
Efficient Self-Attention Mechanisms: MQA, GQA, SWA, Flash and Page Attentions
The Transformer architecture, which underlies many advanced Large Language Models (LLMs) like OpenAI GPT or Meta LLaMA models, heavily relies on the Multi-Head Attention (MHA) mechanism. However, this mechanism can be computationally intensive. To address these challenges, several innovative optimizations have been recently developed and integrated into state-of-the-art models. This discussion will revisit the fundamentals of the self-attention mechanism and focus on two key optimization approaches: minimizing memory bandwidth usage and accelerating the attention layers. Specifically, it will examine techniques such as Multi-Query Attention (MQA), Group-Query Attention (GQA), Sliding Window Attention (SWA), as well as Flash Attention and its updated version, Flash Attention v2, and Page Attention, highlighting their contributions to enhancing efficiency and speed.
Self-Attention Mechanism
The self-attention mechanism is the cornerstone of Transformer models, making them exceptionally powerful. Introduced in the groundbreaking paper “Attention is All You Need” published in mid-2017, this mechanism allows models to consider the context of other words in a sequence. The basic formular of self-attention is listed below:
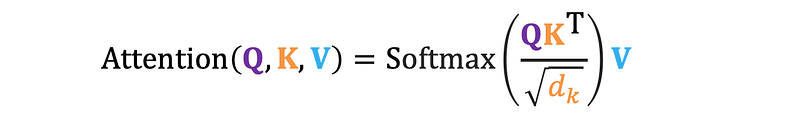
Understanding the Challenges of Self-Attention
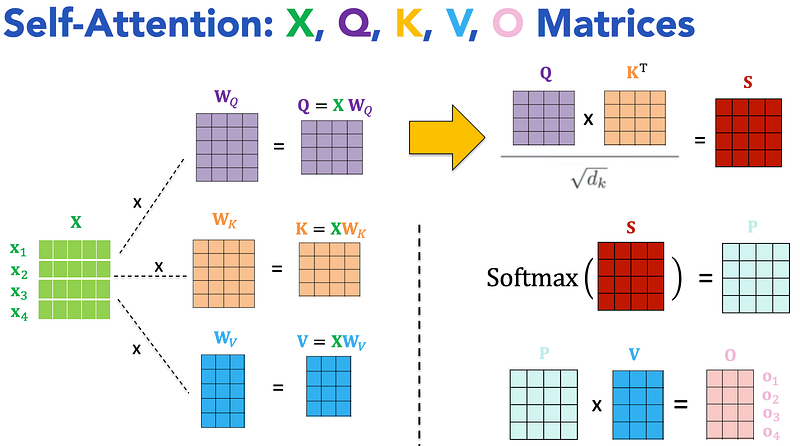
In this article, we want to understand what’s problematic about this self-attention mechanism. From a computational perspective, we are multiplying large matrices with substantial dimensions. This is because the sequence length can involve hundreds, if not thousands, of tokens, and the embedding dimensions can also be in the hundreds or more. The main issue here is that we are multiplying very large matrices every time we encode or decode an input sequence. Whether we’re training or running inference, we’re multiplying these matrices, leading to quadratic complexity for both compute and memory access.
Quadratic complexity means that the complexity grows with the square of the sequence length. So, if you double the sequence length, the compute complexity and memory access complexity increase fourfold. If you quadruple the sequence length, it increases 16-fold, and so on.
In the early days, Transformers had a relatively short sequence length of 512 tokens. By 2023, the context window of LLMs had expanded to around 4K-8K tokens. However, by July 2024, LLMs with context windows exceeding 128K tokens became commonplace. For instance, Claude 2 features a 100K context window, while Gemini 1.5 claims a context window of 2M tokens. Later, LongRoPE pushed the boundaries even further, extending the LLM context window beyond 2 million tokens.
Particularly for inference, long-context LLMs becomes a significant problem. As the contexts grow larger, especially with the popularity of retrieval-augmented generation, inference becomes very expensive.
Multi-Head Attention (2017–06)
Multi-head attention (MHA), the core of Transformer models like GPT, splits attention across multiple “heads” to capture richer relationships in data.
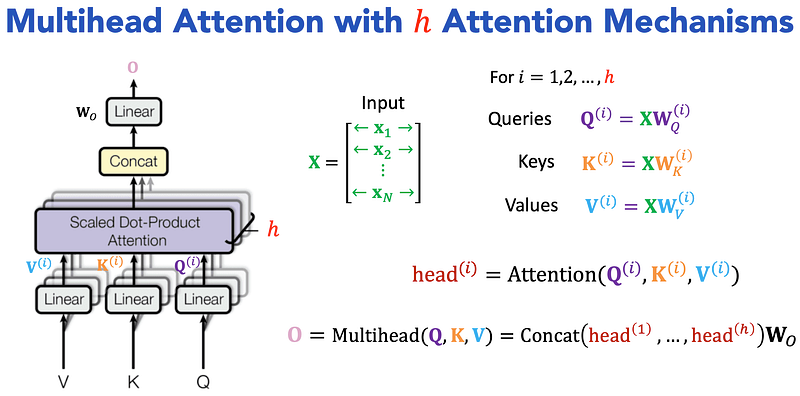
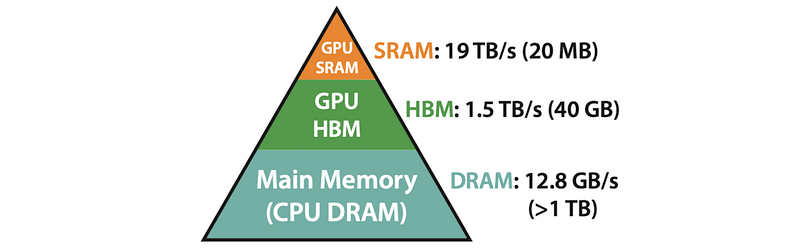
While effective, MHA faces a significant challenge: memory access. The core of MHA involves manipulating large matrices representing the Keys (K), Values (V), and Queries (Q). These matrices are typically stored in High Bandwidth Memory (HBM), which, despite its name, is located off-chip. This means that every time the GPU needs to perform calculations, it needs to load these massive matrices from HBM, a process that can be surprisingly slow.

The Memory Bottleneck in MHA
The constant shuttling of data between the GPU and HBM creates a bottleneck in MHA. This bottleneck becomes even more pronounced as models grow larger and handle longer sequences, leading to increased training and inference times. The result? Slower models that struggle to keep up with the demands of modern AI applications.
Multi-Query Attention (2019–11)
Now that we understand the memory-intensive nature of the self-attention mechanism, let’s look at the first optimization invented to address this issue: Multi-Query Attention (MQA).
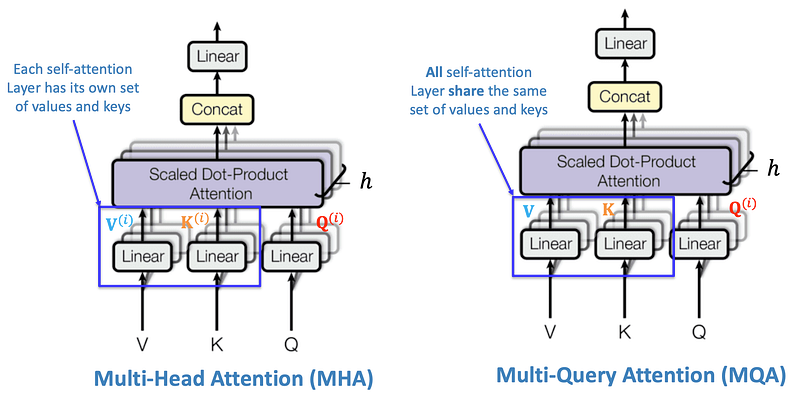
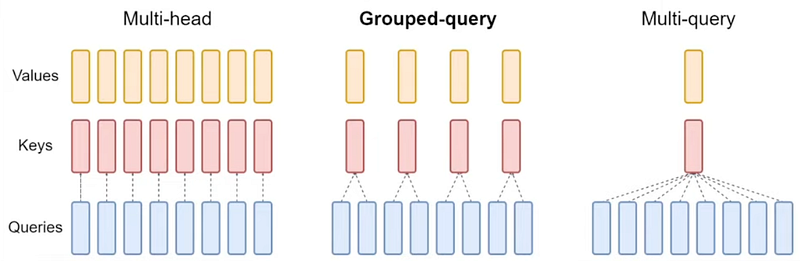
On the left of the above diagram, we have the standard multi-head attention mechanism, which we’ve just discussed. On the right, we have MQA, which looks almost identical at first glance. However, there’s a crucial difference. In multi-head attention, each head has its own set of values V^(i) and keys K^(i) matrices. This means each head needs to load its own V and K tensors, leading to significant memory access costs.
The Key Difference in MQA
In MQA, instead of each head having its own V^(i) and K^(i) tensors, all heads share the same set of V and K tensors. For instance, if we have 32 heads, instead of loading 32 V^(i) tensors and 32 K^(i) tensors, we only need to load one V tensor and one K tensor. This results in a substantial reduction in the amount of data that needs to be loaded from high bandwidth memory (HBM).
Benefits of MQA
- Reduced Memory Access: By sharing V and K tensors across all heads, MQA significantly reduces the memory access requirements.
- Increased Decoding Speed: MQA is reported to be up to 12x faster than standard multi-head attention, leading to a significant speedup in decoding.
- Efficient Memory Usage: With less data to load and cache, MQA uses less GPU memory, allowing for larger batch sizes and more efficient training and inference.
MQA Trade-offs
MQA is implemented in models like Falcon 7B Language model. While MQA offers substantial speed and memory benefits, it comes with a few trade-offs:
- Small Accuracy Drop: Since MQA uses fewer parameters (a single K and V for all heads), there is a slight accuracy drop. This is a compromise between accuracy and speed.
- Retraining Requirement: Models need to be trained specifically with MQA. You can’t take a model trained with multi-head attention and run inference with MQA without retraining.
- Limited Tensor Parallelism: MQA is less compatible with tensor parallelism techniques because the unique K and V tensors need to be replicated across all nodes in a distributed cluster, which is not an efficient use of resources.
Group-Query Attention (2023–05)
Next, let’s explore Group-Query Attention (GQA), which strikes a balance between multi-head attention and multi-query attention (MQA).
As shown in the top graph, standard multi-head attention uses one keys and one values tensor per head. On the right, we have MQA, which uses a single keys and values tensor for all heads. GQA finds a middle ground by grouping heads and sharing keys and values tensors within each group.
How GQA Works
GQA introduces a new hyperparameter: the group size. Instead of having one keys and values tensor per head or one for all heads, GQA allows for one keys and values tensor per group of heads. For example, you might have one keys and values tensor for every two, four, or eight heads.
Benefits of GQA
Experiments on T5 XXL showed that GQA can achieve nearly the same performance as multi-head attention while being almost as fast as MQA. This makes GQA an interesting technique that balances performance and speed.
- Flexibility: You can tweak the group size to find the optimal balance between performance and memory optimization.
- Efficiency: With the right group size, GQA can be almost as fast as MQA while maintaining the performance of multi-head attention.
GQA Trade-offs
GQA is implemented in LLaMA 2. Unlike MQA, models can be up-trained from existing multi-head attention models, requiring only a bit of additional training rather than a full retraining process. Additionally, GQA is more compatible with tensor parallelism, as it allows for splitting multiple keys and values tensors across GPUs, making better use of hardware resources.
Sliding Window Attention (2020–04)
In vanilla attention, we compute attention scores for all token pairs during inference, while masking future tokens to prevent the decoder from looking ahead. This results in a triangular-shaped attention mask and a quadratic complexity problem.
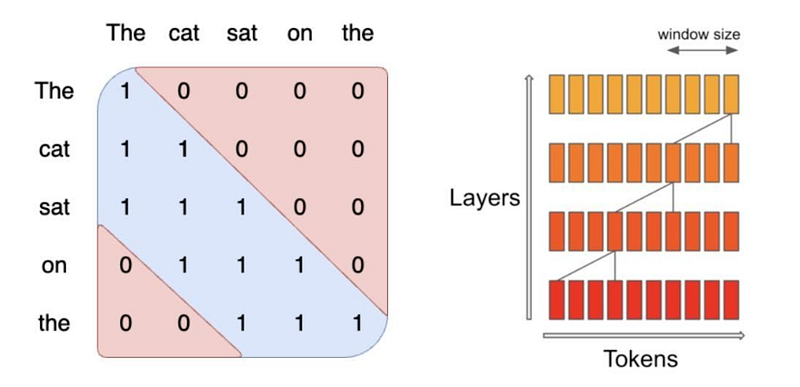
Sliding window attention (SWA) addresses this by limiting the self-attention computation to a fixed window size. For instance, Mistral uses a 4KB window. This means that each layer can only see up to 4K tokens from the previous layer. If the sequence length is shorter than the window size, this optimization makes no difference. However, as the sequence length scales, the window starts to apply, reducing the attention complexity from quadratic to linear and speeding up inference.
How SWA Works
- Fixed Window Size: Limits the self-attention computation to a fixed window (e.g., 4KB for Mistral).
- Sequence Length Impact: If the sequence length is shorter than the window, there’s no difference. As the sequence length scales, the window applies, reducing complexity.
- Maximum Context Size: The maximum context size is the window size multiplied by the number of layers (e.g., 31K for Mistral).
Benefits of SWA
- Reduced Complexity: Transforms the quadratic complexity problem into a linear one.
- Faster Inference: Speeds up inference by limiting the attention span.
- Full Sequence Visibility: Although each layer sees only a window of the sequence, the model as a whole sees the full sequence length by propagating the window across layers.
Implementation
The implementation of sliding window attention is more complex than previous techniques but still understandable. You can explore the code to see how it works in practice.
Flash Attention (2022–05)
The main challenge with self-attention is the speed of high bandwidth memory (HBM) compared to on-GPU memory. Flash Attention addresses this by minimizing the back-and-forth data transfer between HBM and the GPU.
How Flash Attention Works
Flash Attention performs the standard attention computation, including matrix multiplications, but with a key difference: it loads the matrices (Q, K, V) only once. It then uses a clever tiling algorithm to compute the full matrix operations incrementally within the GPU’s faster SRAM. This approach reduces the need to constantly load and write data to HBM, making the process more efficient.
Key Benefits of Flash Attention
- Reduced HBM Memory Access: By loading matrices once and using SRAM for computations, Flash Attention minimizes HBM access.
- Parallelization: The algorithm parallelizes operations over batch size and the number of heads, leveraging GPU cores for significant speedup.
- Linear Memory Complexity: Although the complexity is still quadratic with respect to sequence length (N) and embedding length (D), Flash Attention reduces it to linear by dedicating some on-GPU memory to cache operations. This results in memory complexity proportional to N, making it much more efficient.
Performance Improvements
- Speed: Flash Attention is 2–4x faster in terms of inference.
- Memory Savings: It saves 10–20x memory, allowing for larger batch sizes and more efficient training and inference.
- Dual Optimization: Flash Attention optimizes both forward and backward passes, accelerating training as well.
Flash Attention v2 (2023–07)
Flash Attention v2 is an enhanced version of Flash Attention, aiming to further optimize the self-attention mechanism. Here’s what it does:
- Eliminate Non-Matrix Operations: Flash Attention v2 minimizes scalar and vector operations, focusing on matrix multiplications that GPUs can accelerate more efficiently. The algorithm is rewritten to reduce operations that can’t be fully parallelized and accelerated by the GPU.
- Optimize for MQA and GQA: With the rise of Multi-Query Attention (MQA) and Group Query Attention (GQA), Flash Attention v2 includes optimizations for these techniques. MQA and GQA reduce the number of key and query tensors, and Flash Attention v2 capitalizes on this to further improve efficiency.
Benefits of Flash Attention v2
- Increased Parallelism: Flash Attention v2 introduces even more parallelism, especially across the sequence length, which can be thought of as sequence parallelism.
- Speed Improvements: It is 2x faster than the previous version and up to 9x faster than standard attention.
- Efficient Training: It optimizes both forward and backward passes, accelerating training as well.
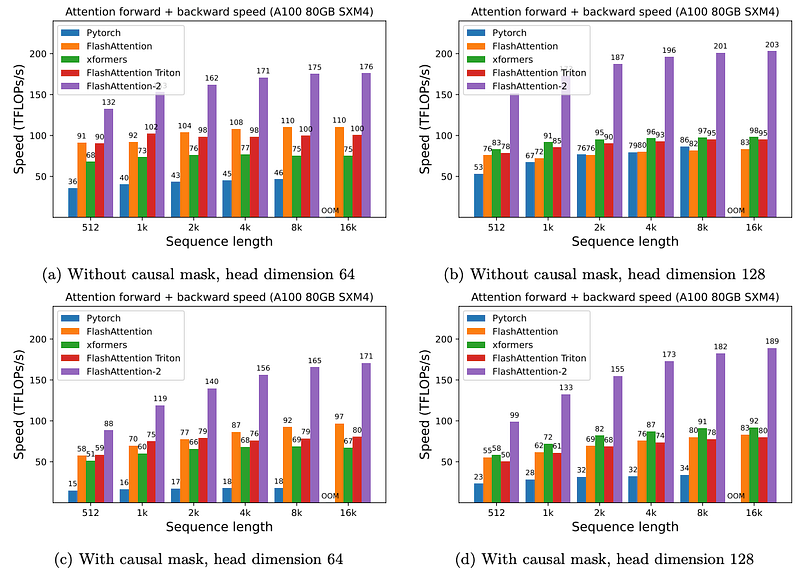
Performance Metrics
- Inference Speed: On the left graph, you can see the forward speed (inference) with Flash Attention v2 outperforming both vanilla PyTorch and Flash Attention v1.
- Training Speed: On the right graph, you can see significant speedups for both forward and backward passes, indicating faster training times.
Flash Attention v2 is available in the Text Generation Inference (TGI) server, and you can enable it with just one parameter.
Page Attention (2023–09)
Page Attention is a newer approach that tackles a different problem: memory fragmentation in the Key-Value (KV) cache. The KV cache stores intermediate calculations and grows and shrinks with each inference request, leading to memory fragmentation. This is a classic operating system problem, where dynamic memory allocation and deallocation result in fragmented memory.
How Page Attention Works
- Fixed-Size Blocks: Page Attention chunks memory into fixed-size blocks called pages, similar to virtual memory systems in operating systems.
- Reduced Fragmentation: By allocating and deallocating memory in fixed-size pages, Page Attention reduces both external and internal fragmentation. This ensures that memory is used more efficiently, with no empty intervals between pages.
Benefits of Page Attention
- Efficient Memory Management: Better memory management on the GPU allows for increased batch sizes, which is crucial for accelerating GPU operations.
- Improved Performance: By reducing fragmentation, Page Attention enhances the overall performance of the attention mechanism.
Page Attention is also available in the Hugging Face TGI server, offering a unique approach to accelerating and improving attention mechanisms.
Conclusion
In summary, the race for faster Transformers has led to significant innovations in optimizing the self-attention mechanism. Techniques like Multi-Query Attention (MQA), Group-Query Attention (GQA), Slide-Window Attention (SWA), Flash Attention, Flash Attention v2, and Page Attention have each addressed different aspects of the computational and memory challenges posed by self-attention.
MQA and GQA focus on reducing memory access by sharing keys and values tensors across heads, striking a balance between performance and efficiency. SWA limits the attention span to a fixed window, reducing complexity from quadratic to linear. Flash Attention and its successor, Flash Attention v2, minimize HBM access and optimize parallelization, leading to significant speedups and memory savings. Page Attention tackles memory fragmentation, ensuring more efficient memory management on the GPU.
References
[1] Transformer (Attention Is All You Need): https://arxiv.org/abs/1706.03762
[2] MQA: https://arxiv.org/abs/1911.02150
[3] GQA: https://arxiv.org/pdf/2305.13245
[4] SWA (Longformer): https://arxiv.org/abs/2004.05150
[5] Flash Attention: https://arxiv.org/abs/2205.14135
[6] Flash Attention v2: https://arxiv.org/pdf/2307.08691
[7] Page Attention: https://arxiv.org/abs/2309.06180
[8] Deep dive — Better Attention layers for Transformer models



