This is the Way. Market Basket Analysis.
Recently, some people asked me interesting questions about applying the Market Basket Analysis algorithm for product recommendation. First, this question needs to be corrected, as Market Basket Analysis does not equal specific algorithms. Market Basket Analysis (MBA) is a generic term of data analytics that retailers usually use to increase sales performance through a deeper understanding of customer purchasing patterns. It usually involves analyzing the massive amount of purchase history from the customers and turning the data into valuable/actionable insight by Prescriptive and Predictive Analytics.
Retailers applied Market Basket Analysis techniques to various scenarios, such as marketing campaigns & promotions, business & demand forecasting, product recommendations, etc.
There are two types of Market Basket Analysis in principle.
- Predictive: Based on purchasing history, determine the relationship and product recommendation for cross-selling.
- Prescriptive: Based on purchasing history, analyze the data in multiple dimensions, such as the hottest product in a specific period and group of customers. Then based on such actionable insight, compose new product offers to drive higher sales performance.
There are various approaches to achieving different recommendation objectives. In most cases, most people would relate the Market Basket Analysis to association rules based recommendations. It is the approach to determine the associations between the products that customers purchase. Then based on the product associations and provide product recommendations. In this story, I will share how to apply association rules based recommendations with the Apriori algorithm.

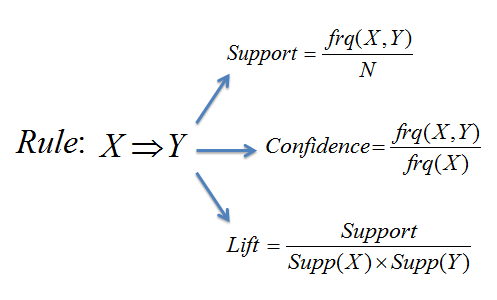
Association Rules is an if-then statement that would tell us the probability of relationships between products (items) in the transaction dataset. If we have a rule “X → Y”, X stands for antecedent (if), and Y stands for consequent (then). There are some key metrics/measures in association rules.
- Support is the ratio of X related transactions to all transactions. For example, if out of 1000 transactions, 100 purchase bread, then support for bread will be 100/1000 = 0.1 (10%).
- Confidence divides the number of X and Y transactions by the number of X transactions. For example, we are looking to build a relationship between bread and milk. So, if 50 customers purchase bread, and 8 customers purchase milk together with bread, then the confidence would be 8/50 = 0.16 (16%).
- Lift is a value to indicate a sales increment of X when selling along with Y. It is simply confidence divided by support. For example, as above, the lift would be 0.16/0.1 = 1.6 (160%).
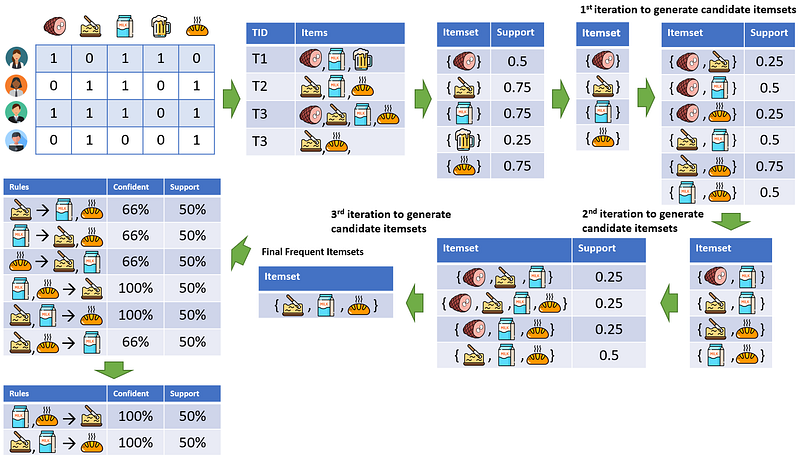
The association rules mining finds all sets of itemset with the constraint of metrics. A set of items together is called an itemset. If any itemset has k-items, it is called a k-itemset. An itemset consists of two or more items. An itemset that occurs frequently is called a frequent itemset. After getting all the frequent itemset, then generate the association rules.
There are several popular algorithms to apply association rules mining, including Apriori, AIS, SETM, and variations of the latter.
The Apriori algorithm generates candidate itemsets using only the large itemsets of the previous pass. The large itemset of the previous pass is joined with itself to generate all itemsets with a size that’s larger by one. Each generated itemset with a subset that is not large is then deleted. The remaining itemsets are the candidates. The Apriori algorithm also considers any subset of a frequent itemset must be frequent. A simple example is a transaction containing {butter, bread, milk} also contains {butter, bread}. So, according to the principle of Apriori, if {butter, bread, milk} is frequent, then {butter, bread} must also be frequent. With this approach, the algorithm reduces the number of candidates being considered by only exploring the itemsets whose support count is greater than the minimum support count.
I prepared a customized dataset based on the classic grocery dataset from Kaggle that has 1,920 records (716 unique Transaction/Invoice IDs, 194 unique Customer IDs. Let me demonstrate how to apply the Apriori algorithm with this sample dataset.
First thing first, let’s import the necessary libraries as usual. The mlxtend (machine learning extensions) library has the function to help you apply Apriori and generate Association Rules.

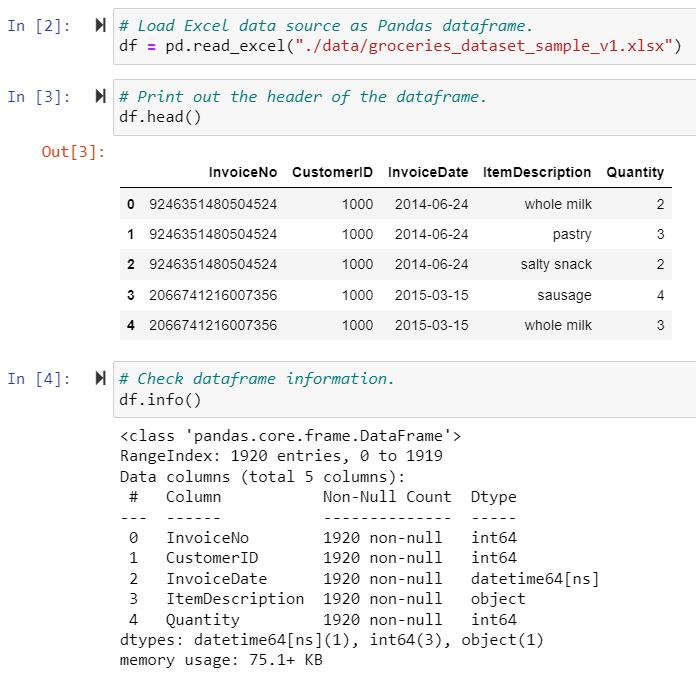
Use Pandas to load the XLSX file as the dataframe. And display the header of datafame and show the data column information. Each record in the dataframe contains only one purchased product with the corresponding Invoice & Customer ID. So each Invoice ID may have multiple records.
Before the workout, let’s quickly check the descriptive statistics to understand the dataset. For example, I checked any null records in the dataframe, min/max values, etc. This sample dataset data range is from 2014–01–02 to 2015–12–29.
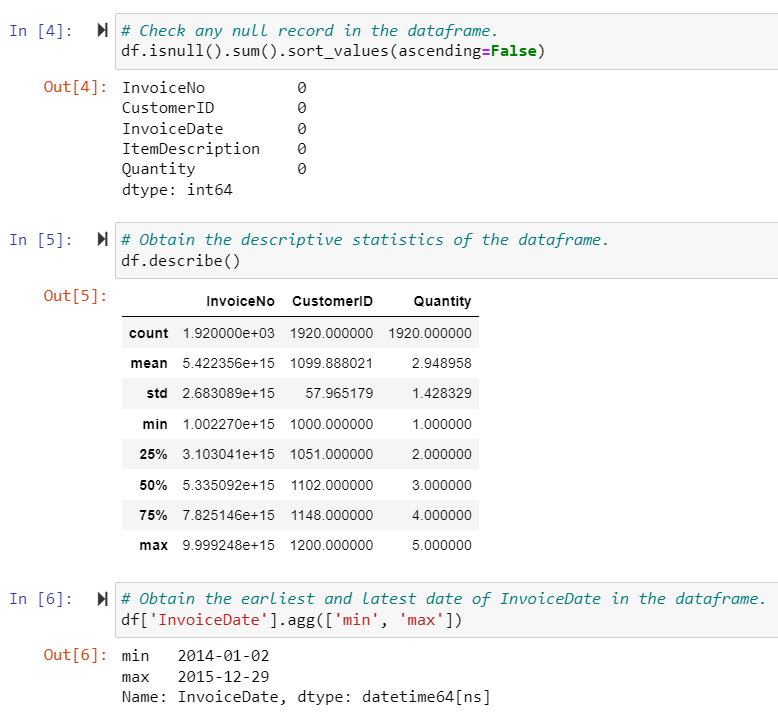
We must prepare the dataset before building the association rules with the Apriori algorithm. Use the simple Pandas’ groupby function to create a matrix to show the purchased items in each Invoice ID. You will also figure out there are 145 products in this dataset.
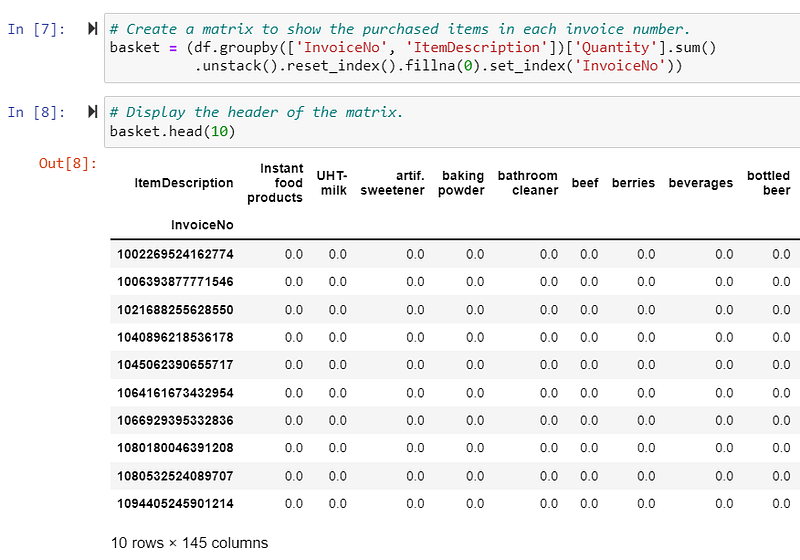
The sum of Quantity is meaningless for building association rules. We should encode the sum of the Quantity to a binary number.
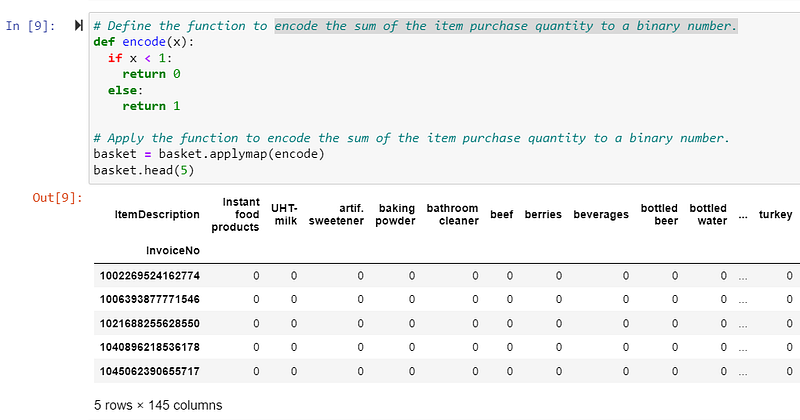
It’s time to generate the frequent itemsets and create the corresponding association rules by applying the library functions with a minimal 0.15 support. I randomly picked “berries” as an example to list out the table of association rules with the metrics.
Based on this, let’s create a simple function to generate the list of frequently bought together products and then call it to get the result. In this example, I only have 1,920 records. The result can be generated extremely fast, in less than a second. And depends on your transaction dataset size, more computation power and computing time are required.
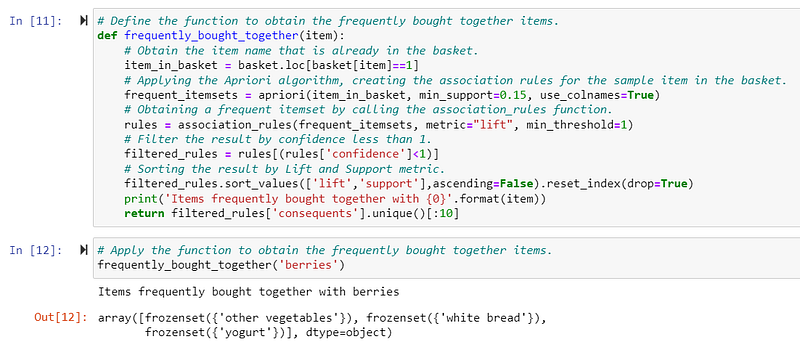
Hope you enjoy this sharing. It would help you get more ideas to generate the association rules by the Apriori algorithm. But are association rules mining techniques only applicable in Retails for product recommendation? It’s not. It can be applied in various scenarios, such as healthcare for patients’ health analysis and drugs in prescription, education for students’ academic performance improvement, auto-complete features in the search engine, etc.
There are various approaches to achieving different objectives in the Recommendation System world. Below is a list of different common approaches in general.
- Collaborative Filtering - Memory Based (aka History Based) > Product-Base Filtering > User-Based Filtering - Model Based > Singular Value Decomposition (SVD) > Alternating Least Square (ALS)
- Content Based Filtering
- Association Rules Based - Apriori - AIS - SETM
- Hybrid
My customized dataset is still under development. I will share with you prescriptive’ Market Basket Analysis (MBA) and other recommendation system techniques later stories. Stay tuned.
Reference
- Full set of sample code repos on my GitHub (easonlai/market_basket_analysis_retail_sample)
- Association Rules Learning from Wikipedia
- 4 Types of Data Analytics Every Analyst Should Know-Descriptive, Diagnostic, Predictive, Prescriptive
- Microsoft Intelligent Data Platform
- Overview of Azure Databricks
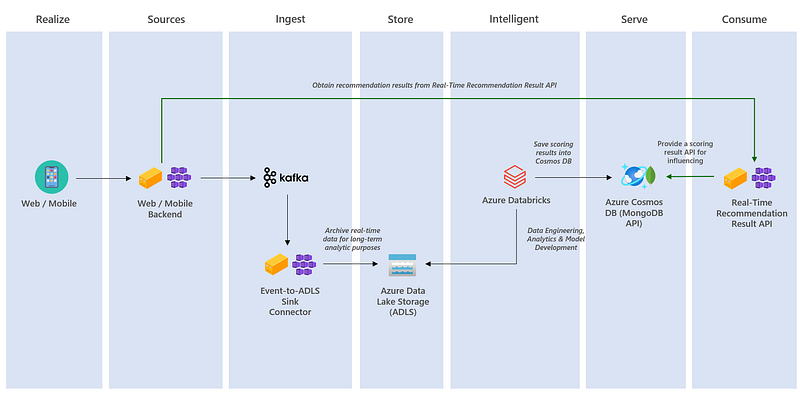
Last but not least, below is a reference architecture for how to make it work to serve for real-time product recommendation by association rules with the Microsoft Azure solution stack.