
The System Design Interview Crash Course— Part 2
The data layer and beyond.
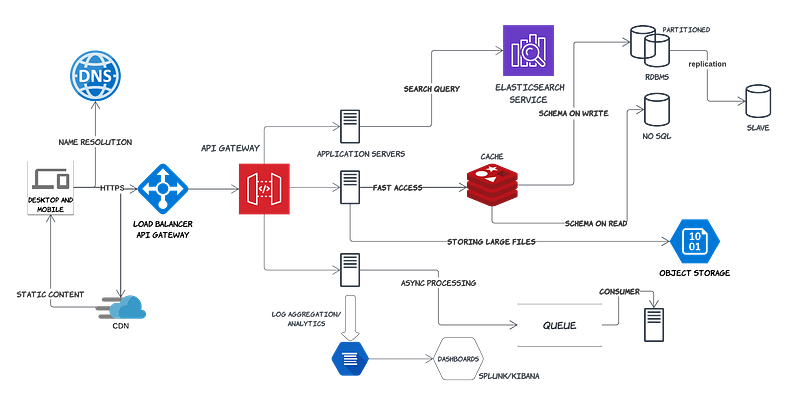
Persistence Layer
We can broadly persist data in Databases or file/blob storage. If you are designing an application like Google Drive or have to store images or large files, you would choose a storage solution like Amazon S3, Azure Object Storage, etc.
Scaling Database Horizontally
To scale a DB horizontally, you would need to partition it into different servers. A common technique to do that is Database Sharding, where data is partitioned into shards and each shard shares the same schema, though the actual data on each shard is unique. For example, if you are building a generic e-commerce website for multiple merchants, you can “shard” the database for individual merchants. The most important factor to consider when implementing sharding is the choice of the sharding key. Two types of sharding are common:
Range-based sharding splits database rows based on a range of values. Say we partition by “username” and use the first character of the user name to determine the partition. (Machine 1 -> A-M, Machine 2->N-Z)
Hash-based sharding uses a hash-like function on an attribute, and it produces different values based on which, the partitioning is performed. A disadvantage of this technique is the “Re-Hashing Problem” and non-uniform distribution of keys leading to hot spots. This can be overcome by a technique called “Consistent Hashing” where nodes are distributed in a circle and given a range of keys to handle. This is further randomized by using virtual nodes where each virtual node is mapped across different physical nodes.
Data Replication
Data replication refers to keeping multiple copies of the data at various nodes (preferably geographically distributed) to achieve durability and high availability. Going back to CAP theorem, the biggest challenge with replication is keeping the data across all nodes consistent. If we want to assure consistency like, in a banking application, availability and latency would suffer. If we consistency is not primary, “eventual consistency” is well suited for many applications like social media platforms. Most modern database solutions allow you to set a “replication factor” to make this choice. Replication is generally done in 3 ways:
- Single Leader: One of the nodes is chosen as the leader and all writes are directed to it. Secondary nodes are synced with the writes and are capable of handling all the reads. This is useful in scaling read-heavy systems but not great for write-heavy systems. Most RDBMS and MongoDB use this form of replication. “Write Ahead Logs(WAL)” is the common way to perform this replication. Other approaches include Statement-based replication and Row-based replication.
- Multiple Leader Replication: Multiple leader replication is rather uncommon and is mainly used across different data centers or different geographical regions. There are various topologies used to configure these leaders like star or circular.
- Leaderless Replication: This is a common approach in write-heavy systems. Cassandra and Dynamo DB are popular DB tools using this. The consistency issues are generally resolved by “Quorums”, which is to say that if the majority in a group of nodes have acknowledged a write, it is sufficient to confirm that the write was durable. If the majority of nodes confirm the value of a read, it is returned to the client. (w+r>n rule)
Types of Databases and Tradeoffs
This is one of the most common areas to cover in a System Design interview. There are primarily 2 types of databases, SQL-based and NoSQL DBs. Traditional RDBMS or SQL-based systems are well-suited for applications that require strong consistency guarantees. This is guaranteed via ACID properties. They also reduce redundancy in data storage through normalization. This strong consistency guarantee can lead to availability issues. Another challenge with these is the mismatch in their storage format vs the application’s format as they store everything in a tabular structure.
NoSQL DBs try to address this in different ways based on the use case. These include:
- Document-based like Mongo DB or Google Firestore, store data in a JSON-like format. This offers a lot of flexibility when it comes to adding new attributes to the database which is particularly hard in RDBMS. A great use case is for example a Product service for an e-commerce website where attributes vary and schema may keep evolving.
- Key Value stores like DynamoDB, store data in a key-value format, where the key is used to find the data. These are useful for “session-oriented” data where it’s easy to identify an id(session-id) that can be used to store values.
- Graph databases like Neo4J and InfiniteGraph use the graph data structure to store data, where nodes represent entities, and edges show relationships between entities. They are well suited for social networks, financial services, etc.
- Columnar databases like HBase store data in columns instead of rows. They enable access to all entries in the database column quickly and efficiently. Analytics is a prime use case for them.
Your choice of SQL vs NoSQL would depend on the domain, the need for transactions and joins, the need for flexibility in the schema, and the storage/retrieval patterns. SQL-based DBs essentially impose the schema on write through various constraints whereas NoSQL DBs do that on read.
An interesting problem in Microservices architecture is handling distributed transactions across multiple services. One may use protocols like Two-Phase commit or SAGA to handle transactions across all services.
Caching
Retrieval of Data on every API request from DB or a file can be costly and caching the data can help us scale the reads. Caching allows us to keep this data in memory which makes access faster. Further, data can be in a format that is precomputed and ready to return. A cache can be used on the web, application, or Database tier. In any system design interview question where large-scale reads are required like a Twitter or Facebook feed, a cache, specifically a distributed cache is a given. Important things to consider are:
Eviction Policy: This explains how data in a cache is invalidated. “Least Recently Used”, “Most Recently Used”, “Least Frequently Used” and “Most Frequently Used” are the most popular eviction policies.
Writing Policy: This explains whether the data is written first in DB or the cache and thus implicates the consistency between the cache and persistence layer. These include “Write thorough”, “Write back”, and “Write around”.
Popular caching solutions include Memcached and Reddis. Memcached is a simple distributed cache with limited features while Reddis with additional complexity offers more features including rich data types, durable storage, and even a message broker!
Queues
Distributed Messaging Queues are primarily used to support an asynchronous mode of communication and to act as a buffer between the producer and the consumer. Thus, they support a Publisher/Subscriber model and decouple two components of a system. Whenever a heavy computational process is involved like processing large files, images, video transcoding, or even sending bulk emails, a queue comes in handy.
The most popular solutions include ActiveMQ and RabbitMQ known for durability, delivery guarantees, and complex routing support. Kafka is also used as a message broker but it is an event streaming platform that provides high throughput in the pub/sub model. There are many nuanced differences between Kafka and traditional queues and it also isn’t a fair comparison!
Distributed Search
Some interview questions may dive into the distributed search, full-text search, and typeahead needs of a system. TRIE is an important data structure to be aware of. Lucene is the engine that powers most search-based solutions like Elastic and Solr.
An interesting point to remember is that some search engines also provide benefits like Geospatial search based on latitude and longitude, something you can bring up if you are designing such a system.
Distributed Task Scheduling
In some situations, you would need batch jobs to run at regular intervals, like daily, weekly, etc. You would need a scheduler that can assure tasks are completed based on criteria like only once, at least once, or at most once. These need a distributed scheduler like Quartz. The important aspect here is how you would track the completion of such jobs, handle errors and update the state of the resources.
Logging, Monitoring, and Error Handling
It’s always good to spend a few minutes discussing how you would monitor and handle errors. Logging is critical to debugging applications, especially in a distributed, multi-service environment. Splunk and Logstash are widely used for logging while Datadog, Prometheus, and Appdynamics are popular monitoring solutions. You must specify the key metrics you would measure for the system. Also, standard performance measurements in P95, P99 — response time, latency, throughput, and error rate are important to remember.
Dive Deeper
These are fundamentals that would apply to most system design interviews. Hope this is helpful. Deep dive into these concepts and interview questions from these resources:
Beginner: The System Design Primer
Intermediate: Grokking the System Design Interview (Your interview likely read this one too!)
Expert: Designing Data-Intensive Applications, Tech Blogs, https://www.youtube.com/@kleppmann
PS: Tech Wisdom is now on Twitter.