
Ridge Regressions on Easy Mode
Learn the theory behind Ridge Regression Models, how to code and tune them through python and scikit-learn.
What are they?
Ridge Regressions can be thought of a step up from linear regressions. They are also known as Tikhonov regularizations; and are particularly useful in mitigating the problem of multicollinearity in linear regression, which commonly occurs in models with large numbers of parameters.

Briefly recapping linear regressions: They estimate linear model intercept and slope coefficients through minimizing the residual sum of squares(RSS) of the model. The RSS formula along with its resultant linear model is shown below:
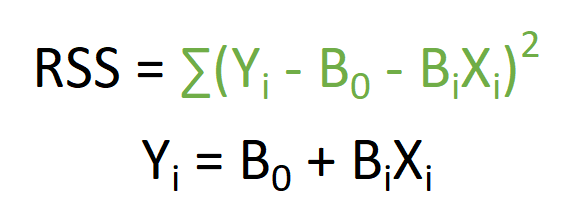
While simple linear regressions are generally considered effective in most data analysis cases, they always produce straight best-fit-lines. This arises from the strong prior assumption about the relationship between dependent and independent variables: that they have a linear relationship.
The problem comes when we have to do away with this assumption, we would need to come to terms with the lack of parameters to control for model complexity.
This is where ridge regressions come in.They add in an extra term as shown below in red.
This term is known as a L2 regularization parameter, where L1 can yield sparse models while L2 does not. The end result would still be a simple linear model, similar in format if the OLS method was used, but probably with differing coefficients. (shown through an example below)
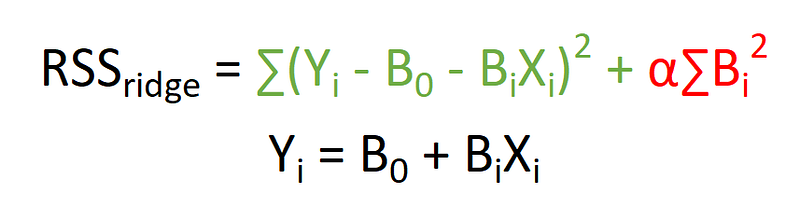
The regularization term acts as a loss function which is a penalty for wrong predictions when computing the RSS of the ridge regression. It acts by adding the squared values of coefficients to the RSS of the model. As the ‘best’ model is the one with the minimized RSS, models with larger coefficients are effectively filtered against.
Regularization acts to reduce overfitting by attempting to restrict the model to reduce complexity. The Regularization Term acts by adding the squared values of coefficients to the RSS of the model. As the ‘best’ model is the one with the minimized RSS, models with larger coefficients are effectively filtered against.
As an end result, models prefer features with smaller coeffcients.
Regularization is especially effective for 100+ variables. Further, the amount of regularization is controlled by the alpha parameter in the regularization term. A higher alpha value results in more penalty incurred by the model, shrinking coefficients further towards 0. The default value in python is 1. A special case to take not is that when alpha = 0, the resultant model is equivalent to the OLS simple linear regression.
The Code
To exemplify the coding of a ridge regression, we’ll look at using the crime dataset.
Packages
For packages, let’s import the crime dataset, and classes for creating train-test splits, conducting MixMaxScaling and creation of the Ridge Regression.
import numpy
from adspy_shared_utilities import load_crime_dataset
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import RidgeLoading the dataset, and creating a 75 / 25 train test data split:
(X_crime, y_crime) = load_crime_dataset()
X_train, X_test, y_train, y_test = train_test_split(X_crime,
y_crime, random_state = 0)
# take note of the indentation.Scaling both training and test data sets:
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)Creating the ridge regression object with an alpha value of 20.0 and fitting that object on the scaled X training data along with the corresponding training data Y labels:
linridge = Ridge(alpha=20.0).fit(X_train_scaled, y_train)Obtaining Model Coefficients:
linridge.intercept_
linridge.coef_ -3352.423035846206
[ 1.95091438e-03 2.19322667e+01 9.56286607e+00 -3.59178973e+01
6.36465325e+00 -1.96885471e+01 -2.80715856e-03 1.66254486e+00
-6.61426604e-03 -6.95450680e+00 1.71944731e+01 -5.62819154e+00
8.83525114e+00 6.79085746e-01 -7.33614221e+00 6.70389803e-03
9.78505502e-04 5.01202169e-03 -4.89870524e+00 -1.79270062e+01
9.17572382e+00 -1.24454193e+00 1.21845360e+00 1.03233089e+01
-3.78037278e+00 -3.73428973e+00 4.74595305e+00 8.42696855e+00
3.09250005e+01 1.18644167e+01 -2.05183675e+00 -3.82210450e+01
1.85081589e+01 1.52510829e+00 -2.20086608e+01 2.46283912e+00
3.29328703e-01 4.02228467e+00 -1.12903533e+01 -4.69567413e-03
4.27046505e+01 -1.22507167e-03 1.40795790e+00 9.35041855e-01
-3.00464253e+00 1.12390514e+00 -1.82487653e+01 -1.54653407e+01
2.41917002e+01 -1.32497562e+01 -4.20113118e-01 -3.59710660e+01
1.29786751e+01 -2.80765995e+01 4.38513476e+01 3.86590044e+01
-6.46024046e+01 -1.63714023e+01 2.90397330e+01 4.15472907e+00
5.34033563e+01 1.98773191e-02 -5.47413979e-01 1.23883518e+01
1.03526583e+01 -1.57238894e+00 3.15887097e+00 8.77757987e+00
-2.94724962e+01 -2.32995397e-04 3.13528914e-04 -4.13628414e-04
-1.79851056e-04 -5.74054527e-01 -5.17742507e-01 -4.20670930e-01
1.53383594e-01 1.32725423e+00 3.84863158e+00 3.03024594e+00
-3.77692644e+01 1.37933464e-01 3.07676522e-01 1.57128807e+01
3.31418306e-01 3.35994414e+00 1.61265911e-01 -2.67619878e+00]Obtaining Model R-squared scores
linridge.score(X_train_scaled, y_train)
linridge.score(X_test_scaled, y_test)-31.672
-37.249Number of non-zero features:
(np.sum(linridge.coef_ != 0))88
Tuning the alpha value to maximise training and test scores. We can obtain the number of non-zero features and the train and test scores as below:
for alpha in [0, 1, 10, 20, 50, 100, 1000]:
linridge = Ridge(alpha = this_alpha).fit(X_train_scaled,y_train)
r2_train = linridge.score(X_train_scaled, y_train)
r2_test = linridge.score(X_test_scaled, y_test)
num_coeff_bigger = np.sum(abs(linridge.coef_) > 1.0)
print('Alpha = {:.2f}\nnum abs(coeff) > 1.0: {}, \
r-squared training: {:.2f}, r-squared test: {:.2f}\n'
.format(this_alpha, num_coeff_bigger, r2_train, r2_test))Ridge regression: effect of alpha regularization parameterAlpha = 0.00
num abs(coeff) > 1.0: 88, r-squared training: 0.67, r-squared test: 0.50
Alpha = 1.00
num abs(coeff) > 1.0: 87, r-squared training: 0.66, r-squared test: 0.56
Alpha = 10.00
num abs(coeff) > 1.0: 87, r-squared training: 0.63, r-squared test: 0.59
Alpha = 20.00
num abs(coeff) > 1.0: 88, r-squared training: 0.61, r-squared test: 0.60
Alpha = 50.00
num abs(coeff) > 1.0: 86, r-squared training: 0.58, r-squared test: 0.58
Alpha = 100.00
num abs(coeff) > 1.0: 87, r-squared training: 0.55, r-squared test: 0.55
Alpha = 1000.00
num abs(coeff) > 1.0: 84, r-squared training: 0.31, r-squared test: 0.30Conclusion
Through this article, I hope that you have learned the theory behind Ridge Regressions, how to code and tune Ridge Regression Models through python and scikit-learn.
I was able to learn this through the MOOC “Applied Machine Learning in Python” by the University of Michigan, hosted by Coursera.
Do feel free to reach out to me on LinkedIn if you have questions or would like to discuss post Covid-19 world!
I hope that I was able to help you in learning about data science methods in one way or another!
Here’s another data science article for you!