
Start Here: Consistent Hashing
No, it is NOT a solution for hotspots in a Distributed System
Consistent Hashing is a concept that is often echoed in System Design interviews. In many interviews, I have heard candidates say that they would solve the hotspot problem using consistent hashing. However, Consistent Hashing doesn’t solve this, at least not in its crude form. In this article, we will explore Consistent Hashing in detail and what problems it helps to solve in a Distributed System.
Hashing and the Hash Tables
Hashing means mapping any given object to another value or a set of characters, generally, of a fixed length called a “hash”. The algorithm used to generate the hash is called a “hash function”. The idea here is to provide a way to represent data in a condensed form, enabling efficient storage, comparison, and verification of information. Hashing has many applications in security, and data integrity but the one we would focus on is data retrieval.
“Hash tables” provide an efficient way to retrieve information in O(1) time complexity. It is this feature that makes hashtables an attractive data structure for caching, dictionaries, etc. The efficiency of hash tables lies in their ability to distribute key-value pairs across the array, reducing the average time complexity of operations like insertion, retrieval, and deletion to O(1) on average. Hash functions can range from as simple as a modulo function to SHA-256, based on your use case.
Let’s take a simple example. Assume that you want to quickly access customer details in your retail store from an “emailId”. If the ids were all sequential and started from 0, you could simply store them in an array. That would give you an O(1) access. However, these are not sequential nor do they start with 0/1. This is where you can put these into a hash table where a hash function would map an email to a bucket or an array of a certain range for faster access. A simple hash function could take the emailId and map it to a number in the range of say 1–1000. A modulo function is convenient when it comes to mapping a larger range to a smaller bucket. The rest of the trick is in effectively converting a string to a number. A simple hash function would look like the following:
public static int hash(String emailAddress) {
int hash = 0;
int prime = 31; // A prime number used for hashing
for (int i = 0; i < emailAddress.length(); i++) {
hash = (hash * prime + emailAddress.charAt(i)) % 1000;
}
return hash + 1; // Adjust the bucket range to 1-1000
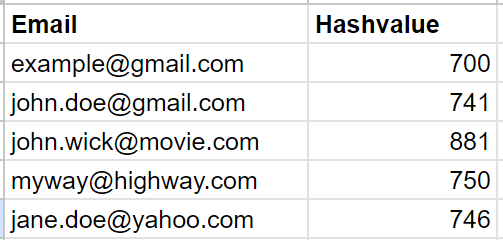
}Running the above code for a few sample emails would return the following results(between 0–999):
Hashing in Distributed Systems
As a modern application scale, it might be hard for us to maintain such a map on a single server. Imagine the scale of Walmart which serves more than 37 million customers every day. While we don’t want all customers’ details in an in-memory map, having even a part of such data would still be huge for a single server. You would likely split it across servers and distribute it based on a certain key. This is what most distributed caches like Memcached manage for you.
Let’s say you have 3 servers to distribute the above data. We can then run modulo 3 on this hash value to identify the server on which particular customer details would sit. Assuming that our servers are labeled a,b, and c for simplicity, we will get a distribution as depicted in the figure below.
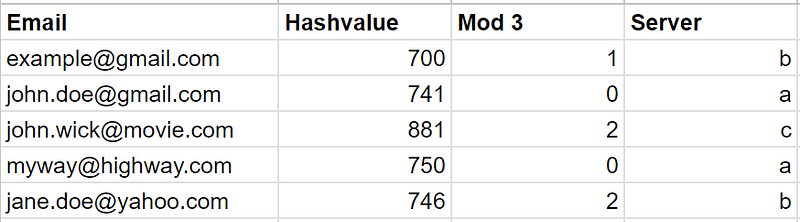
Great! So we have successfully distributed our keys across three different servers. This is a simple scheme and works fine until…the application scales further! Now you need to add more servers. With increasing demand, you added 1 more server. The problem is that all the existing keys have to be redistributed as your function now has to do a modulo 4 instead of 3. The same applies if you reduce the number of servers. This is referred to as the “Rehashing Problem”. Consistent Hashing is one of the mechanisms to contain the impact of this problem.
Consistent Hashing 1.0
Consistent Hashing was first described by Karger at MIT in an academic paper from 1997. Note that, I didn’t refer to this as a technique to solve the rehashing problem. There are always some number of keys that would be moved. We can however minimize that number. It works by assigning the keys to a position on an abstract circle, or a hash ring. This allows servers and objects to scale without affecting the overall system. Let’s understand this by continuing the above example. Imagine you map the entire key range(0–999) on a circle. Then you do the same with the servers you have. Now that both servers and keys are in a circle, you follow a simple rule. Any key would be found in the next server on the circle when moving in a clockwise direction. Thus, the key “[email protected]” in the above example would land on server “a” as shown in the image below.
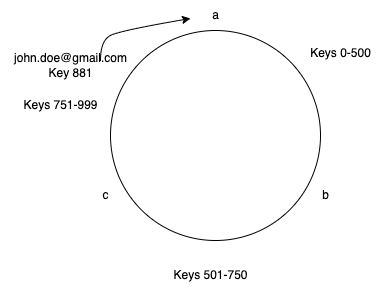
Now imagine you want to add a new node “d” between b and c. As the new server is placed on the circle, the only keys that need to be moved would be between range 501–624 which are currently mapped to node c. Keys 625 to 700 would still land in server c. Note that in the example I am only using ranges for simplicity. A simple way to map the consecutive keys to the circle is to convert them to angles or radians on the circle.
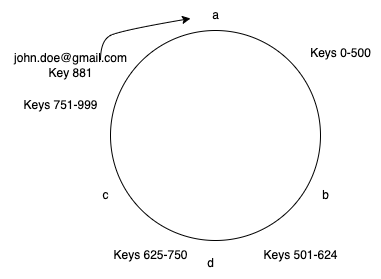
The above example shows how consistent hashing helps to solve the rehashing problem. In general, only k/N keys need to be remapped where k is the number of keys and N is the number of servers.
One may observe that when a node goes down, the next node in the circle might become a “hotspot”, as many keys may end up being directed to it. Further, the key distribution itself might not be uniform(just like simple modulo hashing) and that may result in some servers being overloaded than others. To solve this key distribution problem or skewness, this naive consistent hashing is modified with the introduction of “Virtual Nodes”
Consistent Hashing 2.0
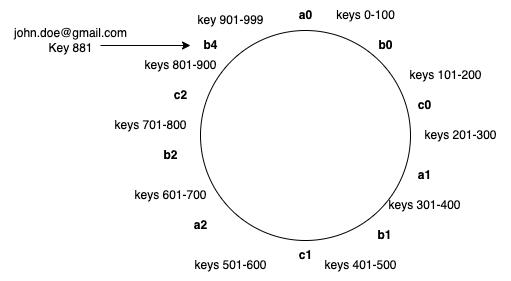
One way to avoid this skewness is to give each server multiple labels(say a1, a2, a3, b1, b2, etc.) Then instead of distributing the real servers, distribute these virtual nodes or labels across the hash ring. The factor by which to increase the number of labels (server keys), known as weight, depends on the situation to adjust the probability of keys ending up on each. For example, if server b were twice as powerful as the rest, it could be assigned twice as many labels, and as a result, it would end up holding twice as many objects (on average).
How does this help? In a few ways actually:
- Having more random distribution of keys. This is because the standard deviation(measures data distribution across the ring) gets smaller with more virtual nodes, leading to balanced data distribution.
- When a server is removed or added, all the keys are no longer just shifted to the next server in the ring, instead these are shifted to the next virtual node in the ring. This ensures a single server is not overwhelmed when a node is removed.
- In some configurations, keys are also replicated across consecutive virtual nodes(some tracking is done to ensure these nodes don’t map to the same physical server). This adds to reliability similar to a master-slave replication.
In our example above one may notice that in the small sample set we used most keys would land on server “c”. Thus it becomes a hotspot. If the virtual nodes were more randomized throughout the key range on the circle, it can lead to a more uniform distribution of the keys on the server. This can further be fine-tuned based on your application heuristics. In our example, introducing such randomization would land [email protected] on b4 virtual node which maps to physical node b and not to node a, as it was earlier.
Consistent Hashing Alternatives
Various hashing techniques can be used as alternatives but this mainly depends on the use case. Some of these include “Modulo Hashing”,“ Jump Hashing”, “Power of Two Choices”, and “Multi-level Hashing”. One particular form of hashing that draws comparisons to Consistent Hashing is Rendezvous Hashing, also known as the highest random weight (HRW) hashing. If key values always increase monotonically, an alternative approach using a hash table with monotonic keys may be more suitable than consistent hashing.
Conclusion
In a Distributed system, the reason for hotspots depends a lot on your domain(variability in workload patterns and data access characteristics) and while there are various techniques to reduce their effect, you cannot eliminate them. A combination of techniques like Data Sharding, Caching, Replication, Load Monitoring, and adjustments based on heuristics would help you minimize their impact.
Hope this helps!