] model, in terms of Word Error Rate (or WER) — less is better. The task here is transcription. Wave2vec is specifically trained and fine-tuned on the LibriSpeech dataset, while Whisper is not.
On the LibriSpeech dataset, the two models are equal. However, Whisper outperforms Wav2vec on every other dataset by a large margin!
English tranlation evaluation
Similarly, the authors compared Whisper against other SOTA models on the translation task. The results are shown in Table 2:
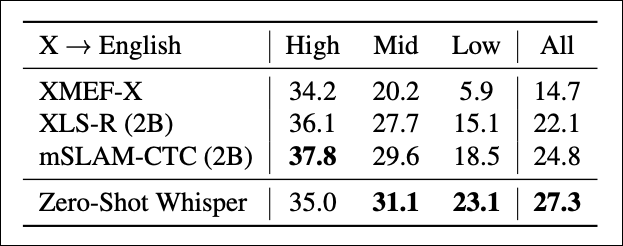
Except for the low resource settings, Whisper outperforms all other models. On average, Whisper achieves a higher BLEU score. Remember that Whisper is used in a zero-shot configuration — the other models have been fully trained using their respective datasets.
Additionally, since the purpose of Whisper is to generalize well, the authors wanted to test how Whisper behaves with noisy data. The results are shown in Figure 3:
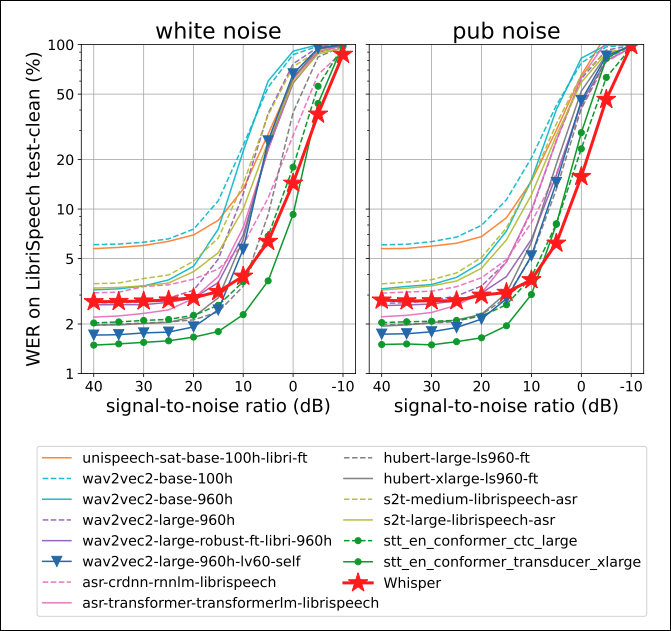
The findings are quite interesting:
The NVIDIA STT models perform best with low noise, but Whisper can scale better. Eventually, Whisper outperforms all models under high noise. This analysis also demonstrates Whisper’s exceptional generalization capabilities.
How To Use Whisper — Coding Example
Next, we will show how to use Whisper using the HugginFaces Library. The full example can be found here.
Step 1: Install ffmpeg
Let’s start with installing our dependencies. First, we need the command line tool ffmpeg
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpegSince our demo will run on Colab, we go with the first option.
Step 2: Download Whisper
Next, use pip to install Whisper. This command will always download the latest version from the OpenAI repository.
pip install git+https://github.com/openai/whisper.gitWe have now completed installing Whisper and its dependencies.
Step 3: Download a sample audio file
We will use the Gettysburg Address audio file[5] from the public domain archive.com
And then use Whisper CLI to transcribe our audio file. It’s that easy!
The output also includes the timestamps of each segment.
The command also creates 3 files: gettysburg_johng_librivox.m4b.vtt gettysburg_johng_librivox.m4b.srt andgettysburg_johng_librivox.m4b.txt. Those contain subtitles and segments in various formats.
By default, the CLI command uses the small model version. For more information about the arguments and how the command is processed, take a look at the original script.
Translation Example
Whisper can handle multiple languages and translate them into English. Let’s see an example, but this time we will use Whisper with Python.
First, we will download a video in Greek from Youtube[6] and convert it to an audio file. We will need to install the pytube library:
!pip install pytubeThis is a video that we will transcribe — it contains the most well-known speech among Greeks!
Let’s start by transcribing the audio. We will use the large version to enhance accuracy:
Apart from a couple of discrepancies, the transcription is highly accurate. Also, notice that the audio is very noisy — this is a speech in a crowded stadium, with people clapping, whistling, and so on.
Finally, we pass the same audio file to Whisper for translation:
The translation is almost impeccable. Interestingly, some discrepancies during transcription in Greek are fixed during English translation.
Obviously, Whisper is more comfortable with English — no surprise here, 83% of the training dataset is reserved for English.
Closing Remarks
Whisper is a remarkable model and a milestone for the AI community.
The ability to transcribe an audio file in 97 languages with human-level performance is unparallel. This astounding success stems from the novel methodology that Whisper adopts (and many other models of OpenAI).
That methodology focuses on learning how to generalize to novel tasks based on task-agnostic information. Besides, this is how human perception works: Humans require only a few examples to correctly classify previously unseen objects based on their past experience.
Thank you for reading!
I write an in-depth analysis of an impactful paper on AI once a month. Stay connected!
- Subscribe to my newsletter!
- Follow me on Linkedin!
- Join Medium! (Affiliate Link)
References
- Alec Radford et al. Learning Transferable Visual Models From Natural Language Supervision (Feb 2021)
- Alec Radford et al. Robust Speech Recognition via Large-Scale Weak Supervision (September 2022)
- A. Vaswani et al. Attention Is All You Need (Jun 2017)
- A. Baevski et al. A framework for self-supervised learning of speech representations (2020)
- Gettysburg Address by Lincoln https://archive.org/details/gettysburg_johng_librivox License: Public Domain
- PASOKwebTV channel
Appendix
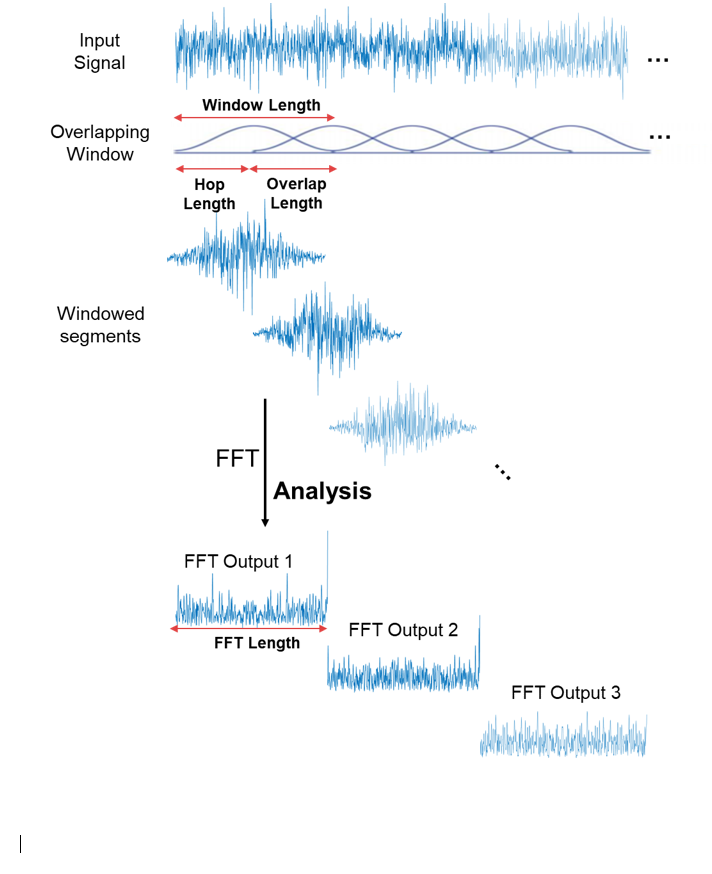
[A] Mel Spectrogram: Each periodic signal is converted from the time domain to the frequency domain using Fourier Transformation. In other words, we create the signal’s spectrum. But what if we want to transform a non-periodic signal?
We can compute several spectrums by performing FT on several windowed segments of the signal. We ‘stitch’ them together, and this is called a spectrogram.
The Mel Spectrogram is a special spectrogram that uses the Mel scale. In the Mel Scale, the pitches are transformed into a new scale such that equal distances in pitch sound are equally distant to the listener. For example, the human ear can tell the difference between 3k and 3.5k Hz, but struggles to tell the difference between 11k and 11,5k Hz, even though the two pairs differ by the same value (0.5 Hz). That’s why we use the Mel Scale.
[B] Distrubution Shift: Distribution Shift is a phenomenon that occurs when the data a model was trained with changes over time. Thus, as time passes, the model’s efficiency degrades and predictions become less accurate.
This phenomenon often occurs in machine learning systems in production. For example, the behavior of users or other external factors may change over time — this will negatively impact the deployed model.
Sometimes, distribution shift is used interchangeably with the term ‘concept drift’. However, they are not the same.





{kind=link}