Scraping Reddit Data Using Python and PRAW : A Beginner’s Guide

In this article, we will learn how to scrape Reddit data using Python and Python Reddit API Wrapper (PRAW). We will focus on scraping data from a specific subreddit, but the principles can be applied to any subreddit.
For those who can’t view the entire guide, simply Click here!
Introduction to PRAW
Before introducing PRAW, let’s briefly discuss what an API is. An API, or Application Programming Interface, allows different software applications to communicate with each other and exchange data. PRAW, short for Python Reddit API Wrapper, is a powerful Python package that provides convenient access to Reddit’s API. With PRAW, developers can easily interact with Reddit, retrieve data and perform various actions. PRAW aims to be as easy to use as possible and is designed to follow all of Reddit’s API rules.
Before diving into scraping, ensure you have Python installed on your system. You can download and install Python from the official website (python.org/downloads). Once Python is installed, use pip, Python’s package installer, to install PRAW by running this command in your terminal or command prompt:
pip install praw
Setting up Reddit API
Now, let’s delve into setting up the Reddit API. To access Reddit’s data, you need to create an application through Reddit. This process will provide you with essential credentials: client_id, client_secret and user_agent. These credentials are necessary for authenticating your requests to Reddit’s API.
Here’s how you do it:
- Create a Reddit account or log in to your existing Reddit account.
- Navigate to https://www.reddit.com/prefs/apps.
- Scroll down to the ‘Developed Applications’ section and click on the ‘Create App’ or ‘Create Another App’ button.
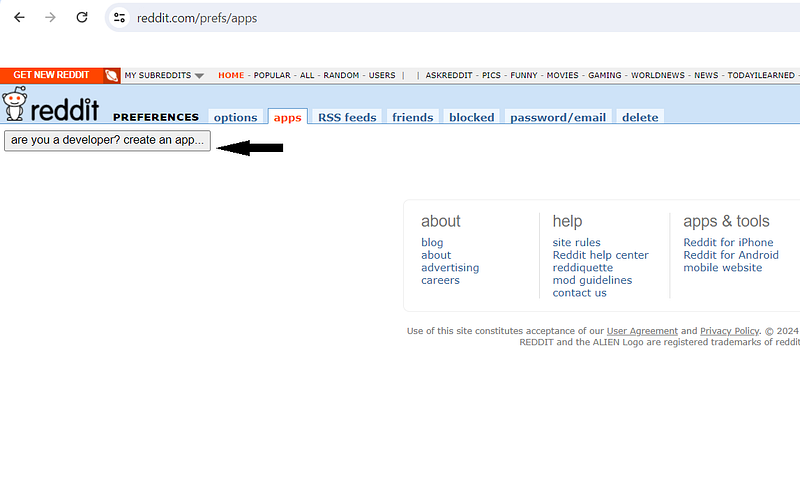
4. Fill out the form that appears with the following:
name: The name of your application.App type: Choose the ‘script’ option.description: Write a brief description of your application (this can be left blank).about url: This can be left blank.redirect uri: This should be “http://localhost:8080” (without quotes).
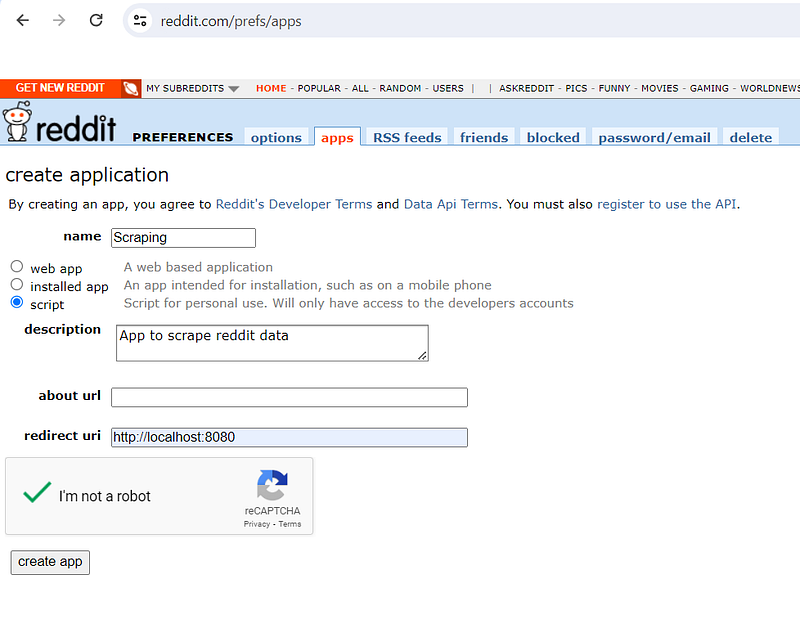
5. Click on the ‘Create app’ button at the bottom when you’re done.
After successfully creating your app, you’ll now have access to your client_id, client_secret and user_agent.
Scraping Subreddit Data
Now that we have our Reddit API credentials set up, let’s dive into scraping data from Reddit. But first, let’s understand what a subreddit is. A subreddit is essentially a community within Reddit dedicated to a specific topic, interest or theme. Subreddits are denoted by their name preceded by “r/”. For example, if the subreddit is about technology, it might be called “r/technology”. Similarly, if you’re interested in photography, you might visit “r/photography”.
In your Python script, import the PRAW library and initialize a Reddit instance with your API credentials i.e. client ID, client secret and user agent. This is done using the praw.Reddit() constructor.
import praw
# Initialize Reddit instance
reddit = praw.Reddit(client_id="your_client_id",
client_secret="your_client_secret",
user_agent="your_user_agent")Choose the subreddit you want to scrape data from. Let’s scrape data from ‘r/fitness’ subreddit and extract information about this subreddit.
# Subreddit to scrape
subreddit = reddit.subreddit('fitness')
# Display the name of the Subreddit
print("Display Name:", subreddit.display_name)
# Display the title of the Subreddit
print("Title:", subreddit.title)
# Display the description of the Subreddit
print("Description:", subreddit.description)Output:

Now, when scraping Reddit data, you can specify the sorting criteria to retrieve posts based on your preferences. The most common sorting criteria include: “hot”, “new”, “top”, “controversial”. For example, if you’re interested in analyzing recent discussions, you might choose to scrape posts sorted by “new.” Conversely, if you want to identify the most popular or highly-rated posts, you might opt for “top” or “hot” sorting criteria. We will use “top” criteria in this example.
Scraping Posts and Comments
Using PRAW, you can easily fetch posts and comments from the selected subreddit. Iterate through the posts using a loop and collect relevant information. For each post, we check if it has comments, and if so, scrape the comments as well. Here, in our code we are limiting ourselves to scrape “top” 10 posts. You can change this as required.
Here’s the code snippet for our task:
# Importing necessary libraries
import praw
import pandas as pd
# Initialize Reddit instance
reddit = praw.Reddit(client_id="your_client_id",
client_secret="your_client_secret",
user_agent="your_user_agent")
# Subreddit to scrape
subreddit = reddit.subreddit('fitness')
# Define lists to store data
data = []
# Scraping posts & Comments
for post in subreddit.top(limit= 10):
data.append({
'Type': 'Post',
'Post_id': post.id,
'Title': post.title,
'Author': post.author.name if post.author else 'Unknown',
'Timestamp': post.created_utc,
'Text': post.selftext,
'Score': post.score,
'Total_comments': post.num_comments,
'Post_URL': post.url
})
# Check if the post has comments
if post.num_comments > 0:
# Scraping comments for each post
post.comments.replace_more(limit= 5)
for comment in post.comments.list():
data.append({
'Type': 'Comment',
'Post_id': post.id,
'Title': post.title,
'Author': comment.author.name if comment.author else 'Unknown',
'Timestamp': pd.to_datetime(comment.created_utc, unit='s'),
'Text': comment.body,
'Score': comment.score,
'Total_comments': 0, #Comments don't have this attribute
'Post_URL': None #Comments don't have this attribute
})
# Create pandas DataFrame for posts and comments
fitness_data = pd.DataFrame(data)Now, let’s take a closer look at the code!
In the code above, we first import the necessary libraries, praw and pandas. Then we create a Reddit instance using our client_id, client_secret and user_agent.
Next, we specify the subreddit we want to scrape.
We then define a list, data, to store the data we’ll be scraping.
We loop through each post in the subreddit’s “top” section. For each post, we append a dictionary to our data list. This dictionary contains the post’s type, id, title, author, timestamp, text, score, total number of comments and URL.
Next, if a post has comments, we loop through each comment and append a similar dictionary to our data list. This time, the dictionary contains the comment’s type, the id of the post it belongs to, the title of the post, the comment’s author, timestamp, text and score.
After scraping the data, we convert our data list into a pandas DataFrame for easier manipulation and analysis.
Here’s a sample of the data we’ve extracted from Reddit:
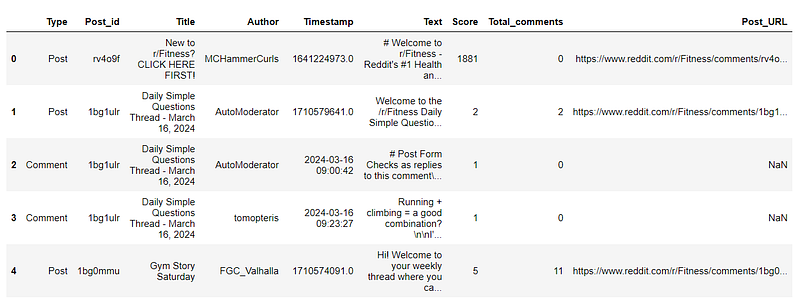
After organizing the data, you can save it for further analysis or sharing. Use Pandas’ to_json()or to_csv()method to export the DataFrame to a JSON/CSV file.
# Save DataFrame
fitness_data.to_json('fitness_data.json', orient='records', lines=True)
OR
fitness_data.to_csv('fitness_data.csv')Things to Keep in Mind
While scraping data from Reddit can be incredibly insightful, there are some important considerations to keep in mind.
1) Rate Limiting: Reddit imposes rate limits on how many requests you can make in a certain amount of time. If you make too many requests too quickly, you may get a “429 Too Many Request” error, which temporarily blocks further requests from your application. To avoid this, implement strategies like adding delays between requests to avoid hitting the rate limit. You can achieve this by using Python’s time.sleep() function to pause the execution of your code for a specified duration. Adjust the delay time as needed to balance scraping speed and rate limit adherence.
Here’s a simple example demonstrating how to add delays between requests using Python’s time.sleep() function:
# Import necessary libraries
import praw
import time
# Initialize Reddit instance
reddit = praw.Reddit(client_id="your_client_id",
client_secret="your_client_secret",
user_agent="your_user_agent")
# Subreddit to scrape
subreddit = reddit.subreddit('fitness')
# Define lists to store data
data = []
# Scraping posts & Comments
for post in subreddit.top(limit=10):
# Add your scraping code here
# Delay between requests to avoid rate limiting
time.sleep(2) # Pause for 2 second between requests2) Respect Reddit’s Guidelines: Ensure your scraping activities comply with Reddit’s terms of service and community guidelines. Avoid excessive scraping or actions that may disrupt the platform.
3) Privacy: Be respectful of users’ privacy when scraping and using Reddit data. Avoid collecting sensitive information and always comply with Reddit’s terms of service.
Conclusion
In conclusion, this beginner’s guide has equipped you with the knowledge and tools to start scraping Reddit data using Python and PRAW. We’ve covered essential concepts such as setting up the Reddit API, scraping subreddit data and handling potential challenges like rate limiting. By adhering to ethical scraping practices and respecting Reddit’s guidelines, you can contribute positively to the Reddit community while extracting valuable insights.
Remember, with great power comes great responsibility. Use this power wisely and ethically.
Happy scraping!