
The State of NLP Literature: Part II
Areas of Research (Examining Terms in Paper Titles)
This series of posts presents a diachronic analysis of the ACL Anthology — Or, as I like to think of it, making sense of NLP Literature through pictures.

(Thanks for your interest in this work. Here is Part I (Size and Demographics) in case you have not already seen it.)
Natural Language Processing addresses a wide range of research questions and tasks pertaining to language and computing. It encompasses many areas of research that have seen an ebb and flow of interest over the years. In this post, we examine the terms that have been used in the titles of ACL Anthology (AA) papers. The terms in a title are particularly informative because they are used to clearly and precisely convey what the paper is about. Some journals ask authors to separately include keywords in the paper or in the meta-information, but AA papers are largely devoid of this information. Thus titles are an especially useful source of keywords for papers — keywords that are often indicative of the area of research. Keywords could also be extracted from abstracts and papers; we leave that for future work.
Further work is also planned on inferring areas of research using word embeddings, techniques from topic modelling, and clustering. There are clear benefits to performing analyses using that information. However, those approaches can be sensitive to the parameters used. In this post, we keep things simple and explore counts of terms in paper titles. Thus the results are easily reproducible and verifiable.
Papers (most pertinent to this post):
- NLP Scholar: A Dataset for Examining the State of NLP Research. Saif M. Mohammad. In Proceedings of the 12th Language Resources and Evaluation Conference (LREC-2020). May 2020. Marseille, France.
- The State of NLP Literature: A Diachronic Analysis of the ACL Anthology. Saif M. Mohammad. arXiv preprint arXiv:1911.03562. November 2019.
See full list of associated papers in the About Page.
Title Terms
The title has a privileged position in a paper. It serves many functions, and here are three key ones (from an article by Sneha Kulkarni):
“A good research paper title:
1. Condenses the paper’s content in a few words
2. Captures the readers’ attention
3. Differentiates the paper from other papers of the same subject area”
If we examine the titles of papers in the ACL Anthology, we would expect that because of Function 1 many of the most common terms will be associated with the dominant areas of research. Function 2 (or attempting to have a catchy title) on the other hand, arguably leads to more unique and less frequent title terms. Function 3 seems crucial to the effectiveness of a title; and while at first glance it may seem like this will lead to unique title terms, often one needs to establish a connection with something familiar in order to convey how the work being presented is new or different.
It is also worth noting that a catchy term today, will likely not be catchy tomorrow. Similarly, a distinctive term today, may not be distinctive tomorrow. For example, early papers used neural in the title to distinguish themselves from non-nerual approaches, but these days neural is not particularly discriminative as far as NLP papers go.
Thus, competing and complex interactions are involved in the making of titles. Nonetheless, an arguable hypothesis is that:
broad trends in interest towards an area of research will be reflected, to some degree, in the frequencies of title terms associated with that area over time.
However, even if one does not believe in that hypothesis, it is worth examining the terms in the titles of tens of thousands of papers in the ACL Anthology — spread across many decades.
Q1. What terms are used most commonly in the titles of the AA papers? How has that changed with time?
A. Below are the most common unigrams (single word) and bigrams (two-word sequences) in the titles of papers published from 1980 to 2019. (Ignoring function words.) The timeline graph at the bottom shows the percentage of occurrences of the unigrams over the years (the colors of the unigrams in the Timeline match those in the Title Unigram list).
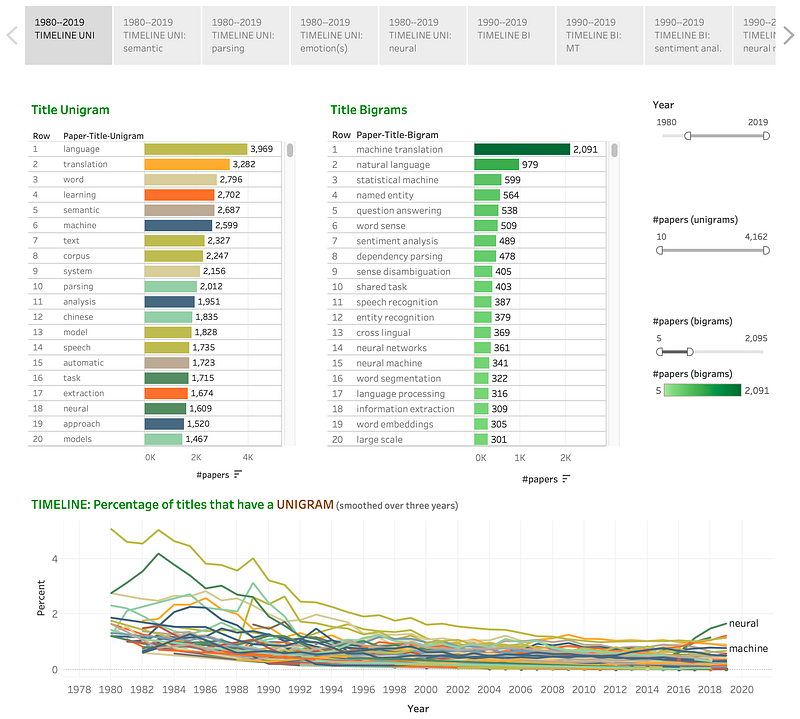

Discussion: Appropriately enough, the most common term in the titles of NLP papers is language. Presence of high-ranking terms pertaining to machine translation suggest that it is the area of research that has received considerable attention.
Other areas associated with the high-frequency title terms include lexical semantics, named entity recognition, question answering, word sense disambiguation, and sentiment analysis. In fact, the common bigrams in the titles often correspond to names of NLP research areas. Some of the bigrams like shared task and large scale are not areas of research, but rather mechanisms or trends of research that apply broadly to many areas of research. The unigrams, also provide additional insights, such as the interest of the community in Chinese language, and in areas such as speech and parsing.
The Timeline graph is crowded in this view, but clicking on a term from the unigram list will filter out all other lines from the timeline. This is especially useful for determining whether the popularity of a term is growing or declining. (One can already see from above that neural has broken away from the pack in recent years.) Since there are many lines in the Timeline graph, Tableau labels only some (you can see neural and machine). However, hovering over a line, in the eventual interactive visualization, will display the corresponding term — as shown in see screenshot below:
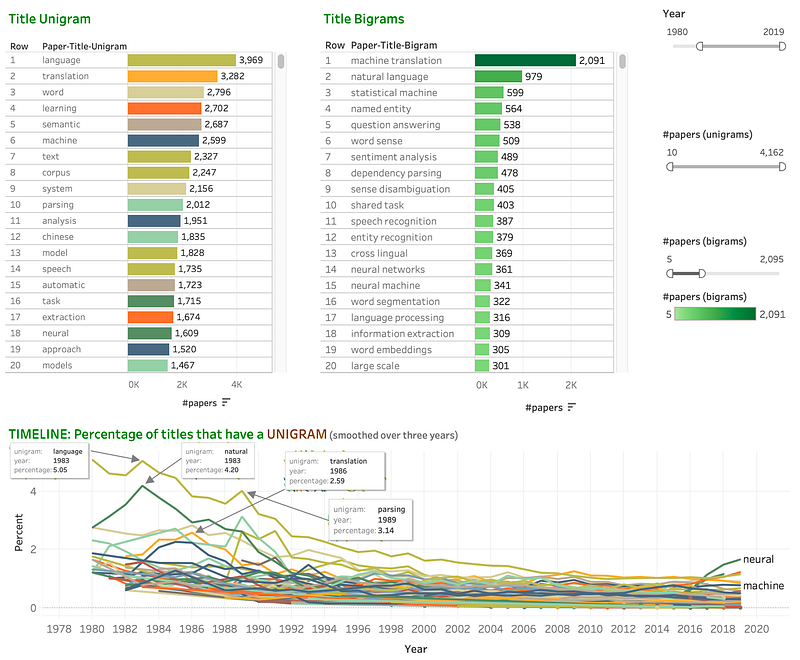
Despite being busy, the graph sheds light on the relative dominance of the most frequent terms and how that has changed with time. The vocabulary of title words is smaller when considering papers from the 1980’s than in recent years. (As would be expected since the number of papers then was also relatively fewer.) Further, dominant terms such as language and translation accounted for a higher percentage than in recent years where there is a much larger diversity of topics and the dominant research areas are not as dominant as they once were.
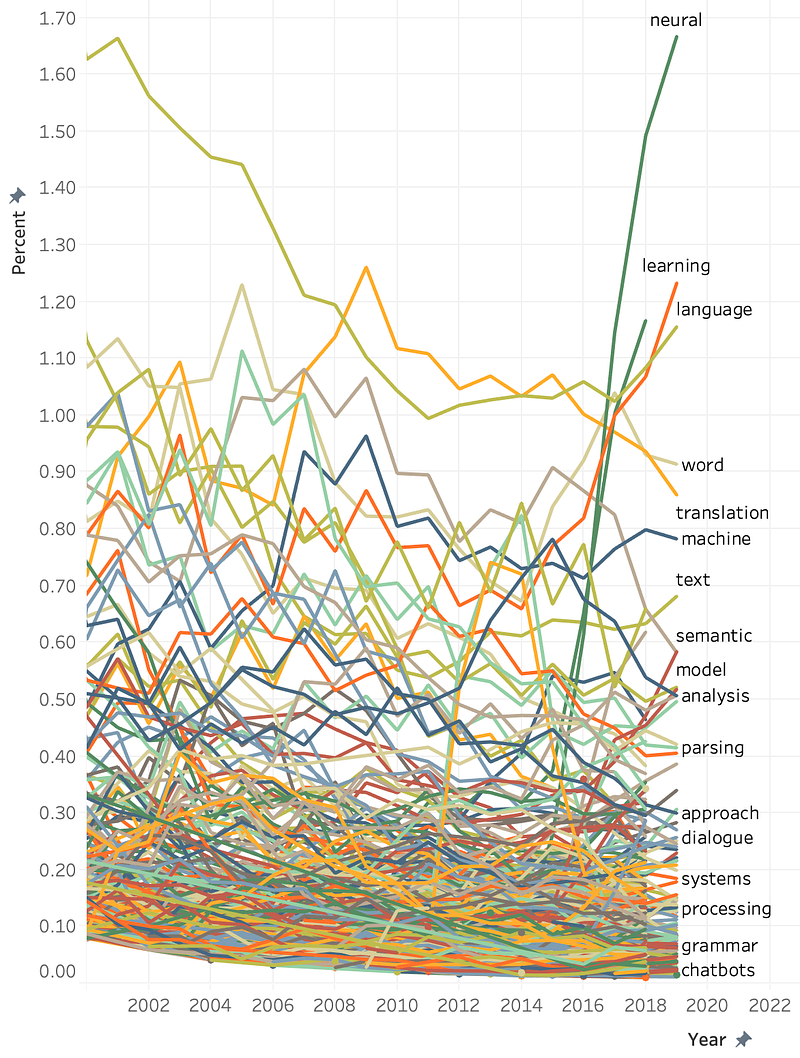
A blow-up of the timeline (2000–2019 portion):
Q2. What are the most frequent unigrams and bigrams in the titles of recent papers?
A. Below are the most frequent unigrams and bigrams in the titles of papers published 2016 Jan to 2019 June (time of data collection):
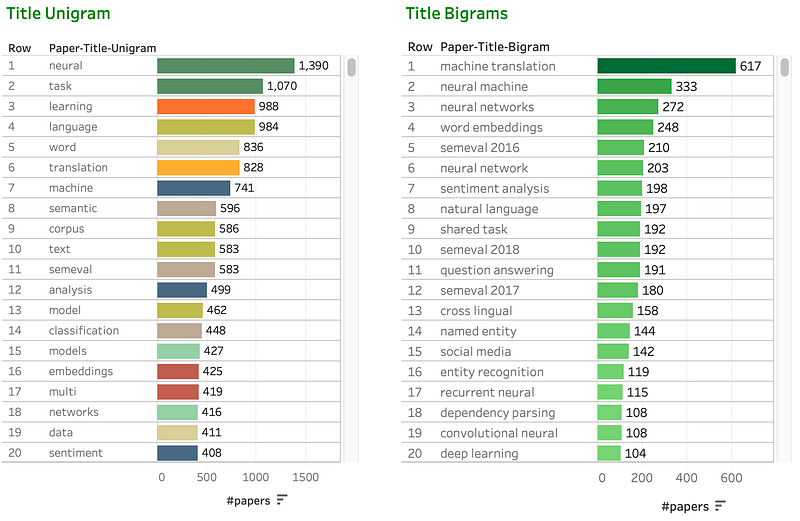
Discussion: Some of the terms that have made notable gains in the top 20 unigrams and bigrams lists in recent years include: neural machine (presumably largely due to the phrase neural machine translation), neural network(s), word embeddings, recurrent neural, deep learning and the corresponding unigrams (neural, networks, etc.). We also see gains for terms related to shared tasks such as SemEval and task.
See the keynote slides embedded below for lists from various time spans. (Click on the navigation button on the center right of the image to change time span, or better yet, first click on the icon at the bottom right of the image to go full screen. Use right and left arrow keys to navigate.)
What do you see in the lists? If you have any insights or thoughts, feel free to share ([email protected]).
Q3. Show me some click and filter interactions with the visualization?
A. Below are some examples:
Clicking on neural:
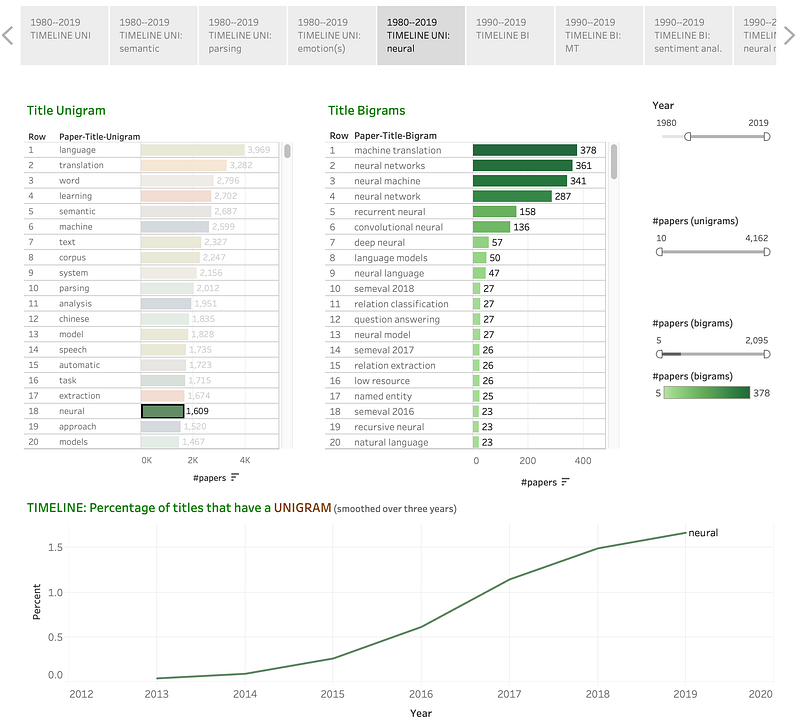
Discussion: Not only are papers with neural in the title very popular now, they are also a recent phenomenon. In fact very few papers before 2013 had neural in the title. Note that the percentage of papers that use neural models (in one form or other) is much higher. Terms that refer to a methodology or approach are likely have different temporal behaviors than words that refer to areas of research. For example, use of neural approaches are so common that often neural is not mentioned in the title, however, if one is writing a paper on emotion or word senses, then arguably emotion and word senses are more likely to appear in the title despite the lack of newness of those terms.
Clicking on semantic:
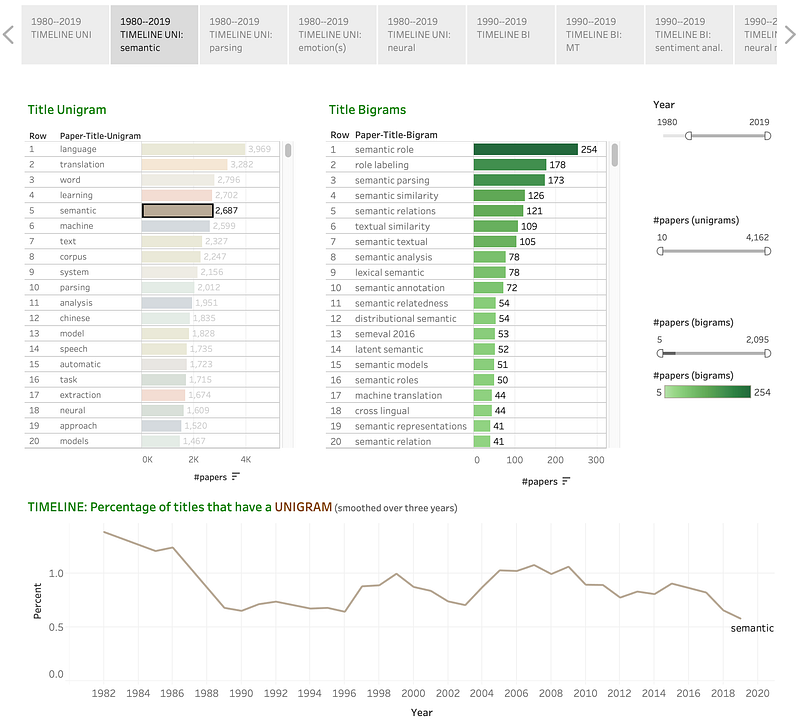
Apart from clicking on terms, one can also enter the query (say parsing) in the search box at the bottom. Apart from filtering the timeline graph (bottom), this action also filters the unigram list (top left) to provide information only about the search term. This is useful because the query term may not be one of the visible top unigrams.
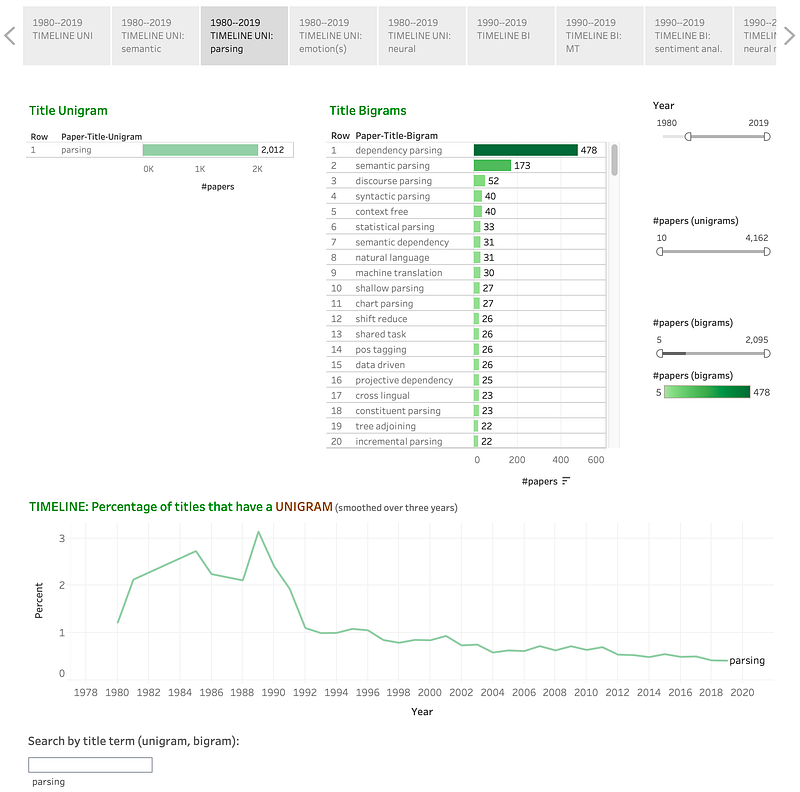
Discussion: Parsing seems to have enjoyed considerable attention in the 1980s, began a period of steep decline in the early 1990s, and a period of gradual decline ever since. (Note that these numbers are percentages, the visualizations in subsequent posts will provide information on raw number of papers by title term.)
One can enter multiple terms in the search box or shift/command click multiple terms to show graphs for more than one term:
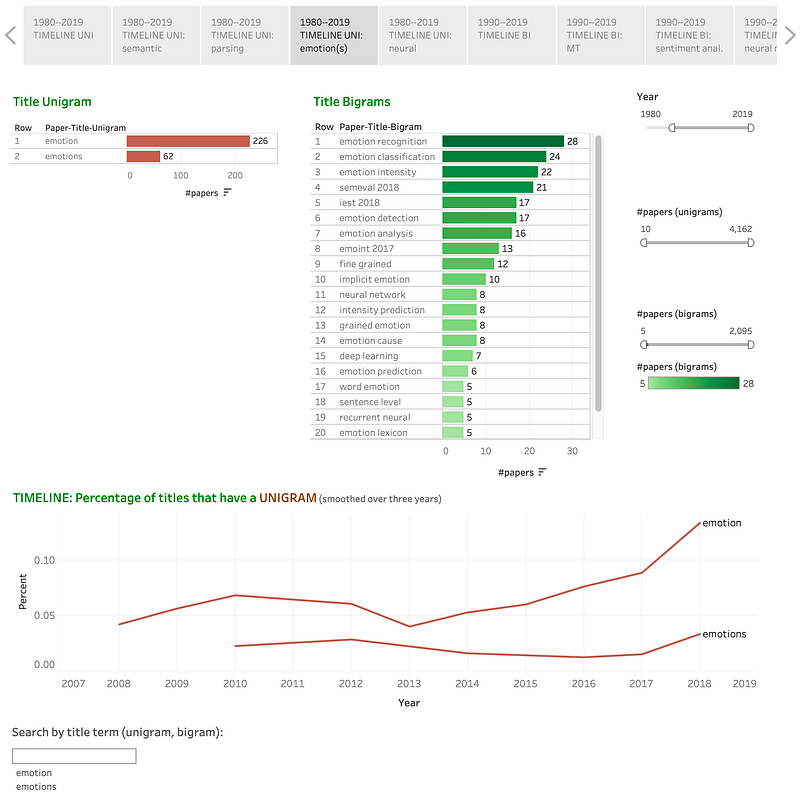
Note that while it might be useful to group inflectional variants in some instances, in other instances, one might be interested in learning about each term separately — for example, if one is interested specifically in work that deals with multiple emotions. (The visualizations here show information about multiple search terms separately, but other visualizations, especially in part III, allow one to search for papers that include any of the multiple search terms the user provides, as one list or graph.)
The visualizations below show the timelines for bigrams (instead of unigrams).
Statistical Machine vs Neural Machine:
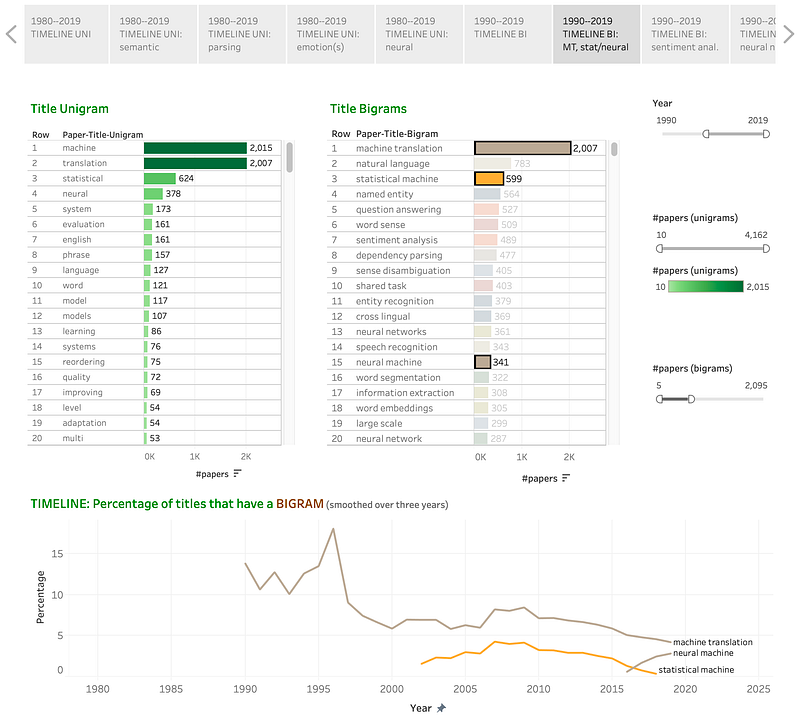
Discussion: The graph indicates that there was a spike in machine translation papers in 1996, but the number of papers dropped substantially after that. Yet, its numbers have been comparatively much higher than other terms. One can also see the rise of statistical machine translation in the early 2000s followed by its decline with the rise of neural machine translation.
word sense:
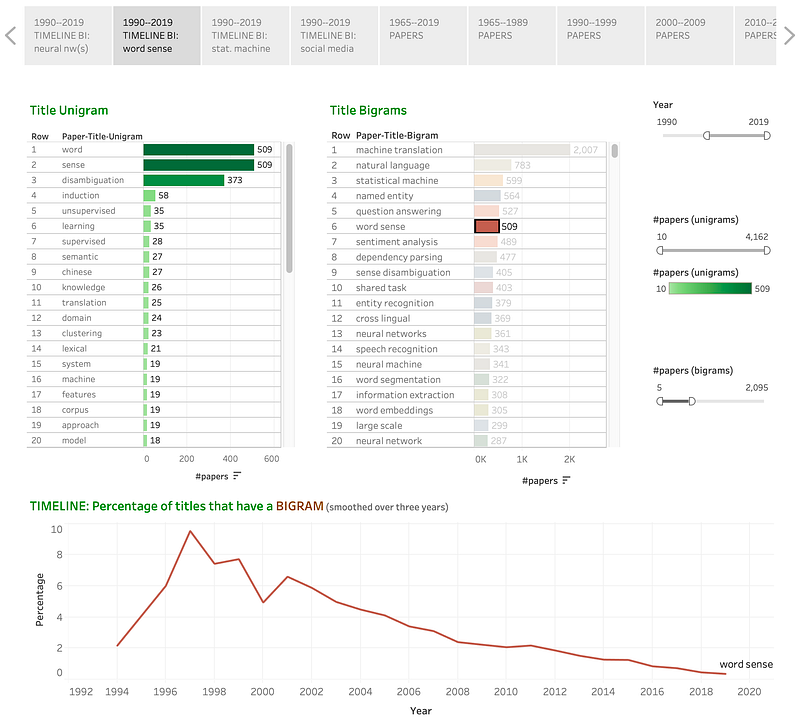
Discussion: Papers on word senses (which includes those on word sense disambiguation) enjoyed a steep increase from 1994 to 1997, but have steadily declined ever since.
sentiment analysis:
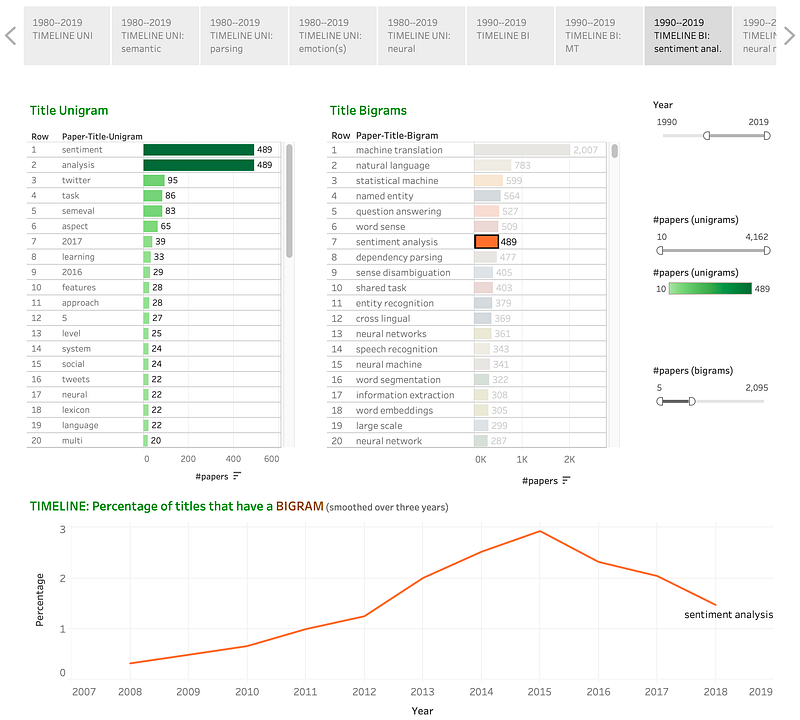
Discussion: Sentiment analysis has enjoyed strong growth in its short history, especially since 2013 with a number of popular shared tasks. The popularity peaked in 2015 followed by a period where the number of papers has declined somewhat.
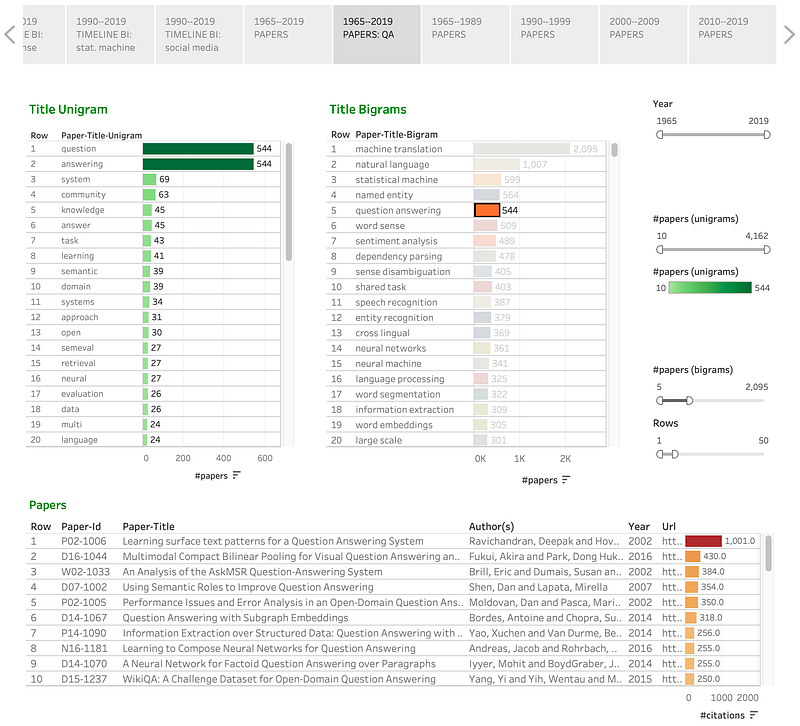
Q4. What are the most cited papers among the ones that have a particular unigram or bigram in the title?
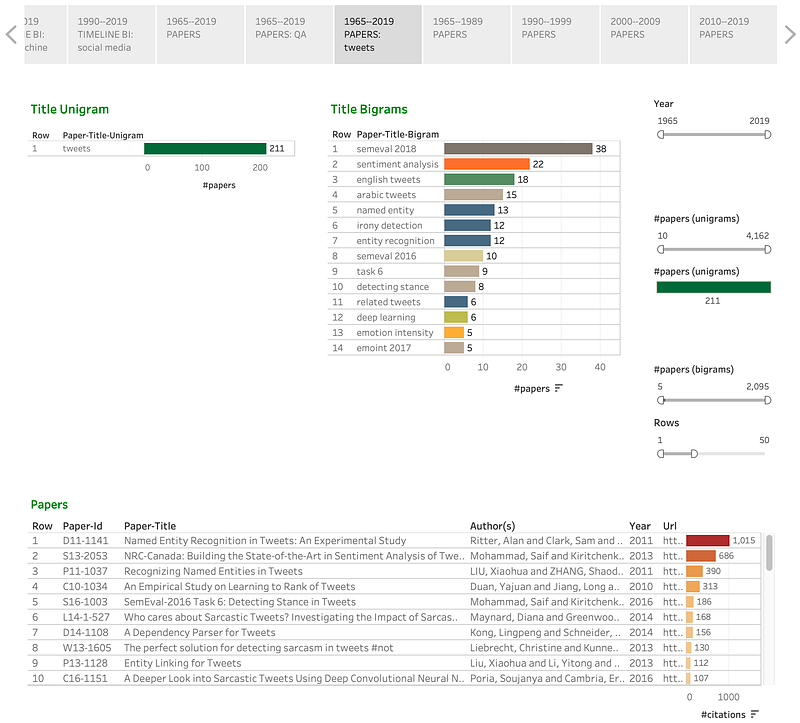
The PAPERS tabs can be used to see the list of papers that have that a query term in the title. The papers are listed in decreasing order of citations. For example, if one clicks on question answering, we get:
For tweets:
Once the interactive visualizations are released, one can freely explore terms of interest.
Future work:
- Present similar analyses based on terms in abstracts and terms in the whole paper.
- Analyze terms in different sections of papers such as in the introduction, related work, future work, conclusions, etc.
- Learn word embeddings using the AA as a corpus. Represent papers through embeddings of words in the title, abstract, and the whole paper.
- Identify terms that are similar to query terms based on the word embeddings. Identify other papers that are related to a query paper.
- Identify topics or areas of research through document representations. Track topics through time. Determine how similar the conclusions are when using embedding-based topic representations to the analyses presented above which simply uses title terms.
- Showcase unique work that perhaps has not received as much attention yet.
- Identify potentially influential ideas that are about to become new trends.
Next post:
Other posts in the series:
- Part I: Size and Demographics
- Part II: Areas of Research (Examining Title Terms)
- Part IIIb: Impact (Examining Citations by Area of Research, Academic Age, & Gender)
- NLP Scholar: An Interactive Visual Explorer for the ACL Anthology
- About the NLP Scholar Project: Acknowledgments, caveats, limitations, ethical considerations, and related work
Paper: The State of NLP Literature: A Diachronic Analysis of the ACL Anthology. 2019.
Contact Saif M. Mohammad Twitter: @saifmmohammad Email: [email protected], [email protected] Webpage: http://saifmohammad.com
Project Homepage: http://saifmohammad.com/WebPages/nlpscholar.html