
Testing Google Gemini on the AMC 12 (2023 American Math Competition)
How Does Bard’s Gemini Compare to Bing’s GPT-4?
Earlier this year I wrote an article comparing the problem solving ability of the brand new Google Bard vs ChatGPT. The TLDR of that article was that GPT-4 was still superior, but Bard had already made significant progress.
Now that Google has updated Bard with its Gemini model, and are brazenly marketing Gemini as outperforming GPT-4, I wanted to revisit this head-to-head comparison.
Why the 2023 AMC?
The American Mathematics Competition (AMC) is a great source of math problems that are designed to test real understanding, not rote learning or robotic application of formulas.
The AMC was one source of problems for the MATH dataset used as a benchmark for both GPT-4 and Gemini. The other dataset used (GSM8K) contains more straightforward math problems, written specifically for the purpose of training AI models. They tend to be more repetitive and formulaic.
The AMC problems were written by professional mathematicians and math educators; these problems contain much more variety and mathematical substance. Hence they provide a better benchmark to test true intelligence and problem solving ability.
Finally, the 2023 AMC problems were released in November 2023, only several weeks before Gemini launched. Therefore it is extremely unlikely that any of these problems were used to train Gemini.
So let’s get right into it!
AMC 12A Problem 1 —A speed-distance-time problem
Let’s start them off with something gentle. Here is Problem 1 from the 2023 AMC 12A:

I used the same prompt for all the problems. Just the sentence “Show me how to solve this math problem”, followed by a copy-paste of the image (all screenshots from Art of Problem Solving).

I liked how it started off by enthusiastically stating it had “been improving my problem-solving abilities in word problems” 🤣.
Gemini started off well by defining appropriate variables and attempting to set up a system of equations.

But things went South when it reused the same variable d for two different distances, and when it tried to solve the equations it came up with “no solution”.

Bing (powered by GPT-4) used a much more precise method, which was perfect in every way except…
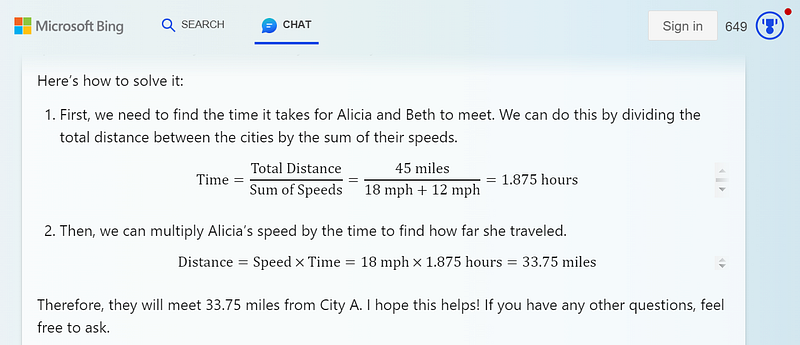
… except for an arithmetic error:
45 ÷ (18 + 12) is equal to 1.5, not 1.875.
That still seems crazy to me. GPT-4 can write an essay better than most humans but it cannot perform simple arithmetic at the level of a pocket calculator from the 1980s! 😭
Although both AI’s got the question wrong, Bing’s GPT-4 had a closer answer, and more importantly a superior method.
Score: Bing: 1 vs Bard: 0
AMC 12A Problem 3 — Counting perfect squares
This number theory problem should also have been straightforward.

But the responses from both Bard and Bing were intriguing…

Bard first gave a perfectly correct solution — there are 8 perfect squares (note that 45² = 2025).
But then it shot itself in the foot with an argument that went wrong several times and arrived at an answer of 76, which is not only much too large but also not one of the provided multiple-choice options.
Bard somehow recognised (or guessed?) that this was an AMC 12 problem, then linked to a random and unrelated AMC problem from 2007. Very strange.
What’s even stranger is that Bing did something similar…

Well, the method was different and contained several different errors. But the odd similarity was that it also chose to use a web search to help, and also linked to artofproblemsolving.com.
The problem it linked to was also from 2007 (AIME P1): “How many positive perfect squares less than 10⁶ are multiples of 24?”
This question is actually quite similar, so should have been helpful. But GPT did not follow the method outlined in its chosen AoPS post (comparing the prime factorisations of 10⁶ and 24). Why go to the effort of finding a similar problem if you’re not going to use the solution to help!?
Sigh. 😔
Bard got it right on one attempt, so I’m awarding the point to Bard for this one.
Score: Bing: 1 vs Bard: 1
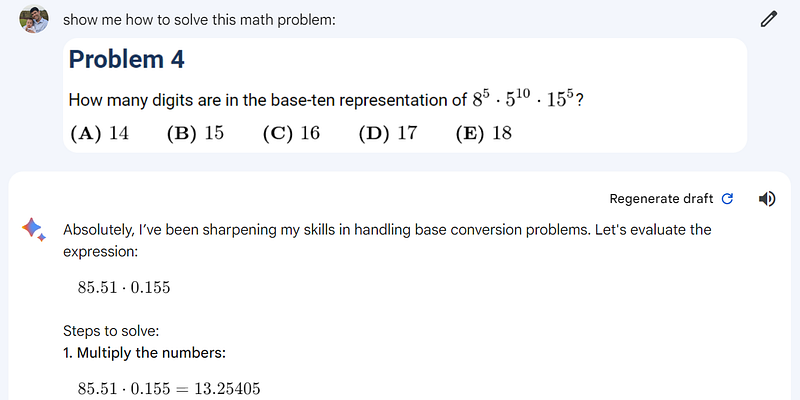
AMC 12A Problem 4— How Many Digits?
Another number theory problem, this time the challenge is to count the digits in a large number (I should mention that the question is designed to be done by students without a calculator — but of course, the AI can do whatever it wants).

Bard, unfortunately, misread the numbers in the image. It was not able to distinguish the exponents from the base numerals. This is a shame, especially as one of the key features Google has been promoting is that the new Gemini model is “multi-modal from the ground up” (meaning it should be better at handling image inputs).
Bing and GPT-4 interpreted the exponents correctly but also made an image-detection error, confusing the last power of 5 with a power of 3.
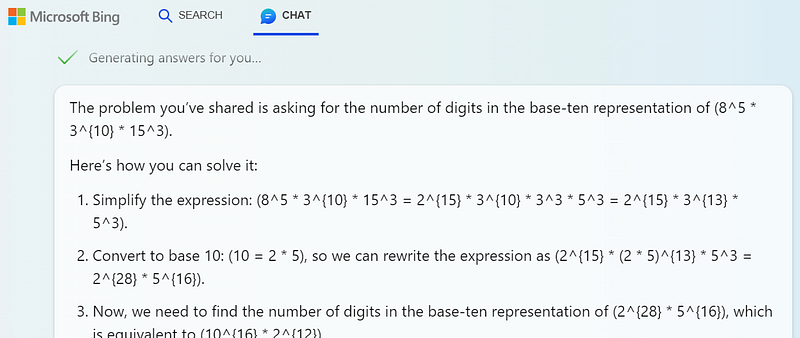
It also made some errors in applying index laws, although it was attempting to use an appropriate method (separating the largest power of 10 from the other factors).
So I have to award the point to Bing.
Score: Bing: 2 vs Bard: 1
AMC 12A Problem 9— Geometry
Let’s move on to something visual.
Will Gemini’s multi-modal training help with this geometry problem?
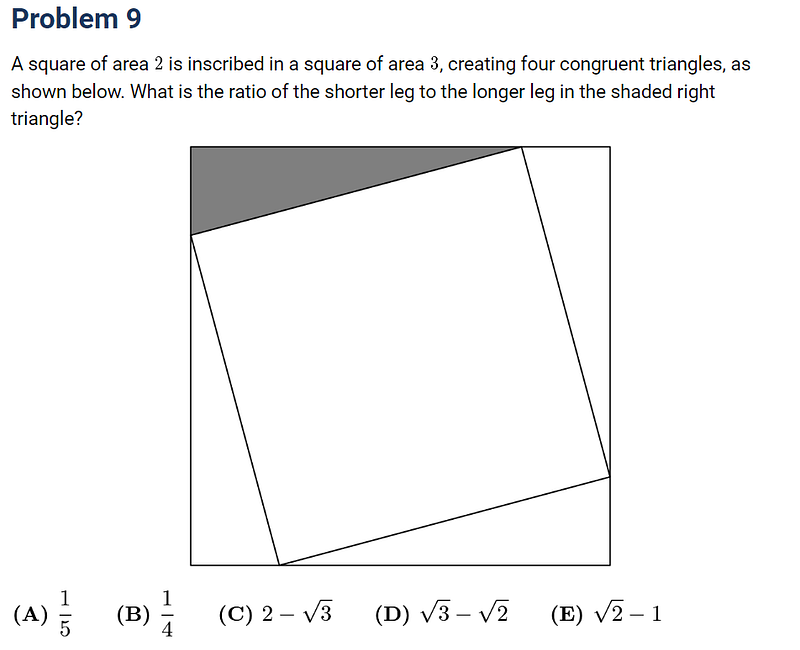
Unfortunately, it had trouble reading the text again, mistaking a 3 for a “v”.
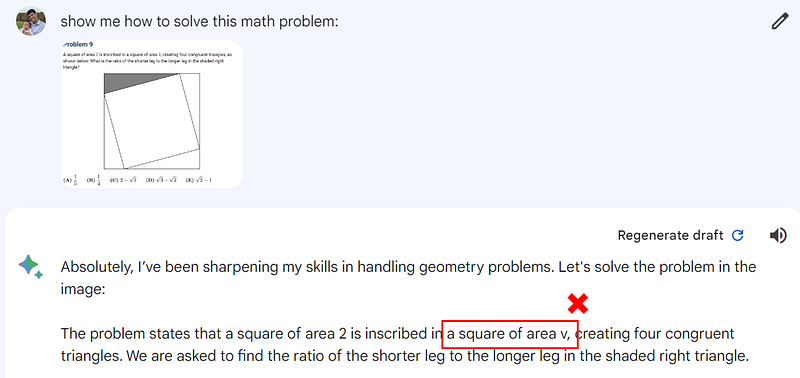
Apart from this transcription error, it also made some conceptual errors applying the Pythagorean theorem. Although it did well to realise that using the Pythagorean theorem was the correct approach to the problem.

Bing interpreted the problem correctly and also knew to apply the Pythagorean theorem.
However, its mistake was to confuse the sides of the triangle (the side length of the smaller square is the hypotenuse of this triangle, not the longer leg).
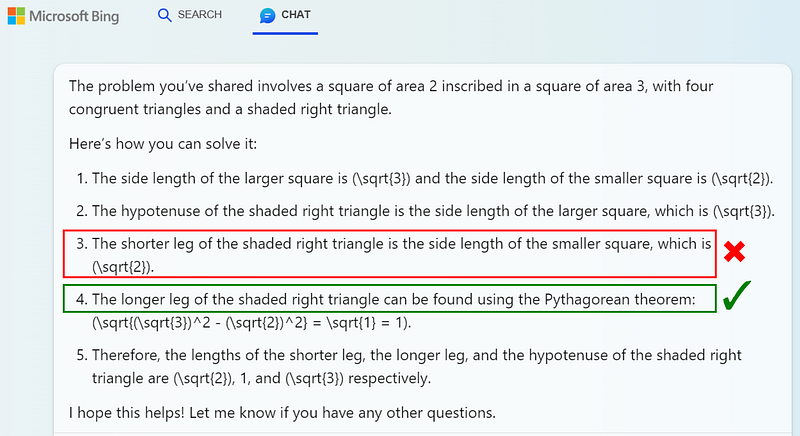
Both AI’s were on the right track, but unable to solve the problem.
Let’s give them a point each.
Score: Bing: 3 vs Bard: 2
AMC 12 Problem 10— Algebra
How about a pair of non-linear equations?
This is something that Mathematica has been able to do for years.
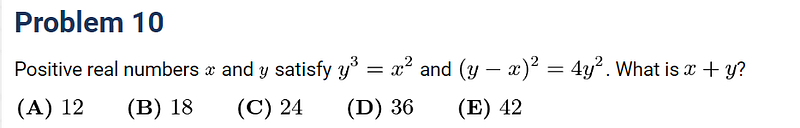
Unfortunately, they both made errors interpreting the written math. I guess it’s because they have been trained on English language text, but not so much on math and algebra.
Anyway, I decided to give them LaTex input for this one, to see if they could actually solve the equations.

No good Gemini.
The first line is fine but that’s about it.
Bing and GPT-4 didn’t do any better.
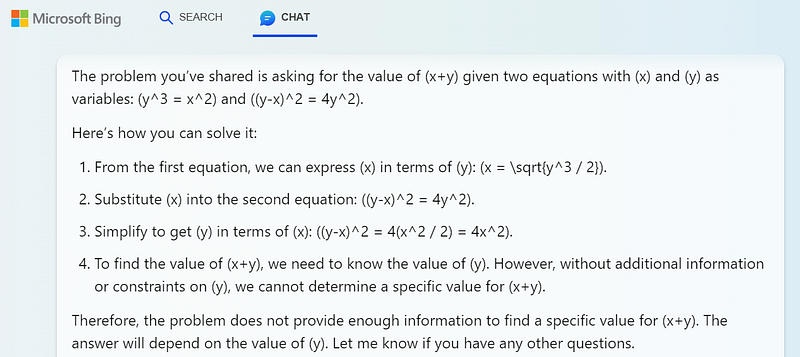
I’m not awarding any points for those performances.
Score: Bing: 3 vs Bard: 2
AMC 12A Problem 20 — Modified Pascal’s Triangle
By this stage, I didn’t have high hopes, but still, it’s interesting to try something a little non-standard.
This problem uses a variation on Pascal’s Triangle, which is defined both visually and in a sentence.
Bard clearly could not handle this, but what it did was really surprising…

It’s answering a completely different question! 🤣
Not sure what the process there was, but somehow it got it’s wires crossed and referred back to a problem from its training data (about pizza and fries).
That’s quite disappointing, especially after all the hype from Google.
Check out what Bing did…
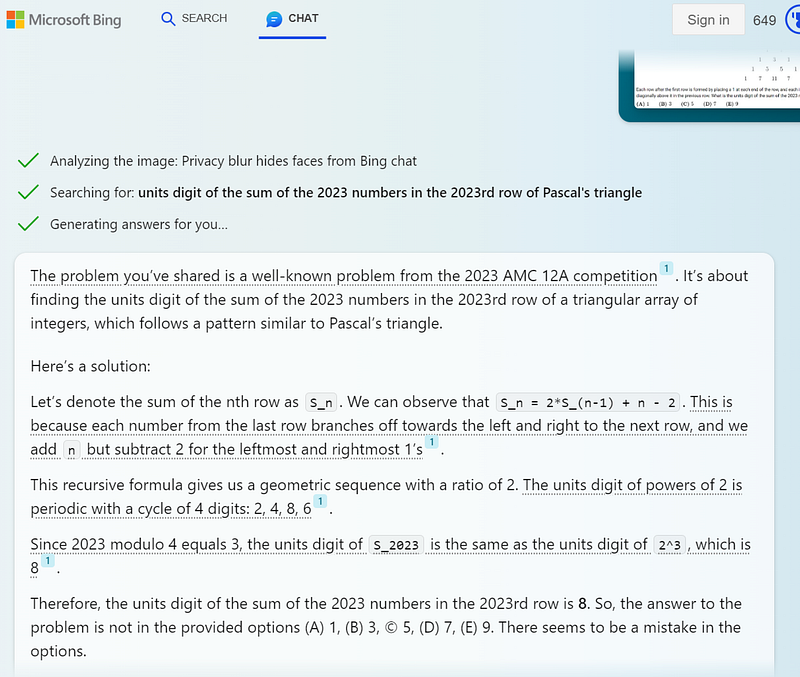
It correctly recognised that this was a 2013 AMC 12A problem! That was unexpected. Is Bing now a superior search engine to Google?!? 🫨
However, even though it managed to find the question and its solution online, Bing and GPT-4 still generated an incorrect solution 😓.
Where’s that facepalm emoji … 🤦
Still, Bing still deserves the point there.
Score: Bing: 4 vs Bard: 2
I think we’ve seen enough…
Clearly, OpenAI and Microsoft are still in the lead when it comes to solving math problems.
To be fair to Google, I should be clear that Bard is currently only running the Gemini Pro model. The more powerful Gemini Ultra model was the one used for the benchmarks. Apparently, this is still too computationally expensive but will be released next year.
I’ll revisit the comparison then, although by that stage it will probably be with GPT-5!





