
Understanding Self-Attention and Transformer Network Architecture
The introduction of Transformer models in 2017 marked a significant turning point in the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), and has since become the foundation for prominent Large Language Models (LLMs), including OpenAI’s ChatGPT, Anthropic’s Claude, and Meta’s LLaMA. At the core of these models is the self-attention mechanism, a key component that allows the model to effectively capture long-range dependencies and contextual information. This article explores the self-attention mechanism in-depth, its various forms, and the overall architecture of Transformer networks.
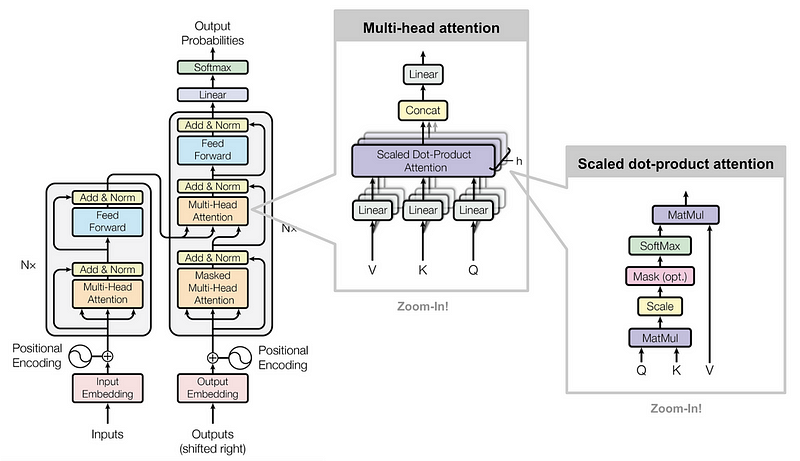
1. The Importance of Vectorization in NLP
Before diving deeper into self-attention, it’s crucial to understand the importance of vectorization in NLP. The early methods like One-Hot Encoding, Bag of Words, and TF-IDF struggled to capture the semantic meaning of words.
1.1 Static Word Embeddings
Traditional word embeddings, such as those produced by algorithms like Word2Vec and GloVe, assign a fixed vector representation to each word in the vocabulary. This static approach means that a word’s embedding remains constant across all contexts.
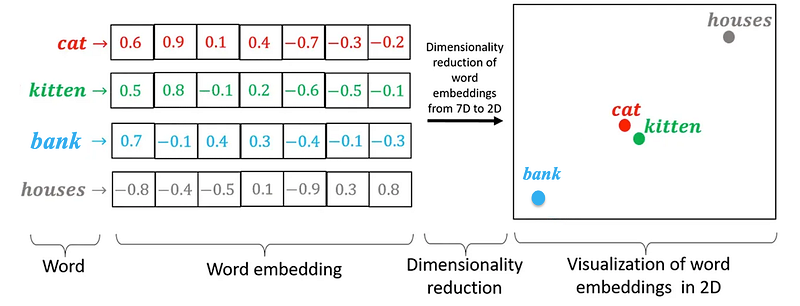
For example, consider the word “bank” in the following sentences:
- “Sitting on a bank next to a river”
- “Thinking about my empty bank account”
In static word embeddings, the vector representation for “bank” would be identical in both sentences, despite the word having different meanings in each context. This limitation can hinder the model’s ability to understand and generate meaningful text.
1.2 Contextual Embeddings
Contextual embeddings, on the other hand, generate vector representations that adapt based on the context in which a word appears. These embeddings are dynamic and can capture the nuanced meanings of words in different situations. In the example above, the vector for “bank” in the first sentence would differ from that in the second sentence, reflecting the different semantic contexts (a riverbank versus a financial institution).
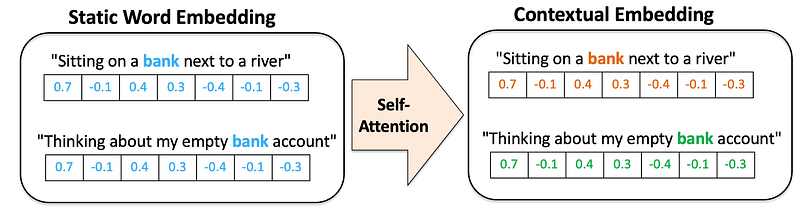
The self-attention mechanism is instrumental in creating these contextual embeddings, enabling models to better understand and represent natural language.
2. Self-Attention (Scaled Dot-Product Attention)
The self-attention mechanism, pioneered in the seminal paper “Attention is All You Need” by Vaswani et al. in 2017, is a foundational component of the Transformer architecture. This mechanism empowers the model to dynamically focus on various parts of the input sequence, enabling each token to consider every other token. By doing so, it effectively captures intricate global dependencies and relationships within the sequence, leading to a more nuanced understanding of the input data.
2.3 Key Concepts of Self-Attention
- Scaled Dot-Product Attention: This involves calculating the similarity between tokens using dot products, followed by scaling and normalization. The scaling factor helps to stabilize the gradients during training.
- Attention Weights: These are the weights assigned to different tokens based on their similarity, computed using a softmax function. The attention weights determine the importance of each token in the context of the current token.
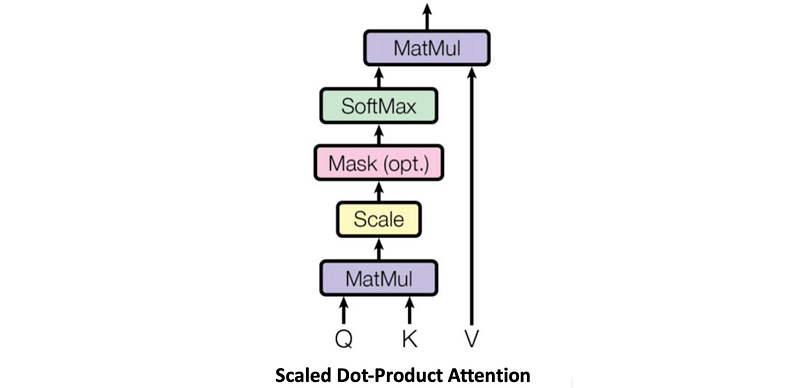
2.2 What’s Inside the Self-Attention Block?
The self-attention mechanism operates on three inputs:
- Query (Q) is the query matrix, obtained by linearly transforming the input embeddings. Queries are used to determine the relevance of each word in the sequence to the current word.
- Key (K) is the key matrix, also obtained by linearly transforming the input embeddings. Keys are used to calculate the attention scores.
- Value (V) is the value matrix, which contains the information to be retrieved based on the attention weights. Values are used to compute the final output embeddings.
2.3 Mathematical Formulation
Each word in the input sequence is first projected into these three matrices using learned weight matrices W^Q, W^K, and W^V
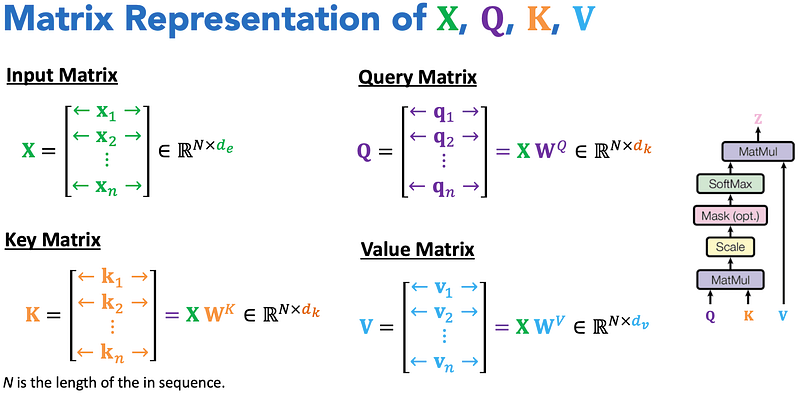
The input sequence matrix X, comprising word embeddings, is multiplied by weight matrices to project each word into three new spaces: query (Q), key (K), and value (V). For example, a 10-word sentence with 512-dimensional vectors would result in a 10x512 matrix.
Attention scores are then calculated by taking the dot product of Q and K, measuring the similarity between the query and key vectors. This step is crucial in determining the relationships between different parts of the input sequence.
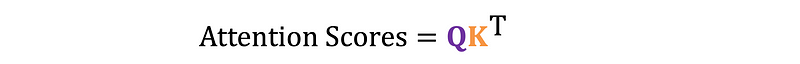
The dot product of Q and K produces a matrix of attention scores, where each element represents the attention between a pair of words in the input sequence. However, as vector dimensions increase, dot product values can become large, leading to small gradients during softmax.
To mitigate this, attention scores are scaled by the square root of the key vector dimension (d_k).
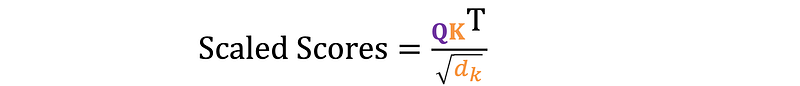
This adjustment helps maintain stable gradients during training. The self-attention mechanism can be represented mathematically as a combination of these steps.
If each key vector has 64 dimensions, the scaling factor would be the square root of 64, which is 8. This scaling factor helps stabilize gradients and improves the effectiveness of the softmax function.
The scaled scores are then passed through the softmax function, which converts them into probabilities that sum to 1.
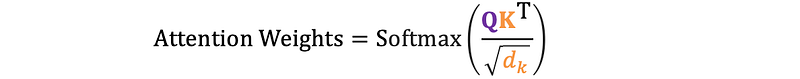
This highlights the most important relationships between words, allowing the model to focus on the most relevant connections.
The final step is to calculate a weighted sum of the value vectors V, using the attention weights obtained from the softmax function. This produces a context-aware representation of the input sequence.
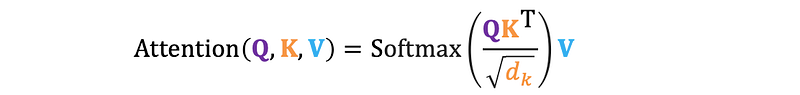
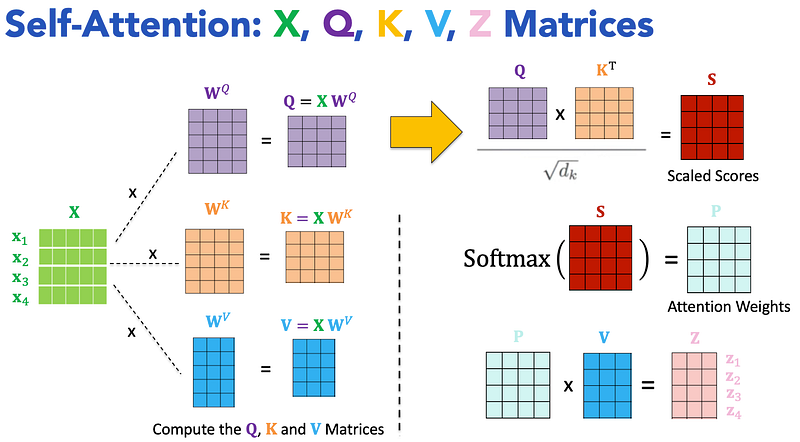
2.4 Step-by-Step Computation
- Compute the Query, Key, and Value Matrices: First, we transform each token of our sentence into three different vectors Q, K, and V. This is done by multiplying the input embeddings with learned weight matrices.
- Calculate Attention Scores: Next, we calculate how much each word should pay attention to every other word by taking the dot product of the Query and Key matrices.
- Scaling the Scores: To mitigate the problem of large variance in high-dimensional matrices, the dot products are scaled by the square root of the dimensionality of Key vectors (√dₖ).
- Apply the Softmax Function: The scaled scores are passed through a softmax function to normalize the values between 0 and 1.
- Weight the Values: The attention weights are used to compute a weighted sum of the value matrix, resulting in the final output of the self-attention mechanism.
3. Analogy to Database Query
To understand how the system learns self-attention, consider an analogy to a database query:
- Query (Q): Represents the input token for which we want to compute attention. In a database context, this would be the search query.
- Key (K): Represents the tokens against which the query is compared. In a database, these would be the keys used to index the data.
- Value (V): Represents the information to be retrieved based on the similarity between the query and the keys. In a database, these would be the values associated with the keys.
The dot product of Q and K measures the similarity between the query and the keys, and if the similarity is high, the corresponding value is retrieved. In the context of self-attention, this process is applied to all tokens in the input sequence, allowing each token to attend to all other tokens.
4. Multi-Head Attention
Multi-Head Attention is an extension of self-attention, allowing the model to focus on different parts of the input sequence simultaneously. This is achieved by applying several attention mechanisms in parallel.
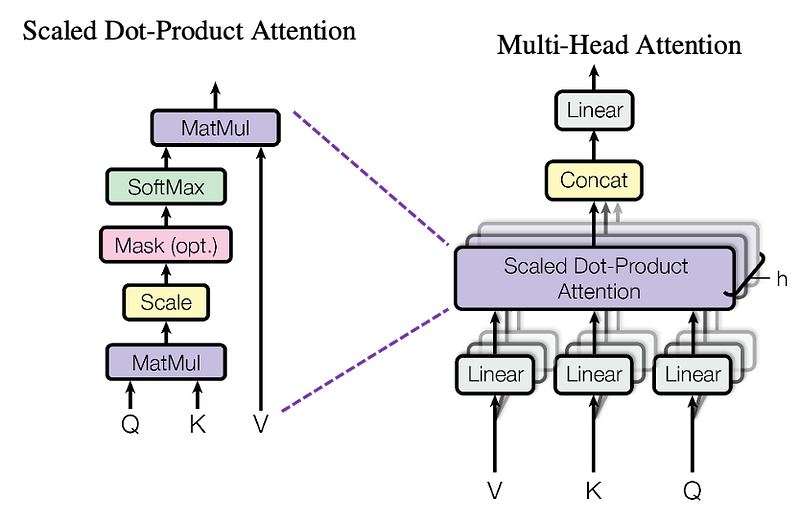
4.1 How Multi-Head Attention Works
The multi-head attention mechanism involves the following steps:
1. Linear Projections: The input is linearly projected into multiple sets of queries, keys, and values. Each set corresponds to a different attention head. For i=1,2,…,h.
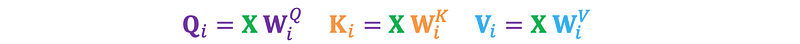
where Q_i, K_i, and V_i are learned weight matrices for the i–th head.
2. Scaled Dot-Product Attention: Each set of queries, keys, and values matrices undergoes the scaled dot-product attention mechanism independently.
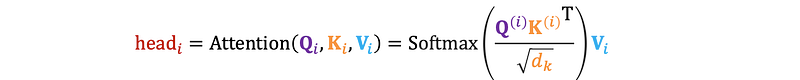
3. Concatenation: The outputs of all attention heads are concatenated.
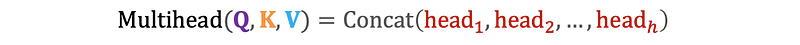
4. Final Linear Projection: The concatenated output is then projected using another learned weight matrix to produce the final output.
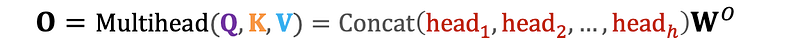
where W^O is the weight matrix for the final linear projection.
4.2 Advantages of Multi-Head Attention
- Captures Multiple Relationships: Multi-Head Attention enables the model to capture multiple relationships within the sequence, improving its ability to focus on different parts of the data.
- Better Representation of Complex Dependencies: It allows better representation of complex dependencies and context. By using multiple attention heads, the model can learn different aspects of the input sequence simultaneously.
5. Cross-Attention
Cross-attention is a mechanism used in sequence-to-sequence models, such as in the Transformer’s encoder-decoder structure. Unlike self-attention, which works within the same input sequence, cross-attention allows the decoder to attend to the encoder’s output.
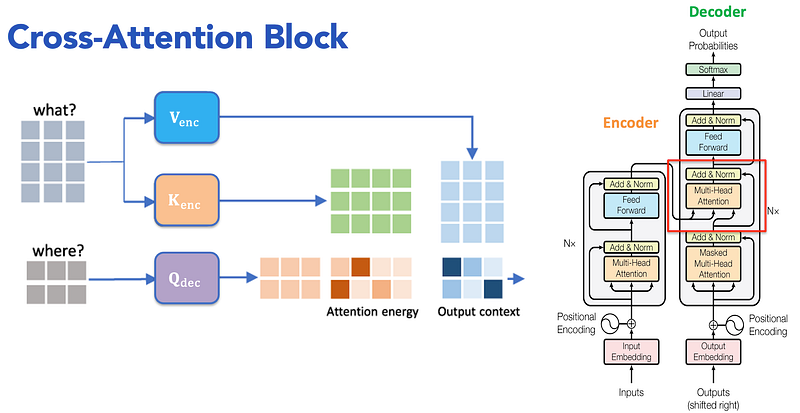
5.1 How Cross-Attention Works
Decoder Uses Cross-Attention: The decoder uses cross-attention to focus on the encoder’s output sequence while generating each token in the output sequence.
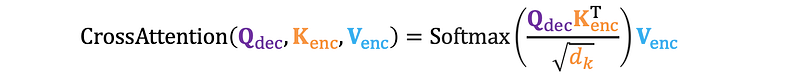
Queries, Keys, and Values: The decoder generates queries from its own hidden states, and the keys and values are generated from the encoder’s output states.
5.2 Importance of Cross-Attention
Cross-attention acts as the bridge between the encoder and decoder in a transformer model, enabling the model to learn different language conversion patterns between the two sequences, leading to more accurate and fluent translations.
6. Masked Self-Attention
In addition to cross-attention, the Transformer decoder also employs Masked Self-Attention, also known as Causal Attention.
6.1 How Masked Self-Attention Works
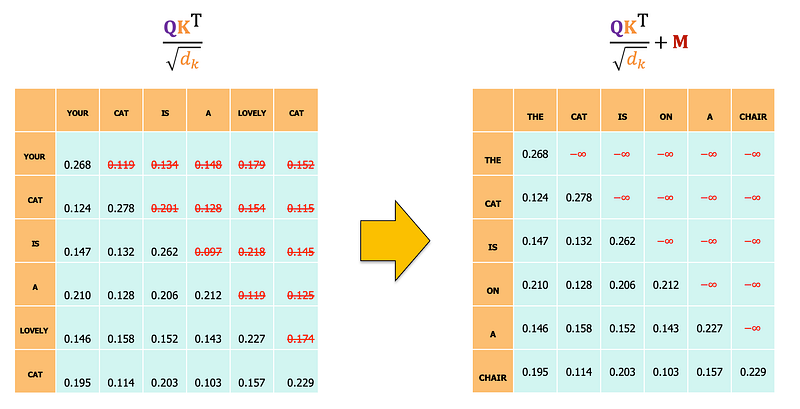
Masked multi-head attention prevents each token from attending to future tokens by introducing a mask. This is implemented by:
- Masking future tokens: Each token is prevented from attending to tokens that come after it.
- Modifying attention scores: The attention scores of future tokens are set to a very large negative number.
- Applying softmax: The modified attention scores are then passed through the softmax function, effectively zeroing out the attention to future tokens.
The masked self-attention mechanism can be described by the following equations:

where M is mask matrix, where M_ij=-∞ for j>i and M_ij=0 otherwise.
By adding M to the scaled dot-product, the attention scores for future tokens become very small. After applying the softmax function, these scores are effectively zero, ensuring that the model does not attend to future tokens.
Why It Matters: Masked Multi-Head Attention allows the model to generate coherent and contextually accurate sequences without peeking onto future information, maintaining the integrity of sequential data processing.
6.2 Masked Multi-Head Attention
Masked Multi-Head Attention is a type of Masked Self-Attention that uses multiple heads.
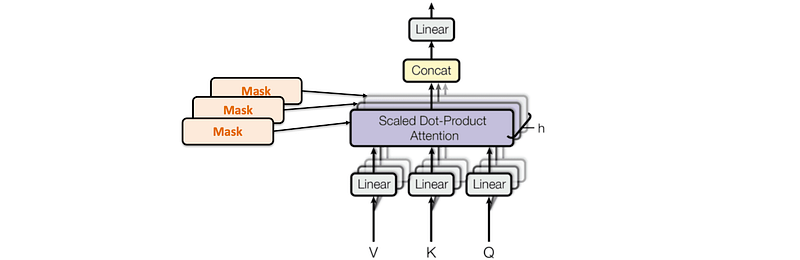
This mechanism can be described by the following equations:
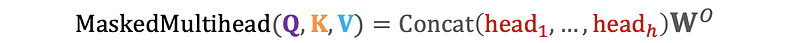
where
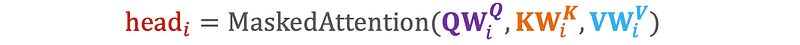
By using multiple heads, the model can attend to different parts of the input sequence simultaneously, capturing complex dependencies between tokens while ensuring that each token only attends to past tokens.
7. Transformer Architecture
The Transformer architecture is designed to handle sequence-to-sequence tasks efficiently. It consists of an encoder and a decoder, both of which are built using stacked layers of self-attention and feed-forward neural networks.
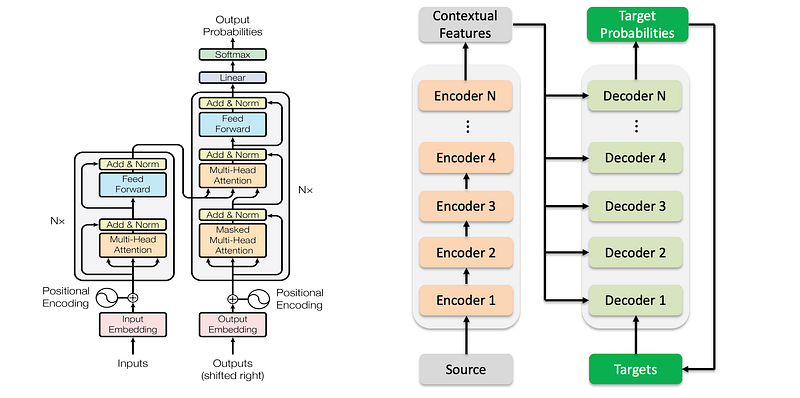
7.1 Encoder
The encoder processes the input sequence and transforms it into a continuous representation that the decoder can use.

The Transformer encoder consists of multiple identical layers, each with two main sub-layers:
- Multi-Head Self-Attention Sub-Layer: This sub-layer enables each token to attend to every other token, capturing dependencies and contextual information. The output is then passed through a residual connection and layer normalization.
- Feed-Forward Neural Network Sub-Layer: This sub-layer applies a simple feed-forward neural network to each position separately and identically. The output is again passed through a residual connection and layer normalization.
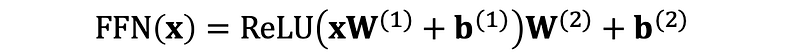
To stabilize the learning process, the Transformer uses:
- Residual Connections: Adding the input of the sub-layer to its output helps mitigate the vanishing gradient problem.
- Layer Normalization: Standardizing the output of each sub-layer to have a mean of zero and a standard deviation of one ensures consistent input distributions to each layer.
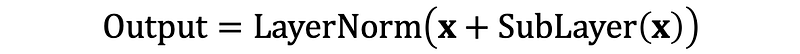
Layer normalization is applied to the combined output of the residual connection to standardize the values. This process helps stabilize training by ensuring consistent input distributions to each layer.
The layer normalization formula involves:
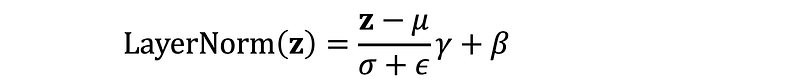
- z: input to layer normalization
- μ: mean of input z
- σ: standard deviation of input z
- ϵ: small constant for numerical stability
- γ: learned scaling parameter
- β: learned shifting parameter
The normalized output has a mean of 0 and variance of 1, which helps maintain stable gradients and improves training efficiency.
7.2 Decoder
The decoder generates the output sequence one token at a time, attending to both the encoder’s output and the previously generated tokens.

The Transformer decoder consists of multiple identical layers, each with three main sub-layers:
- Masked Multi-Head Self-Attention Sub-Layer: Similar to the encoder’s self-attention, but with masking to prevent attending to future tokens.
- Multi-Head Cross-Attention Sub-Layer: Allows the decoder to attend to the encoder’s output, incorporating input sequence information.
- Feed-Forward Neural Network Sub-Layer: Applies a feed-forward neural network to each position, identical to the encoder’s sub-layer.
Each sub-layer’s output is passed through a residual connection and layer normalization to stabilize the training process.
8. Positional Encoding
Since the Transformer model does not have any recurrent structure, it lacks a built-in mechanism to understand the order of tokens in a sequence. To address this, positional encoding is added to the input embeddings. Positional encoding is a vector that encodes the position of each token in the sequence, allowing the model to capture the order of tokens.
8.1 How Positional Encoding Works:
Positional encodings are added to the input embeddings before they are fed into the encoder or decoder. These encodings are designed to have unique values for each position, enabling the model to distinguish between different positions in the sequence.
Positional encodings are mathematical representations that are added to the input embeddings before the encoder and decoder stacks process them. The most common approach uses sine and cosine functions of different frequencies to generate these encodings. The formulae for the positional encodings are:
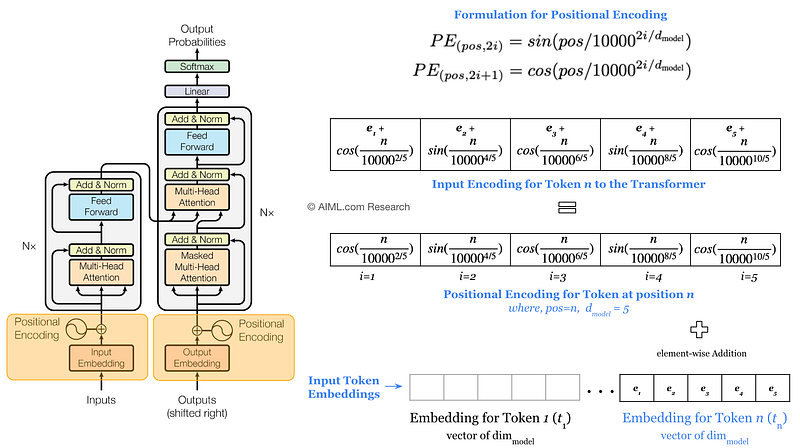
These sine and cosine functions ensure that each position in the sequence has a unique encoding. Additionally, the use of different frequencies allows the model to distinguish between different positions in a way that is both smooth and continuous. This is important for the model to effectively learn the relative positions of the tokens.

These encodings are added to the original input embeddings to give each token a sense of its position in the sequence. By using sine and cosine functions with different frequencies, the positional encodings ensure that each position has a unique representation, and the encodings vary smoothly, which helps the model learn to distinguish between different positions effectively.
The use of sine and cosine functions in positional encodings offers several advantages:
- Periodicity: The functions’ periodic nature helps capture relative positions in sequences of varying lengths.
- Unique Encodings: Each position has a unique encoding due to different frequencies, allowing the model to distinguish between positions.
- Smoothness: The smooth variation of sine and cosine functions enables the model to easily learn patterns in the positional encodings.
9. Transformer Model Specifications
- Model Sizes: The original Transformer architecture features configurations with 6 layers each for the encoder and decoder, amounting to roughly 65 million parameters.
- Context Length: The maximum context length for the original Transformer was set to 512 tokens. This limit is determined by the model’s architecture and its positional encoding scheme.
- Embedding Dimension: The embedding dimension for the original Transformer is 512. This dimension is used for both input embeddings and the output of each layer.
- Model Dimension: The model dimension, which refers to the size of the hidden states in the transformer, is also 512. Each attention head in the multi-head attention mechanism has a dimension of 64, allowing for a total of 8 attention heads (since 512÷64=8).
These specifications contribute to the efficiency and effectiveness of the Transformer model in various natural language processing tasks, particularly machine translation.
10. Training and Inference
- Training: During training, the model is trained using teacher forcing, where the ground truth output sequence is fed into the decoder. The loss function is typically the cross-entropy loss between the predicted tokens and the ground truth tokens.
- Inference: During inference, the model generates the output sequence one token at a time. The previously generated tokens are fed back into the decoder to generate the next token, until the end of the sequence is reached.
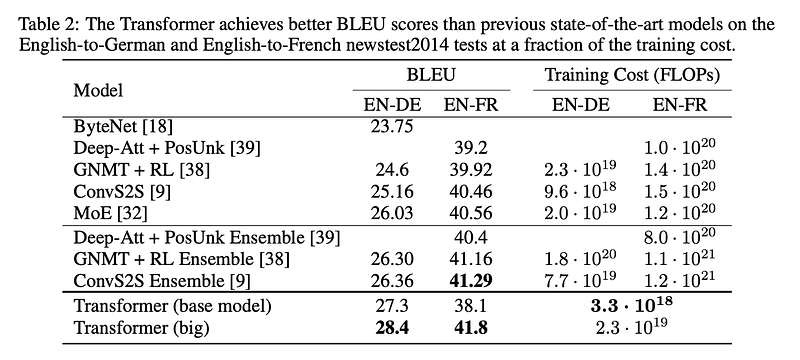
10.1 Transformer’s Machine Translation Results
The Transformer model outperforms all previously released models and combinations, while being trained at a much lower cost compared to other competitive models. BLEU is a metric that measures how similar the machine-generated translation is to a set of reference translations.
11. Advantages of the Transformer Architecture
- Parallelization: The self-attention mechanism allows for parallel computation, enabling faster training compared to recurrent models like RNNs and LSTMs.
- Long-Range Dependencies: The Transformer model can capture long-range dependencies effectively, thanks to the self-attention mechanism.
- Flexibility: The Transformer architecture is highly flexible and can be adapted to various sequence-to-sequence tasks, including machine translation, text summarization, and more.
12. Conclusion
The Transformer architecture, with its innovative use of self-attention and multi-head attention mechanisms, has revolutionized the field of NLP. Its impact is primarily due to:
- Efficient Parallelization: Replacing LSTM with self-attention mechanisms enabled parallelized training, accelerating the process.
- Robust Design: Integrating components like positional encoding and multi-head attention resulted in a scalable and reliable model.
- Enduring Hyperparameters: The original hyperparameters remain stable and widely used, demonstrating their robustness across various tasks and datasets.
Overall, the Transformer’s innovative design and stable hyperparameters have made it a cornerstone in the field. Understanding the intricacies of self-attention, multi-head attention, cross-attention, and the overall architecture of Transformer models is crucial for leveraging their power in modern NLP applications.


