
Machine Learning Art
Re-Creating Your Own Face
With SOTA video algorithm

I will tell you about a technology that can generate near-human level videos of any person. Now, this technology could be used in advertising or movies, and it might seem like magic at first, but I think you’ll find out that it’s not far from the truth.
Improving the original StyleGAN2 image inversion and multi-stage non-linear latent-space editing, the authors propose an end-to-end facial video encoding approach that facilitates data-efficient high-quality video re-synthesis by optimizing low dimensional edits of a single Identity. The approach builds on StyleGAN2 image inversion and multi-stage non-linear latent space editing to generate videos that are nearly comparable to input videos. It captures face identity, head pose, and complex facial motions at acceptable levels and thereby bypasses training and person modeling, often hampering many re-synthesis approaches. This pipeline can also be used for puppeteering (i.e., motion transfer).
Project Page (scroll down)
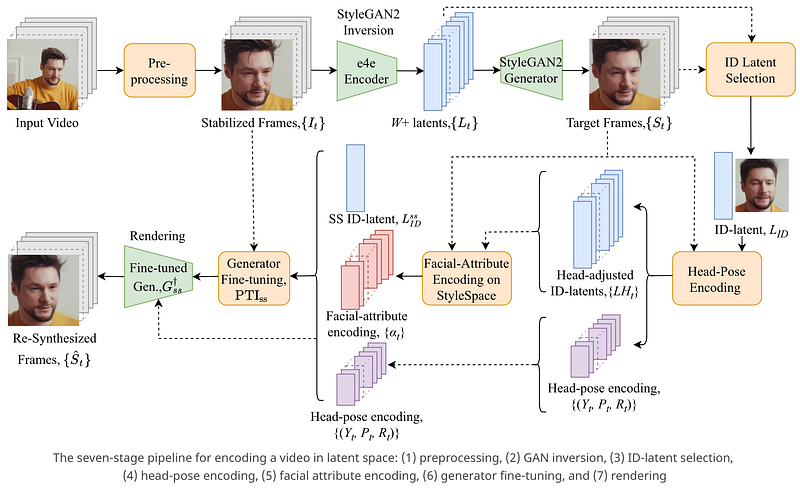
The authors are the initial: 🔵 in automating the editing of latent spaces in contrast to the prevailing work on latent-space editing that illustrates plausible semantic visual results (e.g. smiles, hair color, gaze) 🔵 to propose an extremely compact latent-based facial video encoding scheme that captures extremely fine, rich, and complex facial deformations.
Conclusion
The authors extend the StyleGAN2’s photo-realism and disentanglement of its StyleSpace spatiotemporally to propose a novel end-to-end pipeline for latent-based facial video encoding. It enables high-fidelity (10242) video re-synthesis and reenactment using a single W+ latent and 35 parameters per frame. Furthermore, their algorithm achieves SOTA performance for video re-synthesis at 10242 while using a fraction (0.38%) of parameters compared to StyleVideoGAN.
@article{oorloff2022encodeinstyle,
title={Encode-in-Style: Latent-based Video Encoding using StyleGAN2},
author={Trevine Oorloff and Yaser Yaoob},
year={2022},
eprint={2203.14512},
archivePrefix={arXiv},
primaryClass={cs.CV},
}
Project Page:
https://arxiv.org/pdf/2203.14512.pdf
Keywords: video resynthesis, video encoding, StyleGAN, image inversion, latent space editing
I invite you to explore the concept of “AI creativity” by reading and learning from the many articles found on 🔵 MLearning.ai 🟠
I am an Art Curator, founder at EvArtology. I advise companies and institutions in the creative industries on using AI tools in their daily work. Human collaboration with ML models can be very creative and bring huge benefits. The new era begins now.
Data Scientists must think like an artist when finding a solution when creating a piece of code. Artists enjoy working on interesting problems, even if there is no obvious answer.
All our writers (members) receive the opportunity to be promoted on our social media, which increases the popularity of articles published on MLearning.ai