
When Should You Fine-Tune LLMs?
There has been a flurry of exciting open-source LLMs which can be fine-tuned. But how does that compare to just using a closed API?
I get this question a lot — from folks on LinkedIn asking me questions on how to fine-tune open source models like LLaMA, companies trying to figure out the business case for selling LLM hosting and deployment solutions, and companies trying to capitalize on AI and LLMs applied to their products. But when I ask them why they don’t want to use a close-sourced model like ChatGPT — they don’t really have an answer. So I decided to write this article as someone who applies LLMs to solve business problems every day.
The Case For Closed APIs
Have you tried implementing the ChatGPT API for your use case? Maybe you want to summarize documents or answer questions, or just want a chatbot on your website. More often than not, you will find that ChatGPT does a pretty good job at multiple language tasks.
A common perception is that these models are too expensive. But at $0.002/1K tokens, I bet you could at least try this out on a few 100 samples and evaluate whether LLMs are the way to go or not for your particular application. In fact, at thousands of API calls per day or around that range, ChatGPT API works out much cheaper than hosting infrastructure for custom open-source models as I have written about in this blog.
One argument is let’s say you want to answer questions on thousands or tens of thousands of documents. In this case, wouldn’t it be easier to just train or fine-tune an open source model on this data and ask the fine-tuned model questions about this data? Turns out this is not as simple as it sounds (for a variety of reasons that I will discuss below in the section on labeling data for fine-tuning).
But there is an easy solution for ChatGPT to answer questions from context that contains thousands of documents. It is basically to store all these documents as small chunks of text in a database.
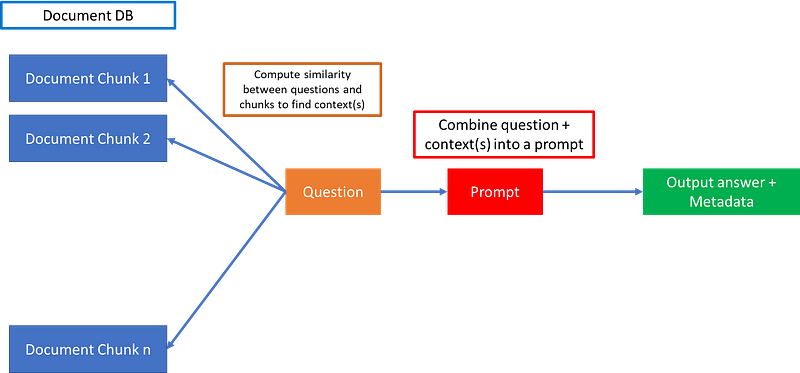
The problem of giving all the necessary information to the model to answer questions is now offloaded from the model architecture to a database, containing document chunks.
The documents of relevance can then be found by computing similarities between the question and the document chunks. This is done typically by converting the chunks and question into word embedding vectors, and computing cosine similarities between chunks and question, and finally choosing only those chunks above a certain cosine similarity as relevant context.
Finally, the question and context can be combined into a prompt as below, and fed into an LLM API like ChatGPT:
prompt=f"Answer the question. Context: {context}\n Question: {question}"You might ask — why not feed the entire documents and question into the prompt instead of separating out into chunks? The reason we are separating documents into chunks and not combining all documents into a single prompt is because LLMs have certain limits on maximum input and output length. For ChatGPT, this is 4096 tokens, or roughly 6–7 pages of text.
Offloading documents to a database and querying using closed LLM APIs might work well in cases where the answer is obviously present in these documents. But there are a number of cases in which these could yield sub-optimal results, such as if you want ChatGPT to give an expert perspective on a niche topic — for example, speculating on the financial outlook of the U.S. economy.
Domain Specific LLMs
Ok, so you tried out ChatGPT or BARD — and you didn’t like it. The answers were a bit off. For example, you asked ChatGPT:
“How long is the U.S. economy likely to have inflation?”
And it returned:
As an AI language model, I cannot predict the future with certainty, especially with regards to complex economic systems. However, I can provide you with some information and perspectives that may help you understand the current situation.
Inflation is a complex phenomenon that can be caused by a variety of factors such as an increase in demand, supply constraints,….
Unfortunately that is not good enough for you. Of course you can feed ChatGPT some recent news about Fed Chairman Jerome Powell’s statements. But that does not give you the same rich domain experience that you would get if you spoke to — well, Jerome Powell, who else! Or another expert.
Think about what it takes to be an expert in a certain field. While some amount of this is reading books on the topic, a lot is also interacting with subject matter experts in the field, and learning from experience. While ChatGPT has been trained on an incredible number of finance books, it probably hasn’t been trained by top financial experts or experts in other specific fields. So how would you make an LLM that is an “expert” in the finance sector? This is where fine-tuning comes in.
Fine-Tuning LLMs
Before I discuss fine-tuning LLMs, let’s talk about fine-tuning smaller language models like BERT, which was commonplace before LLMs. For models like BERT and RoBERTa, fine-tuning amounts to passing some context, and labels. Tasks are well-defined like extracting answers from contexts, or classifying emails as spam vs not spam. I’ve written a couple of blog posts on these that might be useful if you are interested in fine-tuning language models:
However, the reason large language models (LLMs) are all the rage is because they can perform multiple tasks seamlessly by changing the way you frame prompts, and you have the experience similar to talking with a person at the other end. What we want now is to fine-tune that LLM to be an expert in a certain subject and engage in conversation like a “person.” This is quite different from fine-tuning a model like BERT on specific tasks.
One of the earliest open-source breakthroughs was by a group of Stanford researchers that fine-tuned a 7B LLaMa model (released earlier in the year by Meta) which they called Alpaca for less than 600$ on 52K instructions. Soon after, the Vicuna team released a 13 Billion parameter model which achieves 90% of ChatGPT quality.
Very recently, the MPT-7B transformer was released that could ingest 65k tokens, 16X the input size of ChatGPT! The training was done from scratch over 9.5 days for 200k$. As an example for a domain specific LLM, Bloomberg released a GPT-like model BloombergGPT, built for finance and also trained from scratch.
Recent advancements in training and fine-tuning open-source models are just the beginning for small and medium sized companies enriching their offerings through customized LLMs. So how do you decide when it makes sense to fine-tune or train entire domain specific LLMs?
First off, it is important to clearly establish the limitations of closed-source LLM APIs in your domain and make the case for empowering customers to chat with an expert in that domain at a fraction of the cost. Fine-tuning a model is not very expensive for a hundred thousand instructions or so — but getting the right instructions requires careful thought. This is where you also need to be a bit bold — I can’t yet think of many areas where a fine-tuned model is shown to perform significantly better than ChatGPT on domain specific tasks, but I believe this is right around the corner, and any company that does this well will be rewarded.
Which brings me to the case for completely training an LLM from scratch. Yes this could easily cost upwards of hundreds of thousands of dollars, but if you make a solid case, investors would be glad to pitch in. In a recent interview with IBM, Hugging Face CEO Clem Delangue commented that soon, customized LLMs could be as common place as proprietary codebases — and a significant component of what it takes to be competitive in an industry.
Takeaways
LLMs applied to specific domains can be extremely valuable in the industry. There are 3 levels of increasing cost and customizability:
- Closed source APIs + Document Embedding Database: This first solution is probably the easiest to get started off with, and considering the high quality of ChatGPT API — might even give you a good enough (if not the best) performance. And it’s cheap!
- Fine-tune LLMs: Recent progress from fine-tuning LLaMA-like models has shown this costs ~500$ to get a baseline performance similar to ChatGPT in certain domains. Could be worthwhile if you had a database with ~50–100k instructions or conversations to fine-tune a baseline model.
- Train from scratch: As LLaMA and the more recent MPT-7B models have shown, this costs ~100–200k and takes a week or two.
Now that you have the knowledge — go forth and build your custom domain specific LLM applications!
If you like this post, follow me — I write on topics related to applying state-of-the-art NLP in real-world applications and, more generally, on the intersections between data and society.
Feel free to connect with me on LinkedIn!
If you are not yet a Medium member and want to support writers like me, feel free to sign-up through my referral link: https://skanda-vivek.medium.com/membership
Here are some related articles:
LLM Economics: ChatGPT vs Open-Source
How Do You Build A ChatGPT-Powered App?
Extractive vs Generative Q&A — Which is better for your business?
Fine-Tune Transformer Models For Question Answering On Custom Data





