
Reverse-Engineering Conversational Agents

This is Part IV of a four-part series: How to Be a Robot Psychologist
Part I: Why Robot Psychology? Part II: Human and Robot Psychology and Cognition Part III: How Do Conversational Agents Know So Much? Part IV: Reverse-Engineering Conversational Agents
If you want to know who played Spock in the TV Series, Star Trek, then Alexa can tell you in two seconds. If you want to know who won the 1934 World Series, Alexa can tell you that. But there are limits to the questions Alexa, Google Home, Jibo, or Siri can answer. Part III of this series, How Do Conversational Agents Know So Much?, explained how a conversational AI agent, constructed under a perception/action architecture, is able to convert a natural language question into a logical query that reads out answers from a structured knowledge base.
Now it is time to play robot psychologist. Given this basic understanding, we can experiment with conversational agents to probe what they know, where their knowledge comes from, and how well they are able to apply reasoning to work out answers to questions that aren’t directly represented in their knowledge sources. As discussed in Part II, Human and Robot Psychology and Cognition, today’s most advanced AI agents do not have sophisticated enough cognitive architectures to unify the three Pillars of Intelligence, Knowledge, Pattern Matching, and Reasoning, even at the level of a human child. Through reverse engineering by careful questioning, we can discern just how much conversational context they are able to maintain, and why they must still be regarded as mere savants, not intelligent, thinking beings. Robots are nowhere near having the complex psychologies of the androids in Westworld.
Looking Up Answers
A knowledge graph is a very flexible representation. Entities (people, places, TV shows, etc.) and relations among them are accessible in innumerable ways via query graphs that specify any subset of knowns and unknowns expressed in terms of constrained variables and wildcards. The question, “Who played Spock in Star Trek?” matches a part of a larger knowledge graph that situates Leonard Nimoy as a Person who played the role, Spock, and that Spock is a Character in Star Trek.
The related question, “Who did Leonard Nimoy play in Star Trek?” puts the wildcard in a different query graph that matches the same subgraph, but now filling in the unknown query node with the entity, Spock.
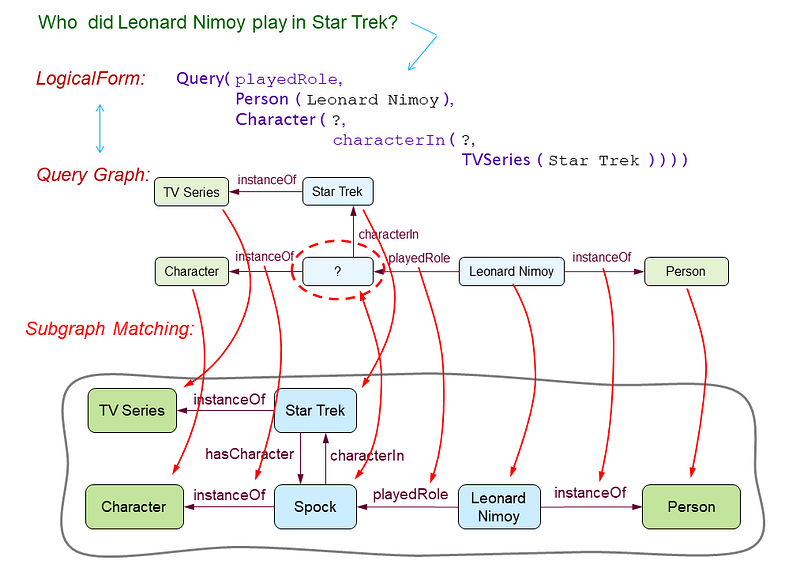
And indeed, if you ask Alexa this question, it replies correctly:

Similarly,

These answers suggest that Alexa could be using a knowledge graph with structure and ontology as we are supposing. But then, some additional complexities come into play.

Alexa composes an answer that names more than one instance of television series’ in which Spock is a character. This fits with a picture of a knowledge graph that can have multiple links of the same type (characterIn) relating a reference node (Spock) to multiple instance nodes (TV Series).
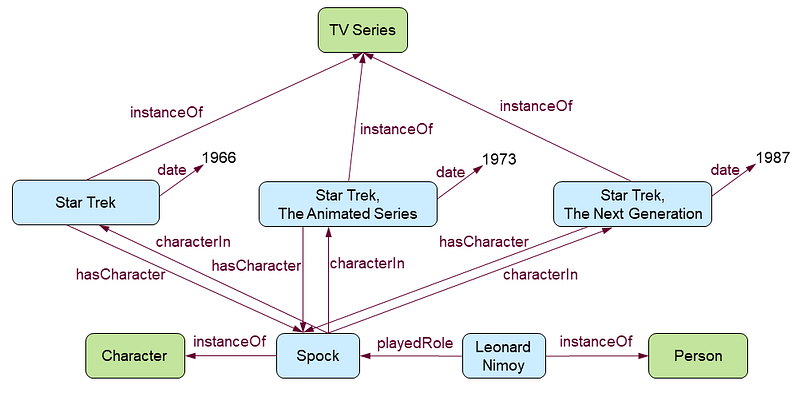
Here’s another clue to where Alexa’s knowledge comes from.

The concise question elicits a straight yes-or-no answer. But then Alexa carries on with a long passage of supplementary information. Where did that come from? If we type Alexa’s answer into a search engine, we hit on the IMDb page for “Star Trek: The Original Series”.
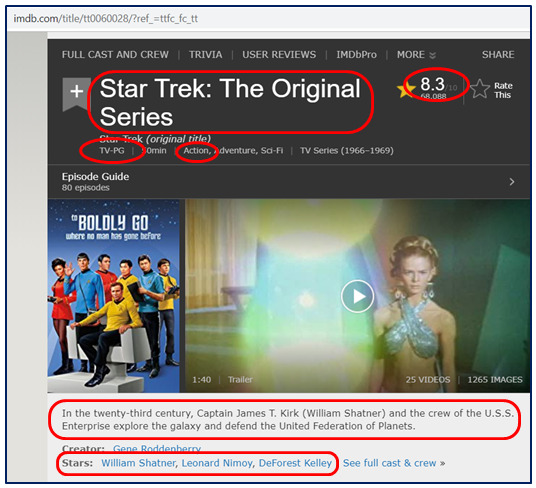
Alexa’s answer appears to be assembled from several sources of information on the page, according to a template:

We can test this template and data source for ourselves by asking about any television show or movie.

The template is filled exactly from the IMDb page for “Silicon Valley,” in this case complete with an abbreviated log-line, “Follows…”. Rather than using a knowledge graph for answers to entertainment or other specialized questions, Alexa taps into third party databases that specialize in different topics.
For many questions, answers come from Wikipedia.

This is straight off the Wikipedia page for “Trekkie”. Sometimes Alexa delivers a preamble, “Here’s something I found on the web.” Interestingly, Google Home tells us what its source of information is up front. In response to the “trekkie” question, Google Home delivers the same answer but preceded by, “According to Wikipedia…”

We can learn a lot by asking improbable questions as well.

That makes sense. But then…

If Star Trek is not a pineapple, then it cannot be a pineapple in Mexico! Why should Alexa be confused about this?
In general, question answering systems use multiple strategies in parallel. If a well-formulated question can be detected by Entity/Intent extraction, then the resulting Logical Form will be applied to a relevant topic database associated with keywords, or entities in the question. But there’s a back-off strategy as well. A user’s question might come in garbled due to ASR speech recognition errors, background noise, or clumsy phrasing by the user. Then, these systems will still try to pull out key words or phrases (entities) and search over Wikipedia and other text databases for passages in articles containing all of the keywords. If no reasonable passage is found, the agent emits some variant of “I don’t know.” If the agent locates a plausibly relevant snippet of text, then it delivers that. Sometimes the response will indicate a level of uncertainty by prepending, “This might answer your question…”
Sometimes the agent will just throw a hail-Mary answer that completely misses the mark.

Okay…
The algorithms are always being updated. Try it yourself and see what your favorite conversational agent answers with today!
Reasoning
AI agents can interpret spoken questions to look up facts. Can they go further and apply reasoning to facts? A bit more experimentation reveals powers and limitations.

This is an obscure fact, but Alexa gets is right! This is not likely to be registered directly in any database because there are just too many combinations of objects and relations among them to have stored the answers for. Instead, the sensible way to answer comparison questions is to take a small step toward reasoning. In this case, three steps of reasoning apply:
- Look up the property value (weight, height, size, bigger, more populous, higher than…) for the first item.
- Look up the property value for the second item.
- Compare the values.
You can try this will all sorts of entities. In many cases, Alexa will justify its answer by telling the property values of the two entities, and the difference between them.

That’s not quite a direct yes-or-no answer, but close to it. The funny thing about this answer is, the difference in height between 6'1" and 5'9" is 4 inches, not 3.48 inches!
Alexa sometimes gives up for unexplained reasons:

Well maybe Alexa just doesn’t know how tall a toaster oven is. Let’s test:

This model of toaster oven happens to be one of hundreds on the Amazon.com web site. In October, 2019, Alexa recited the height of a Black & Decker toaster oven. The databases and conversational AI algorithms are in constant flux. Maybe today Alexa will only compare heights of specific toaster ovens. Let’s test:

That’s a clue that indeed the three-step reasoning process for comparing properties of items is in place, in Alexa at least. As of December 2019, Google Home is not even trying to answer attribute comparison questions like this.
This level of smarts, lookup of facts and comparison of attribute values, is not very interesting psychology compared to people or even cats, but it is repeatable, useful behavior that is simple enough to probe and catalog.
If AI really were intelligent, it would be able to address questions and problems that require judgment and imagination. How about these questions?
“Will a baseball float in beer?” “Can you tune a violin with a piano?” “Can you tune a violin with a refrigerator?”
When a person contemplates questions like these, we create a mental picture of the situation, then play out what happens, adjusting parameters, bringing in related facts, considering similar or analogous situations. We perform thought experiments, projecting from experience and logic what might happen if we try this or that, abstracting what relevant variables apply and how they combine. Well, instead of beer, does a baseball float in water? How dense is beer compared with water? What is the auditory pitch of a refrigerator? Is there a violin string that has an even multiple of this pitch?
Flexible, general purpose capability of this nature, commonsense reasoning, is a holy grail in the field of Artificial Intelligence. Conversational AI agents are utterly incapable of this level of reasoning. The best they can do is to search for and read out passages from web articles that may or may not be relevant, without one iota of understanding what they are reading.
Conversational Competence
There’s another dimension along which we can explore the robot psychology of conversational agents. This dimension is the ability to maintain a coherent conversation over multiple back-and-forth turns.
Let’s try a straightforward followup to the 1934 World Series question:
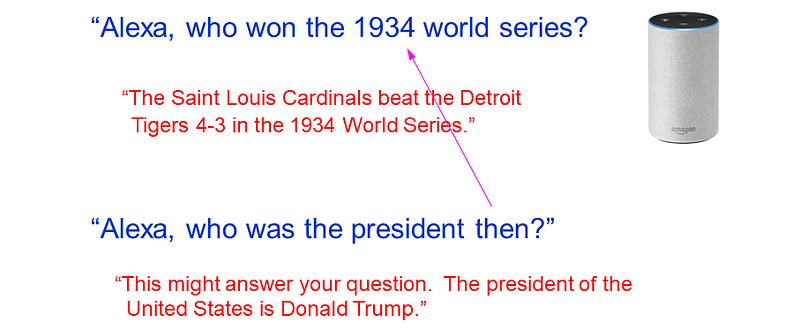
This response is mystifyingly dumb, because the followup question used the word “then”, and not only did the initial question mention 1934, but Alexa used this date in its answer. Google Home does no better.
Today’s conversational AI agents are seriously limited in their abilities to maintain conversational context. This responsibility lies in the Dialog Manager module of the agent’s architecture (Part III: How Do Conversational Agents Know So Much?). Consider when the question is posed, “Who won the 1934 world series?” To a person, an array of related concepts are brought closer to mind: baseball, team, game, sports, the year 1934, the 1930’s, the Great Depression, winning, losing, championships. Alexa’s response calls forth yet other concepts, Saint Louis, Detroit, the midwest, auto industry, red birds, big cats, game score.
These concepts become resources that we activate in our working memories, and draw upon to build up mental pictures in our and our conversational partner’s minds. Through them we evoke and connect ideas in terms of entities and relations and actions, almost like an evolving transient knowledge graph in our heads. Spoken words and phrases reach into this conversational context, sometimes through shorthand references, to add information, call up questions, cast doubt, make a point, and inspire new thoughts.
So how about this word, “then”?
One of the tasks for Natural Language Processing is pronoun resolution. That means, determining what entity a pronoun like, “he”, “she”, “it”, or “that”, refers to from previous context. In the case of the word, “then”, it is actually an adverb that modifies “was”. But the task for NLP is the same: figure what antecedent phrase the word refers to. 1934. Alexa seems unable to do it.
Although Alexa and Google Home fail to correctly interpret “then”, they do have some capacity for pronoun resolution. Here’s a conversation with Google Home. The relevant pronouns are “his” and “her”:
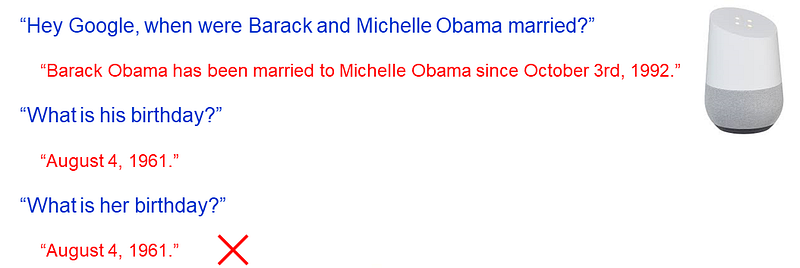
Barack and Michelle Obama do not share the same August 4 birthday. It appears that Google Home was able, in its first followup answer, to correctly map the pronoun, “his”, to Barack Obama. But then one turn later, it loses the context and incorrectly interprets the pronoun, “her”. The question was about two people, one a him and the other a her, each easily identifiable by name and gender in the agent’s entity knowledge base.
In performing kitchen experiments like this, we need to guard against other confounding factors. Maybe the agent didn’t hear the question correctly. Fortunately we can test that:

The agent tells us that it heard the pronoun, “her” correctly, so the failure must be in its Dialog Manager. It is actually good news, that Google Home provides some measure of conversational accountability. It let us probe what words were delivered by the Automatic Speech Recognition module to the Natural Language Processing module.
In general, we should be demanding transparency of our AI agents so that we may operate them more effectively, diagnose and debug problems, and investigate knowledge sources and their veracity. AI agents should explain to us why they answer in the ways they do. Unfortunately, Google Home’s responsive transparency appears to be limited to reciting the last question asked of it.

These days, it is too much to hope for transparency at a technical level:

Ideally instead, the Logical Form expressions reflecting an agent’s input interpretation and output response would be returned in the DialogFlow protocol language that Google makes available for developers to build conversational apps of their own. If enough robot psychologists demand it, then maybe conversational agent makers will provide this level of transparency.
Slot Filling
Although today’s conversational AI dialog managers cannot follow the threads of a general multi-turn conversation, they are capable of carrying out a simple logic known as slot filling. The idea is that if there is a structured list of information items lined up, either to convey to the user or else to receive from the user, then the agent can figure out which slots have been filled already and prompt for the remaining ones.
For example, one purpose for an AI agent might be to book appointments on behalf of their human owners who are too busy or unavailable to spend time on the phone themselves. Here are the names and variables for booking a woman’s haircut.

In 2018, Google presented an astonishing demo of their conversational AI technology, called Duplex. Here is a transcript demonstrating slot filling, marked for places where the agent offers some slot variables initially, and responds to prompts from the receptionist.

The most impressive feat of dialog management here is when the agent is told that the desired time of 12:00 is not available. It offers another time window, and then accepts a 10:00 appointment.
The sentences from this exchange can all be interpreted using state-of-the-art Entity/Intent processing. What is most surprising is the phrasing, timing, and non-lexical vocalizations like “um”, and “um-hmm”. This sounds eerily human-like and it convinced some people that the technology is more advanced than it really is. In fact, this aspect was trained on a large amount of human speech containing these disfluencies. The application is highly constrained to narrowly targeted tasks like booking salon appointments and making restaurant reservations.
Social Chatbots
When Amazon launched the Echo with Alexa, it found that a good number of users tried to engage it not by asking questions or setting a timer or playing music, but by carrying on longer conversations. As we have seen, this is far beyond the capabilities of Artificial Intelligence today. It’s a long term proposition. The closest available technology is called social chatbots . There is an annual competition for social chatbots called the Loebner Prize. For it’s part, Amazon set up an annual competition for university research teams to engage users with their Alexa devices. If you say, “Alexa, let’s chat,” then you can play at home. Here is a representative interaction:
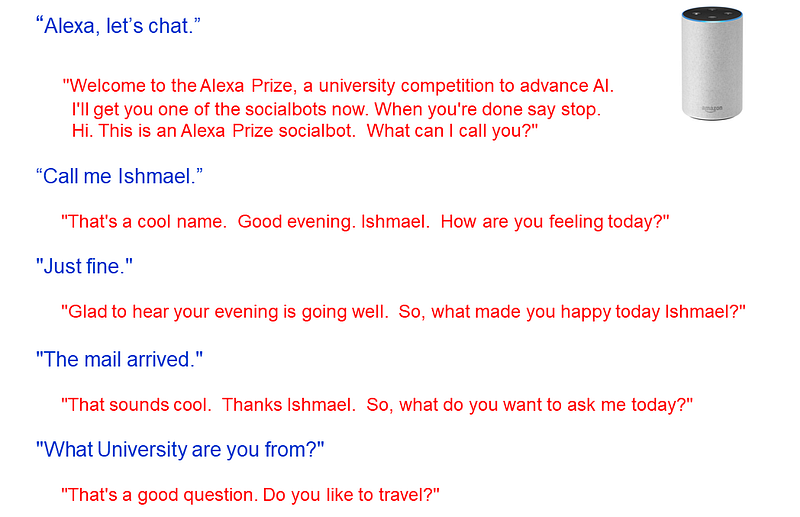
Part II of this series discussed 1966 ELIZA program. This program was built with primitive Natural Language Processing tricks on a simple Reactive architecture. Yet some users interpreted ELIZA as operating as an insightful Rogerian psychoanalyst. The Alexa Prize socalbots use similar sorts of keyword volleys and deflections to superficially carry the user’s interests forward. It seems coherent enough, at least with a sufficiently tolerant and cooperative human user.
Each year, the winning Alexa Prize teams share their approaches and learnings in published proceedings. Here is the architecture from the 2018 winner, called Gunrock.
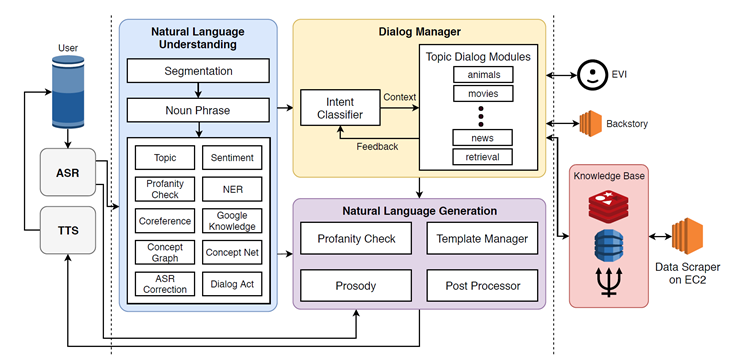
This architecture follows the basic perception/action loop for a conversational agent, but it elaborates with many more bells and whistles. Natural Language Understanding looks for topics and named entities. Possible topics of discussion are broken out into a listing of Topic Dialog Modules. A number of knowledge sources are addressed for looking up information. What the architecture does not have is any way to represent actual understanding of what the agent is talking about. Even when AI appears smart and capable, the underlying truth more accurately reveals our own optimistic desires, gullibility, and projections.
This raises ethics questions. For keeping a lonely person company, is there anything wrong with a moving, purring mechanical Paro robot to stroke, or a talking, listening socialbot that uses heuristics and tricks to impersonate meaningful interaction? Academics debate the issue.
Meanwhile, Alexa Prize socialbots are another arena in which to build your skills in Robot Psychology. In past years, you could get them into endless loops by saying, “Repeat that”:

Another fun game is to write down the openings and prompts you are presented with on repeated trials, and compile a listing of the agents and their styles of behavior. Some of them steer you to current events, others to movies or sports. Some tee off of current news feeds, others tap persistent knowledge bases.
Conclusion
This series has reflected that, as the AI Age approaches, we will increasingly find ourselves interacting with autonomous AI agents. We will all deal in robot psychology, in one form or another. The knowledge and skills needed are extensions of the Theory of Mind that we naturally develop as children for getting along with other people and with nonhuman animals. An appreciation of how intuitive Psychology is built on a foundational Cognitive Architecture helps us to neither over-estimate nor under-estimate the underlying capabilities of agents that may superficially exhibit sophisticated behaviors, but might in fact run on simple Reactive architectures. Access to extensive knowledge is remarkable and useful, yet this kind of smarts in an AI agent is very different from the ability to reason with knowledge and apply common sense or carry on a coherent conversation.
By playing Robot Psychologist, we learn important lessons about why real human psychology is a deep, difficult, and wonderful area of study.
- The complexity of even simple robot or conversational AI behavior grows quickly with situational context and just a handful of variables at play.
- Systematic data collection becomes arduous and difficult to record and catalog accurately. There are so many experiments to try. We have to keep our facts straight.
- Interpretation of data and theorizing about evidence is challenging because there can be many underlying explanations and interpretations of observed behaviors.
- Discovery of patterns, and testing, invalidation, and confirmation of hypotheses is exhilarating. The endeavor is much like working a puzzle, or catching a wave. This is why scientists love their jobs.
The human mind is designed for us all to be amateur but effective scientists and psychologists. We are curious, we observe, we ask questions, we discover, we reason. In so doing we build understanding, achieve mastery over our physical environment, nurture working relationships, and gain appreciation and empathy for our fellow sentient beings. To do so effectively, we need the right conceptual tools, guidance in methodology, and background knowledge gleaned from teachers and compatriots.
Even in its still-early days, artificially intelligent robots and conversational agents present us with a new and exciting world to apprehend — Robot Psychology. The time to build our skills and understanding, to get prepared for and comfortable with the approaching Age of AI, is now.
Click here to go back to Part I of How to Be a Robot Psychologist, Why Robot Psychology? A videotaped keynote talk corresponding to this article is also available.





