
Analyze Facebook Messenger Data with Python and Pandas
How to download Facebook Data, open them with pandas and find the best behavior’s insights

Hey, medium! Who would like to have a magic wand to go back in the past and find lots of fun facts in our friend’s conversations? Thanks to the law on private data, we can access all our previous conversations on Facebook, and who says data, says Python and graphs!
This dive into my messenger conversations comes from one question: What the heck is going on in the group conversation with my friends? There are websites where you can print your whole conversation on books, and share it with your friends. First of all, I don’t want all the photos from this discussion to be spread around the world. Second, This would be a way too huge book for me to read, we have around 50k messages spread on mostly 10y of Facebook experience in this single thread. This is why I wanted to do what I know how to do: Run some analyses on the data we have at hand. This will be my late Christmas gift to them. Some fun on a chocolate bar as we say here.
We will first see :
- How to get our messages back and understand how to read it
- What we can dig into it and focus on a specific question
- Try to put it all together and look at those beautiful results
If you want to do it for yourself, all my code is accessible here: Messenger_Podium. I will presume that you already have a running Python environment on your computer, either in a Jupyter Notebook or in an IDE. If you are not familiar with Python, just jump with us and see all we can do here!! That’s a fun project to enter the world of data science.
(Ps: I’m shocked, I just understood right now the pun joke with JupYter)
Get Back Our Data and Understand it
Thanks, Facebook for letting us play
Sorry, I’m French. And thus, Facebook is in French for me, but you should be able to follow me on this :
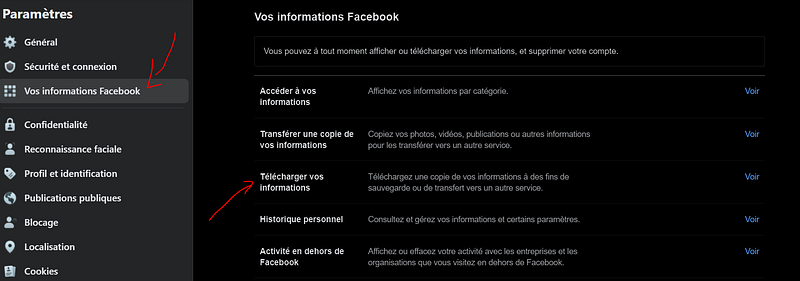
In “Parameters”, “Your information” — Download your information. I downloaded only my messages, and for the past 3years.
You can do more, but I wanted here only to look at my messages on one conversation in 2021.
You can either download them in HTML or JSON. JSON will be way easier to work on, so let’s just take it in JSON.
We now have all our conversations, on the past 3years.
I’m jumping directly on the conversation that interests me. I have one conversation, with my oldest friends. We send messages there every day, so it’s my chat with the more messages. There, we can find EVERYTHING, from the pictures to the voicemail, passing by the messages. Let’s focus only on the messages. If you would like me to have a project also on photos and voicemail leave it in the comments
What is a JSON file? If you are here, I assume you already know how a JSON works. If not, my friend, Omar, explained it nicely here: JSON-in-a-nutshell. In my chat, there are 5 JSON files, all containing messages on different periods. The first object is the list of participants, the second object of the JSON is the messages.
Open Messenger data with Pandas
I love to work with Pandas because I’m used to it. I think it is also really well suited for this project, as one row can be interpreted as one message.
import pandas as pd
import jsondef load_all_messages(path):
# Open first the first message
file = open(path + 'message_1.json')
#Here we have the decoder from messenger
data = json.load(file, object_hook=parse_obj)
df = pd.json_normalize(data['messages'])
#Then open the other ones and append them
#Would need to change that to apply to every number of files needed
for i in np.arange(2,6) :
file = open(path + 'message_'+str(i)+'.json', encoding='utf8')
data = json.load(file, object_hook=parse_obj)
df_temp = pd.json_normalize(data['messages'])
df=df.append(df_temp)
return (df)Spoiler Alert : Facebook (Meta now), did not encode the JSON in a good way, we need a trick here to access the content
def parse_obj(obj):
for key in obj:
if isinstance(obj[key], str):
obj[key] = obj[key].encode('latin_1').decode('utf-8')
elif isinstance(obj[key], list):
obj[key] = list(map(lambda x: x if type(x) != str else x.encode('latin_1').decode('utf-8'), obj[key]))
pass
return objThanks, Jakub — Original answer: stackoverflow: We need to encode in Latin_1 before decoding it again in UTF-8
We could look at every text and see what going on there, but as data scientists, could we do that in another way?
As we said, let’s focus on messages. What information is there? We have the timestamps of the messages, the content itself, the author, and the reactions.
def clean_data(df):
#We want a usable time stamp
df['date_time']=pd.to_datetime(df['timestamp_ms'], unit='ms')
#Way easier to work with lower cases for text
df['content']=df['content'].str.lower()
#Let's not work first with every data --> Only text
df.drop(columns=['timestamp_ms','gifs','is_unsent','photos','type','videos','audio_files','sticker.uri',
'call_duration','share.link','share.share_text','users','files'],inplace=True)
df['year']=df['date_time'].dt.year
#df=df[df['year']==2021]
df['hour']=df['date_time'].dt.hour
df['weekday']=df['date_time'].dt.weekday
#We can exclude some non participing people
df=df[~df['sender_name'].isin([''])]
df['content']=df.content.fillna('')
#df=df[~df['content'].isna()].reset_index()
return (df)What are we looking for?
Here comes the time to ask ourselves questions. What do we want to find and show?
1. The number of messages
The first information we can think of is the number of messages sent by every participant of the conversation. Let’s give an award to the one who sent the most messages in 2021.
2. The number of words per message
Who sent the longest message? With that, we could also think of the average number of words per message. Did someone ever say that the longer the messages you write, the smartest you are? I’m sure you could find an article on that here on medium
3. The time messages were sent
We can see how many messages we send each other per day of the week and per hour of the day. Let’s find one fun behavior here
4. We can find what are the most used words
And once we have it for the conversation, we can find the same per person. This will give us great information about our friend’s behavior on the chat
5. Reactions are a gold mine
With the reaction to the message, we can also try to find out who reacts the more to each other, which were the keystone of the year, and so on.
How do we go from that to the result?
A big part of the data scientist job is to be able to tell a story from the data we have
As I said, if you want to do it for yourself, all my code is accessible here: Messenger_Podium. I will not overload this post with the whole code. Once we have all the information, let’s put it all in excel. The Pandas library is useful as always, and here is one of the best ways to push every data to one final excel. We will use this excel to plot our graphs to PowerPoint
with pd.ExcelWriter("../2. Output/Data.xlsx", engine='openpyxl',mode='w') as writer:
df_grouped_2021.to_excel(writer,sheet_name='grouped',startrow=1)
df_grouped_2020.to_excel(writer,sheet_name='grouped',startrow=15)
sender_list = np.concatenate((df.sender_name.unique(),['all']))
for sender in sender_list :
print(sender)
day_max_message,hours,day,word_max_freq = by_sender(df,temmenized,sender)
day_max_message.to_excel(writer,sheet_name=sender,startrow=0)
hours.to_excel(writer,sheet_name=sender,startrow=5)
day.to_excel(writer,sheet_name=sender,startrow=10)
word_max_freq.to_excel(writer,sheet_name=sender,startrow=15)And now what?

Paul won the chatterbox award, with no less than 3350 messages sent over the year. Far ahead of the other two on the podium, with an average of around 2500. However, Alex does not leave empty-handed with the award for the longest message: 450 words in one go.
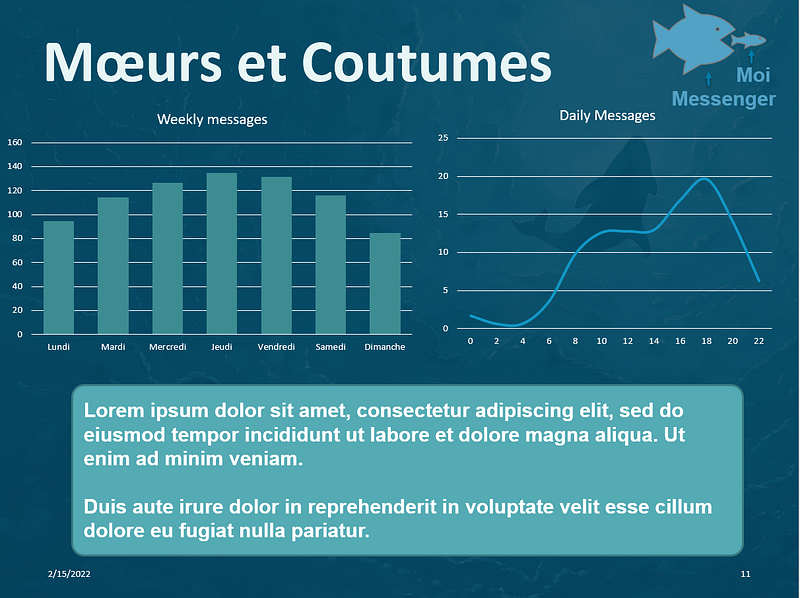
With the weekend coming, it seems that we are starting to get active. Sunday being a sacred day, rest is in order. We clearly see an effect that we will call the “Aperitif” effect on the average number of messages sent per hour with a preferred exchange around 6 p.m.
If you want us to also dive deeper into the messages, and run some NLP analysis on the exchanged text, follow me and leave it in the comments. I was thinking of teaching an algorithm: ‘“how to speak like A ?”. What do you think?
If you like this post, you can check my previous story here :