
Translate SQL Grouping Sets to Python
How to handle the multi group by of PostgreSQL 9.5 in Pandas
After understanding how grouping sets exactly works, we will see how to write a Python function to do it, using Pandas
SQL : Grouping set
The super useful multi grouping of Postgres 9.5. It creates the union of different grouping. Let’s create a table for our example :
— create a table
CREATE TABLE students (
name Text Not null,
class TEXT NOT NULL,
gender TEXT NOT NULL,
grade INTEGER NOT NULL
);
— insert some values
INSERT INTO students VALUES ( 'Pierre',1,1,15);
INSERT INTO students VALUES ( 'Paul',2,1,15);
INSERT INTO students VALUES ( 'Jack',1,1,14);
INSERT INTO students VALUES ( 'Marie',1,2,12);
INSERT INTO students VALUES ( 'Lea',2,2,18);
INSERT INTO students VALUES ( 'Nath',2,2,10);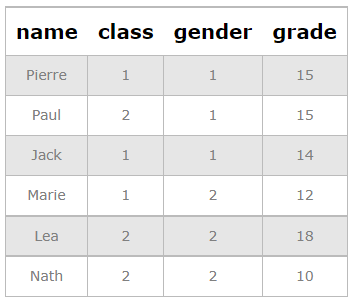
Objective: Calculate the average per class, and the average per gender.
If we want to calculate in the same table, the average of the grades per class and per gender, we could calculate the average per class in one table, the average per gender in another one, then join both vertically. This is exactly the purpose of the grouping set of Postgres:
— fetch some values
SELECT class,gender,AVG(grade)
FROM students
GROUP BY GROUPING SETS (class,gender);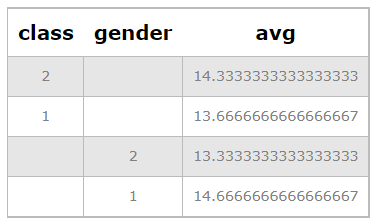
Try these queries here : https://extendsclass.com/postgresql-online.html
In Pandas
import pandas as pddf= pd.DataFrame(
{'name':['Pierre','Paul','Jack','Marie','Lea','Nath'] ,
'class': ['Class 1','Class 2','Class 1','Class 1','Class 2','Class 2'] ,
'gender': ['M','M','M','F','F','F'] ,
'grade': [15,15,14,12,18,10]})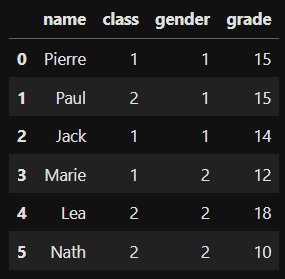
We need to create the two group by and then join them. We could use the basic function groupby.
df_temp=df.groupby(by='class').mean().reset_index()Why is it not working ? because it will also calculate the mean() of the column gender, which is a numerical value.
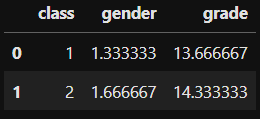
As we want to continue on the same path, we can calculate it this way, but then, drop the column we don’t want, here it’s the gender
df_temp.drop(columns='gender')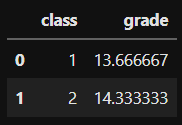
How to put everything in a function?
The first objective of the function is to be able to take as a parameter as many column we want to feed the grouping set. We will enter this parameter in a list. We will then loop over this list.
def group_set(df,list_groupset):
#initialzation for the Concatenation
data=pd.DataFrame() for group in list_groupset :
#Group by on one of the list
df_temp=df.groupby(by=group).mean().reset_index()
#Which column do we need to delete ?
list_groupset_temp=list(list_groupset)
list_groupset_temp.remove(group)
df_temp=df_temp.drop(columns=list_groupset_temp)
#Merging the different group by
data=pd.concat([data,df_temp])
return(data)list_groupset = ['class','gender']
group_set(df,list_groupset)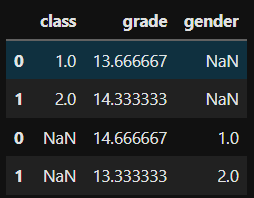
If you liked this story, you can check my latest post here:




