
Using Word Embedding Model to Generate Relevant and Engaging Product Recommendations
Recently, some people asked me interesting questions about leveraging the Large Language Model (LLM) to create a recommendation system. It is a good and valuable idea as we all know LLM can understand the semantic meaning of the product from the description. And based on the semantic meaning to create the list of relevant products. Such a model is applicable in various sectors, retail for sure, banking, insurance, health care, or any situation that needs a recommendation.
Word Embedding Model and LLM are not the same but are tightly coupled. Word Embedding Model is a way of representing words as numerical vectors that capture their semantic and syntactic properties. LLM is a way of estimating the probability of words or sentences given their context, using Word Embeddings as inputs. You can think of Word Embedding Model as a building block for LLM, which can perform more complex tasks such as Natural Language Understanding and Generation.
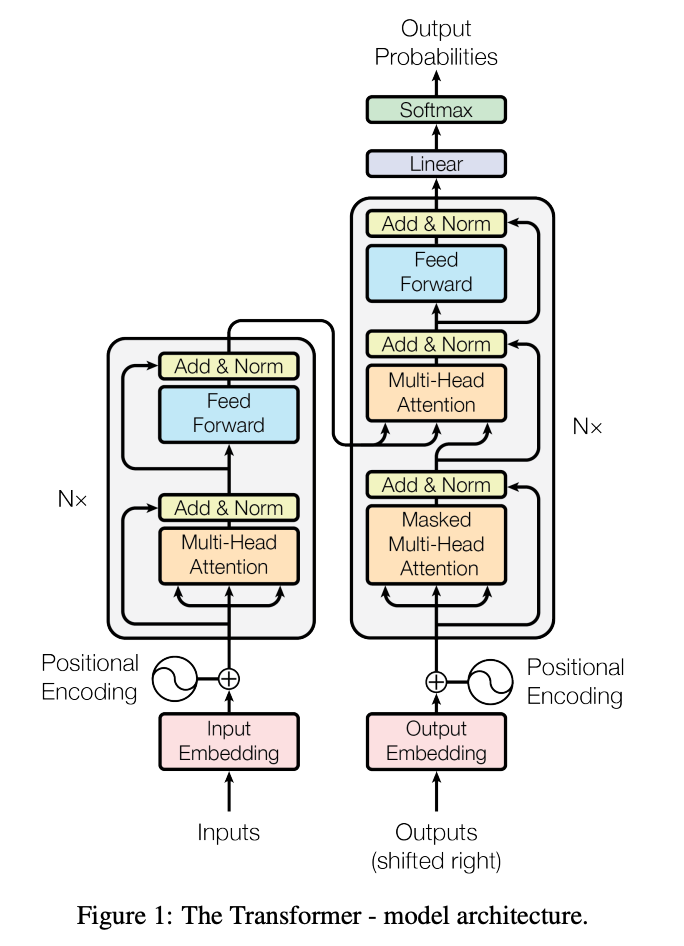
Per my previous story about Market Basket Analysis (MBA), there are various approaches to achieving different objectives in the world of Recommendation Systems, such as Content-Based Filtering.
Content-Based Filtering uses the characteristics of a particular item to recommend other similar items, based on the user’s previous actions or explicit feedback. For instance, when we watch comedy movies on Netflix, the system will suggest other comedy movies. Content-Based Filtering relies on information about the item and the user’s preferences. This method is most useful when data is available about an item (like its name and description), but not necessarily about the user.
You should start to understand why the Word Embedding Model is a perfect match to build a Content-Based Filtering recommendation system, as it can capture the item’s semantic and syntactic means.
Content-Based Filtering is not a new concept. We have been using classic techniques such as TF-IDF, Word2Vec, and FastText for a while to achieve it. TF-IDF represents documents as vectors based on word frequency and importance. Word2Vec learns word embeddings from word co-occurrences using a shallow neural network. FastText learns word embeddings from subword information and word co-occurrences. In contrast, OpenAI learns word embeddings and sentence representations from bidirectional contexts using a Transformer. TF-IDF and Word2vec produce fixed embeddings. FastText and OpenAI produce variable embeddings.
OpenAI can produce Contextual Embeddings, which vary by context. Contextual Embedding methods are utilized to understand the meaning of sequences by analyzing the arrangement of all the words in a document. In this way, these techniques can differentiate between different meanings of the same word, like “left,” depending on the context in which it is used.
So, we should get significant improvement if we use OpenAI’s Word Embedding Model to make a Content-Based Filtering recommendation system.
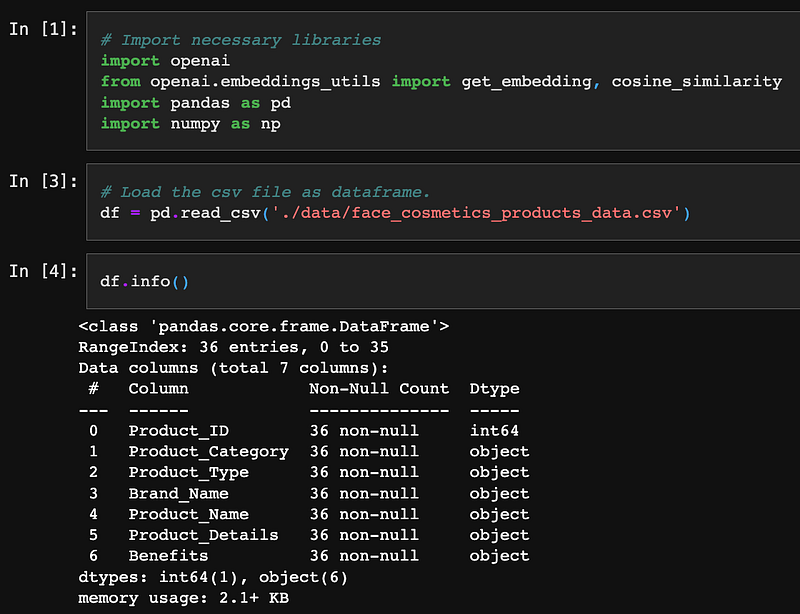
Let’s work it out. I scraped the list of face cosmetic products from the Max Factor website with their product detail descriptions and benefits. It has 36 records, including various types of foundations, concealers, lipstick, etc.
As usual, we need to install and import the necessary libraries, such as OpenAI, Pandas for interacting with the dataframe, and Numpy for numeric vector operations. And I will use the latest Embedding Model from Azure OpenAI Service (AOAI) for this demonstration which is text-embedding-ada-002 and equivalence with OpenAI. Also, please note that this model is only available in East US and South Central US regions for now.
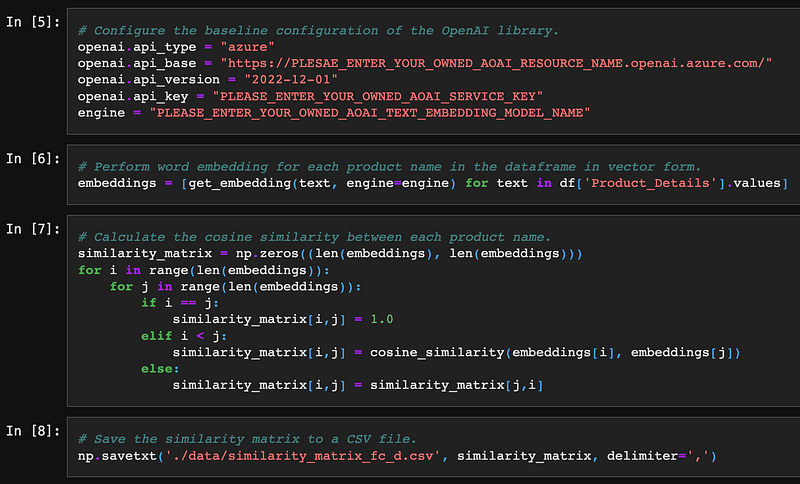
The game plan is we need to perform vectorization by the AOAI Embedding Model for the list of product descriptions. And can use the Cosine Similarity formula to calculate each product’s similarities by the descriptions.
Cosine Similarity is a measure of similarity between two or more vectors that do not depend on their magnitude but only on their orientation. It calculates as the dot product of the vectors divided by the product of their lengths. Cosine Similarity is vital for comparing high-dimensional vectors, such as word embeddings, by capturing semantic and syntactic similarity.
We need to define the baseline configuration to make the OpenAI library interact with AOAI’s Embedding Model, such as API type, endpoint, etc. By calling the get_embedding function from the OpenAI library, we can easily pass the text string to the model and get the corresponding vectors. The library also comes with a cosine_similarity function to calculate the similarity. We can save the embedding result for later use. It is unnecessary to perform embedding every time unless we have a new product newly added.
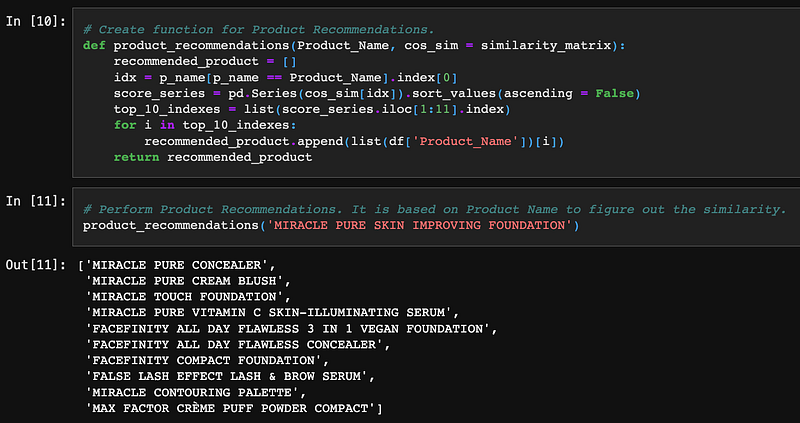
It’s almost done already. Now we just need to create a simple function to make the similarity matrix between each product description. And list out the top 10 results by the product name.
Then by calling the function, we can easily get the top 10 similar products by their contextual similarity of the product description.
The scoring of product recommendations is not necessarily a real-time function. We can pre-generate the scoring result into a JSON file and save it to a No-SQL database (e.g., Azure Cosmos DB) to serve. And make a simple function to read the result from the No-SQL database to serve it as an API.
Thank you for reading this article. I hope you got more ideas on Word Embedding Model and leverage it to build product recommenders. This demo only shows using the product description to calculate the product similarity. And definitely, we can leverage different aspects, such as the product’s benefits, customer feedback, etc.
The Content-Based Filtering approach is good for us to make a recommendation system without any data from the users. It should be highly relevant and transparent if users indicate their interest. But we also need to remember some of the challenges of the Content-Based Filtering approach, such as lack of novelty and diversity, and attributes (content to describe the item) may be incorrect or inconsistent.
It’s just one classic scenario of wisely using the Word Embedding Model. We have a lot of applied and valuable use case scenarios, such as Semantic Search. Please stay tuned for the next story.
Reference





