
What Is Differential Privacy?

Differential Privacy is an important research branch in AI. It has brought a fundamental change to AI, and continues to morph the AI development. That’s the motive for me to write the series of articles on Differential Privacy and Privacy-preserving Machine Learning (ML). On Differentiated Privacy, Dataman published “You Can Be Identified by Your Netflix Watching History” and “What Is Differential Privacy?” and more to come in the future.
(A) Let’s Start with Data Privacy
Any private information in digital form is at risk. When you open your Facebook account, you gave them your personal identifiable information (PII) such as name, address, date of birth, marital status, etc. This is sensitive and may be compromised.
Even with anonymity of the PII, Your true identification still can be revealed and at risk. In my previous post “You Can Be Identified by Your Netflix Watching History”, two researchers show individuals can be identified by their anonymous Netflix watching history. With all the digital data about you in the modern era — shopping data, medical data, GPS data, your true identification is still at risk even if you use fake user names.
Sensitive survey questions are private data too. Suppose a researcher needs to know the percentage of males that ever had sex with a prostitute. He surveys random people. Does the researcher need to know which individuals had sex with a prostitute? Probably not. But the collected data can reveal which individuals.
In summary, are there any better ways to protect individual data privacy, and meanwhile provide meaningful statistic? Yes. That’s Differential Privacy in AI.
(B) What is Differential Privacy in AI?
Differential privacy is a formal mathematical definition of privacy. We need algorithms in rigid mathematical form because we deal with trillions of data and more. In the above survey example, the researcher computes the statistics (such as count or percentage) of the collected data. An algorithm is said to be differentially private if by looking at the outcome statistics, one cannot tell which individual was included in the dataset. On the other hand, if the researcher asks one more participant and the outcome percentage changed noticeably, that participant can be identified. This is not differentially private. Thus, a differentially-private algorithm is that the outcome statistics hardly changes when a single individual joins or leaves the dataset. This concept was proposed by Dwork, McSherry, Nissim and Smith in 2006 and called ε-differential privacy.
(C) Apple, Google and Big Tech Companies Adopted This Standard

Apple collects data from the computers to research and improve the user experience. They want to know what new words are trending, which emoji are chosen the most, or which websites can affect the computer battery life. These marketing or system insights can help Apple to make the most relevant recommendations. But the challenge is that the data is specific to each user. Does Apple need to know such specific data? No. Apple announced in 2016 that after iOS10 they are using Differential Privacy technology to discover the usage patterns without compromising individual privacy. Apple explains in this report that before data is sent to Apple server, the differential privacy algorithm adds random noises to the original data. The slightly-biased noise make individual users unidentifiable. But the noises will average out over a large numbers of data points so Apple still can get valuable insights.
Are there any critics of the change? Yes. App makers say it would hurt app makers by making it harder to sell personalized ads, see Wall Street Journal article “Apple Delays Privacy Change Amid App Publishers’ Concerns” on September 3, 2020. This proves the privacy policy can protect consumers better.
(D) How Does Google Approach This Problem?
Google adopts the mechanism in the article “RAPPOR: Randomized Aggregatable Privacy-Preserving Ordinal Response”. The RAPPOR mechanism provides a guarantee for individual data when collecting statistics from end-user or client-side software. The RAPPOR builds on the ideas of randomized response, which is a a surveying technique developed in the 1960s.

People tend to give false answers if being asked sensitive questions. How do we assure people to give reliable answers while giving them the chance to lie? S. L. Warner in 1965 provided a brilliant solution, called the Randomized Response technique, in his paper “Randomized response: a survey technique for eliminating evasive answer bias”. In such a process, chances decide whether the question is to be answered truthfully, or “yes”, regardless of the truth. This chance is controlled by the respondent and unknown to the interviewer. This technique has proven to allow respondents to answer sensitive questions while maintain confidentiality.
(E) Randomized Response Technique Explained
Let me explain how it works. Suppose a social scientist needs to know the percentage of people who have ever evaded taxes. To get the outcome statistics, the social scientist can survey 1,000 people randomly and count how many answer “Yes”. But many respondents will not give their true answers. They may fear this sensitive question and results will be shared with the IRS. What can the researcher do? The researcher can apply the randomized response technique.
“Each respondent rolls the dice without letting the interviewer know the outcome. If it is a 6, answer “Yes” or “No” to the first question (Q1), otherwise answer the opposite question (Q2):
Q1. I have evaded taxes, and Q2. I have never evaded taxes.”
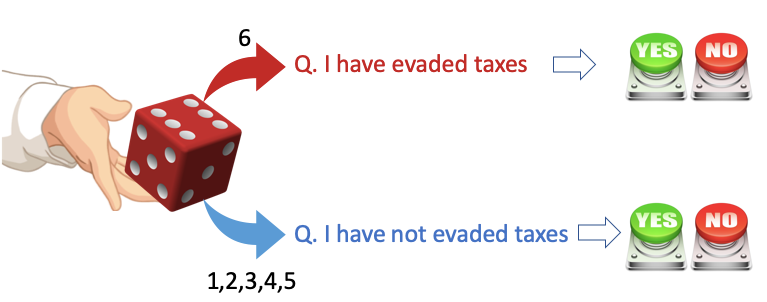
How can we get the true answer? The following equation can easily derive the answer. Let T be the truth percentage that the researcher wants to know, p the probability (=1/6 here), and S be the surveyed percentage known to the researcher. The surveyed percentage S can be expressed by Eq. (1). After arranging the terms, the true percentage T can be obtained by Eq. (2).
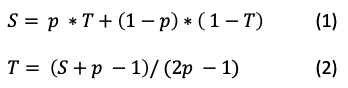
Suppose the researcher gets S = 40%. He can derive the true percentage T = (40% + 1/6 -1 ) / (2 * 1/6 -1 ) = 65%.
The basic assumptions are: (1) the randomization distribution is known to the researchers (in this case it is 1/6), and (2) respondents comply with the instructions and answer the sensitive question truthfully (this can be difficult).
There can be variations of randomized response designs, for other examples, see the article “Design and Analysis of the Randomized Response Technique” (2015) by Graeme Blair, Kosuke Imai, and Yang-Yang Zhou.
(F) RAPPOR to Protect Longitudinal Privacy
However, if the above one-time randomized response is done on the same person repeatedly, the sequence of data of an individual still can be used to reveal his identity. Apple or Google collects data from individual computer periodically. Even if each one-time data is randomized, the sequence of the data, called by the authors of RAPPOR as the Longitudinal Privacy, still can be attacked to identify individuals. This vulnerability is similar to any sequence of data described in “You Can Be Identified by Your Netflix Watching History”, like the history of your Netflix visits, or shopping, or medical visits.
(G) How does RAPPOR prevent this?
In order to protect longitudinal privacy, the authors of RAPPOR proposed a mechanism called the Permanent randomized response. This mechanism replaces the one-time randomized response with a randomized noisy value permanently, i.e, all future data will use the same derived randomized value. The derived noise can be ‘1’, ‘0’, or the original one-time randomized response value with certainly probabilities respectively (summing up to 1). This mechanism can ensure privacy because the attackers can not differentiate between true and “noisy” data in the longitudinal data. The authors of RAPPOR gave an extreme case. Suppose each individual have to report their age (in days) everyday. After a period of time, some individual’s data will stop being collected, or mixed with an increased noises permanently. This makes the longitudinal data of the individual unidentifiable by attackers.
(H) Google Github for RAPPOR
Readers who are interested in the simulation code in Python and R can check this github to see how the RAPPOR produces inferring statistics about populations while preserving the privacy of individual users.




