
Run LLM Inference Using Apple Hardware
Unlock Apple GPU power for LLM inference with MLX

Finally!
We are in a position to run inference and fine-tune our own LLMs using Apple’s native hardware. This article will cover the setup for creating your own experiments and running inference. In the future I will be making an article on how to fine-tune these LLMs (again using Apple hardware).
If you haven’t checked out my previous articles, I suggest doing so as I make a case for why you should consider hosting (and fine-tuning) your own open-source LLM. I also cover strategies as to how you can optimise the process to reduce inference and training times. I will brush over topics such as quantisation as these are covered in depth in the aforementioned articles.
I will be using the mlx framework in combination with Meta’s Llama2 model. In-depth information on how to access the models can be found in my previous article. However, I’ll briefly explain how to do so in this article as well.
Let’s get started.
Pre-requisites:
- A machine with an M-series chip (M1/M2/M3)
- OS >= 13.0
- Python between 3.8–3.11
For my personal hardware set-up, I am using a MacBook Pro with an M1 Max chip — 64GB RAM // 10-Core CPU // 32-Core GPU.
My OS is Sonoma 14.3 // Python is 3.11.6
As long as you meet the 3 requirements listed above, you should be able to follow along. If you have around 16GB RAM, I suggest sticking with the 7B models. Inference times etc. will of course vary depending on your hardware specs.
Setup:
Feel free to follow along and set-up a directory where you will store all files relating to this article. It will make the process a lot easier if they’re all in one place. I’m calling mine mlx.
First we need to ensure you are running a native arm version of Python. Otherwise we will be unable to install mlx. You can do so by running the following command in your terminal:
python -c "import platform; print(platform.processor())"The output of the above command should be arm:

If it is, skip to the install requirements section. If not, read below:
Mine was initially returning i386. This essentially means you are using a non-native Python version created for Intel x86 architecture which was used in older macs. Depending on what you tools you use to handle your Python environments, you will want to set-up a new environment with a native arm version of Python. I’m using pyenv to handle my Python environments so I simply type the command:
pyenv virtualenv 3.11.6 mlx-env
This creates a new python environment named mlx-env with my chosen version of Python. Then activate this environment using:
pyenv activate mlx-env
If you use anaconda/miniconda for managing your environments, here are instructions as to how you can update it.
Install requirements:
Below is a list of all packages you will require to run inference on the Llama-2 model:
mlx sentencepiece torch numpy
Add these to a requirements.txt file within your mlx directory and run:
pip install -r requirements.txt
Model Download:
Next, we need to download the required Llama-2 model. Here you can choose whichever you wish to use. Again, make a decision based upon your hardware specifications. The larger the model, the more resources you will require. I have been working with the 13B parameter version. We will quantise the model regardless to decrease inference times. I’ll quickly go over the download process. If anything is unclear, please see my previous article:
- Request access
- Download the download.sh script and move it to your mlx directory
- Access email sent to you by Meta and copy link in point 2 of the “How to Download Models” section
- Run the download.sh script by entering sh ./download.sh from your terminal
- Paste the link you copied from step 3 into the terminal prompt. It should look something like this:

6. The prompt will ask you which models you wish to download. Select which you want to download. For example, if you want to download the 7B and 13B models, simply type: 7B,13B
7. Your models with the download into your mlx folder.
MLX:
Now we move to the cool bit. MLX provide great documentation as to how you can get up and running with different models. As stated, I will concentrate just on running inference. Fine-tuning will come in a later article.
Download the convert.py and llama.py files provided by MLX into your mlx folder. At this stage, I highly recommend you to check through both files so you can get an insight into what is happening under the hood. I’ll include them below with a brief summary.
I wish to state here that full attribution for the code goes to the MLX researchers.
convert.py — this script converts the original Pytorch-based Llama-2 model into MxNet format. MxNet tensors share many similarities to those found in their Pytorch and Tensorflow counterparts with some slight nuances. Check out this article if you’re interested in reading more about MxNet. The script also handles the input of command line arguments where we have the option of adding quantisation:
import argparse
import collections
import copy
import glob
import json
import shutil
from pathlib import Path
import mlx.core as mx
import mlx.nn as nn
import torch
from llama import Llama, ModelArgs, sanitize_config
from mlx.utils import tree_flatten, tree_map, tree_unflatten
def torch_to_mx(a: torch.Tensor, *, dtype: str) -> mx.array:
# bfloat16 is not numpy convertible. Upcast to float32 to avoid precision loss
a = a.to(torch.float32) if dtype == "bfloat16" else a.to(getattr(torch, dtype))
return mx.array(a.numpy(), getattr(mx, dtype))
def llama(model_path, *, dtype: str):
SHARD_FIRST = ["wv", "wq", "wk", "w1", "w3", "output"]
SHARD_SECOND = ["tok_embeddings", "wo", "w2"]
SHARD_WEIGHTS = set(SHARD_FIRST + SHARD_SECOND)
def shard_key(k):
keys = k.split(".")
if len(keys) < 2:
return None
return keys[-2]
def unshard(k, v):
wn = shard_key(k)
if wn not in SHARD_WEIGHTS:
return v
elif wn in SHARD_FIRST:
axis = 0
elif wn in SHARD_SECOND:
axis = 1
else:
raise ValueError("Invalid weight name")
return mx.concatenate(v, axis=axis)
torch_files = glob.glob(str(model_path / "consolidated.*.pth"))
weights = collections.defaultdict(list)
for wf in torch_files:
state = torch.load(wf, map_location=torch.device("cpu"))
for k, v in state.items():
v = torch_to_mx(v, dtype=dtype)
state[k] = None # free memory
if shard_key(k) in SHARD_WEIGHTS:
weights[k].append(v)
else:
weights[k] = v
for k, v in weights.items():
weights[k] = unshard(k, v)
with open(model_path / "params.json", "r") as f:
params = json.loads(f.read())
return weights, params
def tiny_llama(model_path, *, dtype: str):
try:
import transformers
except ImportError:
print("The transformers package must be installed for this model conversion:")
print("pip install transformers")
exit(1)
model = transformers.AutoModelForCausalLM.from_pretrained(
str(model_path)
).state_dict()
config = transformers.AutoConfig.from_pretrained(model_path)
# things to change
# 1. there's no "model." in the weight names
model = {k.replace("model.", ""): v for k, v in model.items()}
# 2. mlp is called feed_forward
model = {k.replace("mlp", "feed_forward"): v for k, v in model.items()}
# 3. up_proj, down_proj, gate_proj
model = {k.replace("down_proj", "w2"): v for k, v in model.items()}
model = {k.replace("up_proj", "w3"): v for k, v in model.items()}
model = {k.replace("gate_proj", "w1"): v for k, v in model.items()}
# 4. layernorms
model = {
k.replace("input_layernorm", "attention_norm"): v for k, v in model.items()
}
model = {
k.replace("post_attention_layernorm", "ffn_norm"): v for k, v in model.items()
}
# 5. lm head
model = {k.replace("lm_head", "output"): v for k, v in model.items()}
# 6. token emb
model = {k.replace("embed_tokens", "tok_embeddings"): v for k, v in model.items()}
# 7. attention
model = {k.replace("self_attn", "attention"): v for k, v in model.items()}
model = {k.replace("q_proj", "wq"): v for k, v in model.items()}
model = {k.replace("k_proj", "wk"): v for k, v in model.items()}
model = {k.replace("v_proj", "wv"): v for k, v in model.items()}
model = {k.replace("o_proj", "wo"): v for k, v in model.items()}
params = {}
params["dim"] = config.hidden_size
params["hidden_dim"] = config.intermediate_size
params["n_heads"] = config.num_attention_heads
if hasattr(config, "num_key_value_heads"):
params["n_kv_heads"] = config.num_key_value_heads
params["n_layers"] = config.num_hidden_layers
params["vocab_size"] = config.vocab_size
params["norm_eps"] = config.rms_norm_eps
params["rope_traditional"] = False
weights = {k: torch_to_mx(v, dtype=dtype) for k, v in model.items()}
return weights, params
def quantize(weights, config, args):
quantized_config = copy.deepcopy(config)
# Load the model:
config = sanitize_config(config, weights)
model = Llama(ModelArgs(**config))
weights = tree_map(mx.array, weights)
model.update(tree_unflatten(list(weights.items())))
# Quantize the model:
nn.QuantizedLinear.quantize_module(model, args.q_group_size, args.q_bits)
# Update the config:
quantized_config["quantization"] = {
"group_size": args.q_group_size,
"bits": args.q_bits,
}
quantized_weights = dict(tree_flatten(model.parameters()))
return quantized_weights, quantized_config
def make_shards(weights: dict, max_file_size_gibibyte: int = 15):
max_file_size_bytes = max_file_size_gibibyte << 30
shards = []
shard, shard_size = {}, 0
for k, v in weights.items():
if shard_size + v.nbytes > max_file_size_bytes:
shards.append(shard)
shard, shard_size = {}, 0
shard[k] = v
shard_size += v.nbytes
shards.append(shard)
return shards
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Convert Llama weights to MLX")
parser.add_argument(
"--torch-path",
type=str,
help="Path to the PyTorch model.",
)
parser.add_argument(
"--mlx-path",
type=str,
default="mlx_model",
help="Path to save the MLX model.",
)
parser.add_argument(
"--model-name",
help=(
"Name of the model to convert. Use 'llama' for models in the "
"Llama family distributed by Meta including Llama 1, Llama 2, "
"Code Llama, and Llama chat."
),
choices=["tiny_llama", "llama"],
default="llama",
)
parser.add_argument(
"-q",
"--quantize",
help="Generate a quantized model.",
action="store_true",
)
parser.add_argument(
"--q-group-size",
help="Group size for quantization.",
type=int,
default=64,
)
parser.add_argument(
"--q-bits",
help="Bits per weight for quantization.",
type=int,
default=4,
)
parser.add_argument(
"--dtype",
help="dtype for loading the torch model and input for quantization or saving the converted model. "
"The original weights are stored in bfloat16.",
type=str,
default="float16",
)
args = parser.parse_args()
torch_path = Path(args.torch_path)
mlx_path = Path(args.mlx_path)
mlx_path.mkdir(parents=True, exist_ok=True)
print("[INFO] Loading")
weights, params = globals()[args.model_name](torch_path, dtype=args.dtype)
params["model_type"] = "llama"
if args.quantize:
print("[INFO] Quantizing")
weights, params = quantize(weights, params, args)
print("[INFO] Saving")
shutil.copyfile(
str(torch_path / "tokenizer.model"),
str(mlx_path / "tokenizer.model"),
)
shards = make_shards(weights)
if len(shards) == 1:
mx.savez(str(mlx_path / f"weights.npz"), **shards[0])
else:
for i, shard in enumerate(shards):
mx.savez(str(mlx_path / f"weights.{i:02d}.npz"), **shard)
with open(mlx_path / "config.json", "w") as fid:
json.dump(params, fid, indent=4)llama.py — this script handles the heavy lifting of running inference on our downloaded Llama2 model as well as handling tokenisation of our input. Whilst the model does not actually edit our model, it contains custom classes that RMSNorm, Attention, FeedForward and TransformerBlock that implement the transformer architecture which allow for the responses to our prompts to be coherent:
import argparse
import glob
import json
import time
from dataclasses import dataclass
from pathlib import Path
from typing import Optional, Tuple
import mlx.core as mx
import mlx.nn as nn
from mlx.utils import tree_unflatten
from sentencepiece import SentencePieceProcessor
@dataclass
class ModelArgs:
dim: int
n_layers: int
head_dim: int
hidden_dim: int
n_heads: int
n_kv_heads: int
norm_eps: float
vocab_size: int
rope_theta: float
rope_traditional: bool = True
class RMSNorm(nn.Module):
def __init__(self, dims: int, eps: float = 1e-5):
super().__init__()
self.weight = mx.ones((dims,))
self.eps = eps
def _norm(self, x):
return x * mx.rsqrt(x.square().mean(-1, keepdims=True) + self.eps)
def __call__(self, x):
output = self._norm(x.astype(mx.float32)).astype(x.dtype)
return self.weight * output
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.args = args
self.n_heads: int = args.n_heads
self.n_kv_heads: int = args.n_kv_heads
self.repeats = self.n_heads // self.n_kv_heads
self.scale = self.args.head_dim**-0.5
self.wq = nn.Linear(args.dim, args.n_heads * args.head_dim, bias=False)
self.wk = nn.Linear(args.dim, args.n_kv_heads * args.head_dim, bias=False)
self.wv = nn.Linear(args.dim, args.n_kv_heads * args.head_dim, bias=False)
self.wo = nn.Linear(args.n_heads * args.head_dim, args.dim, bias=False)
self.rope = nn.RoPE(
args.head_dim, traditional=args.rope_traditional, base=args.rope_theta
)
def __call__(
self,
x: mx.array,
mask: Optional[mx.array] = None,
cache: Optional[Tuple[mx.array, mx.array]] = None,
) -> Tuple[mx.array, Tuple[mx.array, mx.array]]:
B, L, D = x.shape
queries, keys, values = self.wq(x), self.wk(x), self.wv(x)
# Prepare the queries, keys and values for the attention computation
queries = queries.reshape(B, L, self.n_heads, -1).transpose(0, 2, 1, 3)
keys = keys.reshape(B, L, self.n_kv_heads, -1).transpose(0, 2, 1, 3)
values = values.reshape(B, L, self.n_kv_heads, -1).transpose(0, 2, 1, 3)
def repeat(a):
a = mx.concatenate([mx.expand_dims(a, 2)] * self.repeats, axis=2)
return a.reshape([B, self.n_heads, L, -1])
keys, values = map(repeat, (keys, values))
if cache is not None:
key_cache, value_cache = cache
queries = self.rope(queries, offset=key_cache.shape[2])
keys = self.rope(keys, offset=key_cache.shape[2])
keys = mx.concatenate([key_cache, keys], axis=2)
values = mx.concatenate([value_cache, values], axis=2)
else:
queries = self.rope(queries)
keys = self.rope(keys)
scores = (queries * self.scale) @ keys.transpose(0, 1, 3, 2)
if mask is not None:
scores += mask
scores = mx.softmax(scores.astype(mx.float32), axis=-1).astype(scores.dtype)
output = (scores @ values).transpose(0, 2, 1, 3).reshape(B, L, -1)
return self.wo(output), (keys, values)
class FeedForward(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.w1 = nn.Linear(args.dim, args.hidden_dim, bias=False)
self.w2 = nn.Linear(args.hidden_dim, args.dim, bias=False)
self.w3 = nn.Linear(args.dim, args.hidden_dim, bias=False)
def __call__(self, x) -> mx.array:
return self.w2(nn.silu(self.w1(x)) * self.w3(x))
class TransformerBlock(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.attention = Attention(args)
self.feed_forward = FeedForward(args=args)
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.args = args
def __call__(
self,
x: mx.array,
mask: Optional[mx.array] = None,
cache: Optional[Tuple[mx.array, mx.array]] = None,
) -> mx.array:
r, cache = self.attention(self.attention_norm(x), mask, cache)
h = x + r
r = self.feed_forward(self.ffn_norm(h))
out = h + r
return out, cache
class Llama(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.args = args
self.vocab_size = args.vocab_size
self.tok_embeddings = nn.Embedding(args.vocab_size, args.dim)
self.layers = [TransformerBlock(args=args) for _ in range(args.n_layers)]
self.norm = RMSNorm(args.dim, eps=args.norm_eps)
self.output = nn.Linear(args.dim, args.vocab_size, bias=False)
def __call__(self, x):
mask = nn.MultiHeadAttention.create_additive_causal_mask(x.shape[1])
mask = mask.astype(self.tok_embeddings.weight.dtype)
x = self.tok_embeddings(x)
for l in self.layers:
x, _ = l(x, mask)
x = self.norm(x)
return self.output(x)
def generate(self, x, temp=1.0):
def sample(logits):
if temp == 0:
return mx.argmax(logits, axis=-1)
else:
return mx.random.categorical(logits * (1 / temp))
cache = []
# Make an additive causal mask. We will need that to process the prompt.
mask = nn.MultiHeadAttention.create_additive_causal_mask(x.shape[1])
mask = mask.astype(self.tok_embeddings.weight.dtype)
# First we process the prompt x the same was as in __call__ but
# save the caches in cache
x = self.tok_embeddings(x)
for l in self.layers:
x, c = l(x, mask=mask)
# We store the per layer cache in a simple python list
cache.append(c)
x = self.norm(x)
# We only care about the last logits that generate the next token
y = self.output(x[:, -1])
y = sample(y)
# y now has size [1]
# Since MLX is lazily evaluated nothing is computed yet.
# Calling y.item() would force the computation to happen at
# this point but we can also choose not to do that and let the
# user choose when to start the computation.
yield y
# Now we parsed the prompt and generated the first token we
# need to feed it back into the model and loop to generate the
# rest.
while True:
# Unsqueezing the last dimension to add a sequence length
# dimension of 1
x = y[:, None]
x = self.tok_embeddings(x)
for i in range(len(cache)):
# We are overwriting the arrays in the cache list. When
# the computation will happen, MLX will be discarding the
# old cache the moment it is not needed anymore.
x, cache[i] = self.layers[i](x, mask=None, cache=cache[i])
x = self.norm(x)
y = sample(self.output(x[:, -1]))
yield y
def tic():
return time.time()
def toc(msg, start):
end = time.time()
return f"[INFO] {msg}: {end - start:.3f} s"
def generate(args):
input("Press enter to start generation")
print("------")
print(args.prompt)
x = mx.array([[tokenizer.bos_id()] + tokenizer.encode(args.prompt)])
skip = 0
prompt_processing = None
tokens = []
start = tic()
for token in model.generate(x, args.temp):
tokens.append(token)
if len(tokens) == 1:
# Actually perform the computation to measure the prompt processing time
mx.eval(token)
prompt_processing = toc("Prompt processing", start)
if len(tokens) >= args.max_tokens:
break
elif (len(tokens) % args.write_every) == 0:
# It is perfectly ok to eval things we have already eval-ed.
mx.eval(tokens)
s = tokenizer.decode([t.item() for t in tokens])
print(s[skip:], end="", flush=True)
skip = len(s)
mx.eval(tokens)
full_gen = toc("Full generation", start)
s = tokenizer.decode([t.item() for t in tokens])
print(s[skip:], flush=True)
print("------")
print(prompt_processing)
print(full_gen)
def few_shot_generate(args):
def possible_end(s):
word = "[Instruction]"
for i in range(len(word) - 1, 0, -1):
if s[-i:] == word[:i]:
return 0
if s[-len(word) :] == word:
return 1
return -1
def generate(question):
x = mx.array([[tokenizer.bos_id()] + tokenizer.encode(question)])
skip = 0
prompt_processing = None
tokens = []
start = tic()
for token in model.generate(x, args.temp):
tokens.append(token)
if len(tokens) == 1:
# Actually perform the computation to measure the prompt processing time
mx.eval(token)
prompt_processing = toc("Prompt processing", start)
if len(tokens) >= args.max_tokens:
break
mx.eval(tokens)
token_list = [t.item() for t in tokens]
s = tokenizer.decode(token_list)
end = possible_end(s)
if end == 0:
continue
if end == 1:
skip = len(s)
break
print(s[skip:], end="", flush=True)
skip = len(s)
if token_list[-1] == tokenizer.eos_id():
break
mx.eval(tokens)
full_gen = toc("Full generation", start)
s = tokenizer.decode([t.item() for t in tokens])
print(s[skip:], end="", flush=True)
print("[INFO] Loading few-shot examples from: {}".format(args.few_shot))
prompt = open(args.few_shot).read().strip()
while True:
question = input("Ask a question: ")
generate(prompt.replace("{}", question))
print()
def sanitize_config(config, weights):
config.pop("model_type", None)
n_heads = config["n_heads"]
if "n_kv_heads" not in config:
config["n_kv_heads"] = n_heads
if "head_dim" not in config:
config["head_dim"] = config["dim"] // n_heads
if "hidden_dim" not in config:
config["hidden_dim"] = weights["layers.0.feed_forward.w1.weight"].shape[0]
if config.get("vocab_size", -1) < 0:
config["vocab_size"] = weights["output.weight"].shape[-1]
if "rope_theta" not in config:
config["rope_theta"] = 10000
unused = ["multiple_of", "ffn_dim_multiplier"]
for k in unused:
config.pop(k, None)
return config
def load_model(model_path):
model_path = Path(model_path)
unsharded_weights_path = Path(model_path / "weights.npz")
if unsharded_weights_path.is_file():
print("[INFO] Loading model from {}.".format(unsharded_weights_path))
weights = mx.load(str(unsharded_weights_path))
else:
sharded_weights_glob = str(model_path / "weights.*.npz")
weight_files = glob.glob(sharded_weights_glob)
print("[INFO] Loading model from {}.".format(sharded_weights_glob))
if len(weight_files) == 0:
raise FileNotFoundError("No weights found in {}".format(model_path))
weights = {}
for wf in weight_files:
weights.update(mx.load(wf).items())
with open(model_path / "config.json", "r") as f:
config = sanitize_config(json.loads(f.read()), weights)
quantization = config.pop("quantization", None)
model = Llama(ModelArgs(**config))
if quantization is not None:
nn.QuantizedLinear.quantize_module(model, **quantization)
model.update(tree_unflatten(list(weights.items())))
tokenizer = SentencePieceProcessor(model_file=str(model_path / "tokenizer.model"))
return model, tokenizer
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Llama inference script")
parser.add_argument(
"--model-path",
help="Path to the model weights and tokenizer",
default="mlx_model",
)
parser.add_argument(
"--prompt",
help="The message to be processed by the model. Ignored when --few-shot is provided.",
default="In the beginning the Universe was created.",
)
parser.add_argument(
"--few-shot",
help="Read a few shot prompt from a file (as in `sample_prompt.txt`).",
)
parser.add_argument(
"--max-tokens", "-m", type=int, default=100, help="How many tokens to generate"
)
parser.add_argument(
"--write-every", type=int, default=1, help="After how many tokens to detokenize"
)
parser.add_argument(
"--temp", type=float, default=0.0, help="The sampling temperature"
)
parser.add_argument("--seed", type=int, default=0, help="The PRNG seed")
args = parser.parse_args()
mx.random.seed(args.seed)
model, tokenizer = load_model(args.model_path)
if args.few_shot:
few_shot_generate(args)
else:
generate(args)You then need to add the respective tokenizer.model file to the model’s folder. For example, if you downloaded the llama-2–7B model from meta, you should have a llama-2–7B directory within your mlx directory. You then need to place the llama tokeniser into that model directory. To do so, visit HuggingFace and download the tokenizer.model file. Paste it into the model directory. The same tokeniser can be used regardless of model size — i.e. you can use the file from the above link even if you downloaded the 13B version of the model.
Inference:
Let’s run some inference.
Open your terminal at the mlx folder and enter the following command:
python convert.py --torch-path ./llama-2-model-folder -q
Replace llama-2-model-folder with the name of your downloaded model folder eg llama-2–7B. The -q parameter applies 4-bit quantisation to speed-up inference. Again make sure you’ve pasted the tokenizer.model file from the previous section into the respective model folder.
The output should look like this:

Your model tensors have now been converted to MxNet and the model has been quantised.
Now enter:
python llama.py --prompt "A great hobby to have is" -m 30Here we execute the llama.py script, input our prompt and set a max_token value with the -m parameter. Have a play with these inputs. Further details on the parameters can be found when entering:
python llama.py --helpBelow is the output of our prompt after pressing enter to start generation:
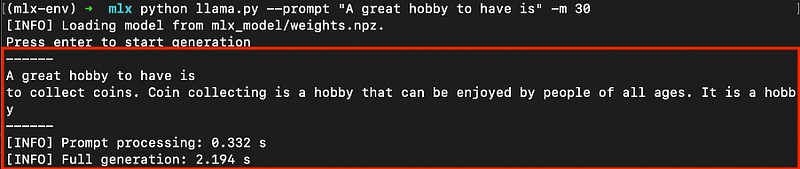
Notice the output is truncated due to our max_token limit.
Let’s benchmark this against the un-quantised equivalent:

As expected (and as we learned from my previous article!), inference takes longer on the un-quantised version.
If you run into any errors when swapping between quantised/unquantized models or models of different sizes, simply deleted the mlx_model folder that is created when running the convert.py script. Then re-run the convert.py script with your chosen parameters.
GPU usage:
Finally, as evidence that we are actually using the apple hardware — let’s have a look at the GPU read-out when running inference. Press cmd + spacebar and search for “Activity Monitor”.
Then, along the top of your screen you will see various menu options. Select Window > GPU History. Then start running some inference. You will see it spiking whenever you run inference on your LLM:
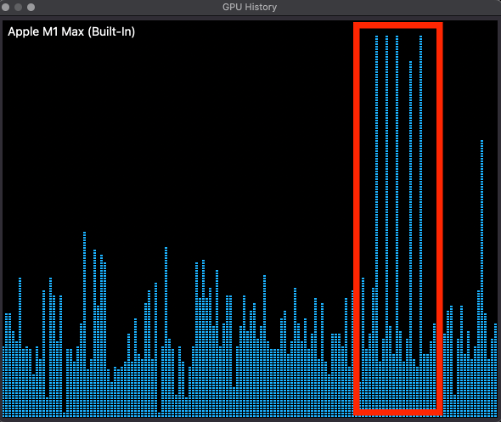
Conclusion:
So here are my closing thoughts: If you are heavily invested in developing, training and fine-tuning LLM solutions, I still believe you’ll be better off using NVIDIA hardware — mainly due to software/library support.
Nevertheless, the development work from the Apple’s MLX team is very welcome and really makes LLMs much more approachable to hobbyists and professionals of all abilities and backgrounds. I’m excited to see how the project develops.
As stated previously, I will be creating a further article on LLM fine-tuning using the MLX library. It will build upon what I’ve covered in this article so make sure to follow me and keep an eye out for that.
As always, let me know if you have any questions.
All images belong to the author unless otherwise stated.





