
RAG 2.0, Finally Getting RAG Right!
The Creators of RAG Present its Successor

Looking at the AI industry, we have grown accustomed to seeing stuff get ‘killed’ every single day. I myself cringe sometimes when I have to talk about the 23923th time something gets ‘killed’ out of the blue.
But rarely the case is as compelling as what Contextual.ai has proposed with Contextual Language Models (CLMs), in what they call “RAG 2.0”, to make standard Retrieval Augmented Generation (RAG), one of the most popular ways (if not the most) of implementing Generative AI models, obsolete.
Behind the claim, none other than the initial creators of RAG.
And while this is a huge improvement over the status quo of production-grade Generative AI, one question lingers over this entire subspace: is RAG counting its last days, and are these innovations simply beating a dead horse?
Grounding on Data
As you may know or not know, all standalone Large Language Models (LLMs), with prominent examples like ChatGPT, have a knowledge cutoff.
What this means is that pre-training is a one-off exercise (unlike continual learning methods). In other words, LLMs have ‘seen’ data until a certain point in time.
For instance, ChatGPT is updated until April 2023 at the time of writing. Consequently, they are not prepared to answer about facts and events that took place after that date.
And this is where RAG comes in.
It’s all semantic similarity
As the proper name implies, the idea is to retrieve the data from a known database, data the LLM most probably has never seen before, and feed it into the model in real-time so that it has updated — and importantly, semantically relevant — context to provide an accurate answer.
But how does this retrieval process work?
The whole architecture stems from one single principle: the capacity to retrieve semantically meaningful data relevant to the context of the request or prompt.
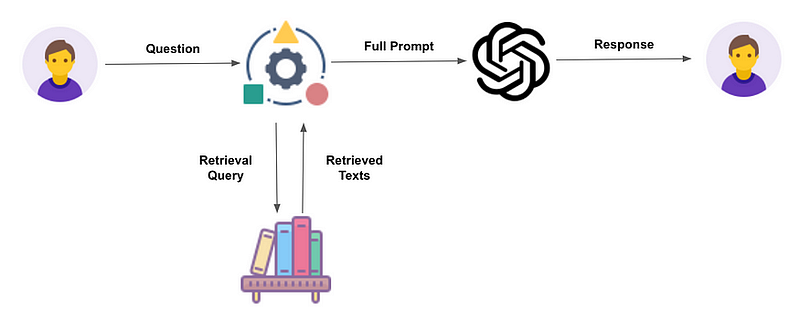
This process involves the use of three elements:
- The embedding model
- The retriever, often a vector database
- And the generator, the LLM
First and foremost, to make this retrieval process work, you need the data to be in ‘embedding form’, a representation of text in the form of a number vector.
And more importantly, these embeddings have a similarity principle: similar concepts will have similar vectors.
For example, the concepts of ‘dog’ and ‘cat’ are similar to us: both are animals, mammals, four-legged, and domestic. Translated into vectors, ‘dog’ could be [3, -1, 2] and ‘cat’ [2.98, -1, 2.2], and you can think of each number as an ‘attribute’ of that concept. Thus, similar numbers mean similar attributes.
Check my in-depth review of what embeddings are.
After we have the embeddings, we insert them into the vector database (the retriever), a high-dimensional database that stores these embeddings.
Applying the similarity principle we discussed earlier, in this space similar things are closer together.
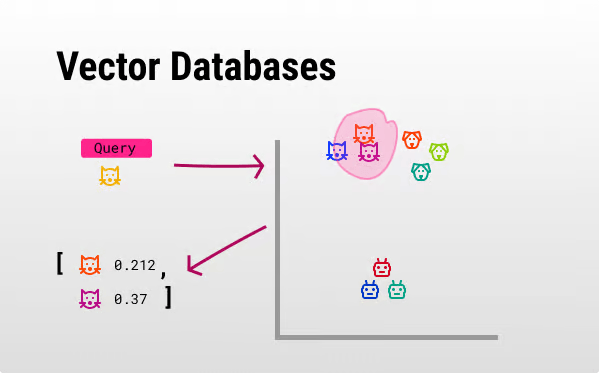
Then, whenever the user sends a request like the one below “give me similar results to a ‘yellow cat’”, the vector database performs a ‘semantic query’.
In layman’s terms, it performs an extraction of the closest vectors (in distance) to that of the user’s query.
As these vectors represent the underlying concepts, similar vectors will be representing similar concepts, in this case, other cats.
Once we have the extracted content, we build the LLM prompt, encapsulating:
- The user’s request
- The extracted content
- and, generally, a set of system instructions
But what is the system instruction?
As part of the prompt engineering process, you also want to tune how the model will respond. A typical system instruction might be “be concise”.
That’s RAG in a nutshell, a system that provides relevant content in real-time (at inference time) to the user query to enhance the LLM’s response.
The reason RAG systems work in the first place is due to LLMs’ greatest superpower: in-context learning, which allows models to use previously unseen data to perform accurate predictions without weight training.
Here’s a deep-dive into in-context learning and how LLMs learn to use it.
But this process sounds too good to be true and, of course, things are not as amazing as they look.
Understanding the key intutions driving the evolution of frontier AI models is hard. But it doesn’t have to be.
If you want to be up-to-date with the frenetic world of AI while also feeling inspired to take action or, at the very least, to be well-prepared for the future ahead of us, this newsletter is for you 🏝
Stitching with no Refinement, a Thing of the Past
One way to visualize current RAG systems is the following trouser:

Although these trousers might work for some audiences, most people would never wear them, as there’s no homogeneity, despite patched trousers originally meant to go unnoticed.
The reason behind this analogy is that standard RAG systems assemble three different components that were pre-trained separately and that, by definition, were never meant to be together.
Instead, RAG 2.0 systems are defined to be ‘one thing’ from the beginning.
No Frankenstein’s allowed here
In practice, the complete system is trained end-to-end while being connected, like assuming that LLMs should always have a vector database tied to them in order to stay updated.
Compared to standard RAG, pretraining, fine-tuning, and Reinforcement Learning from Human Feedback (RLHF), all essential components of standard LLM training are performed from scratch, including both the LLM and the retriever (the vector database).
In more technical terms, this means that, during backpropagation, the algorithm to train these models, the gradients are propagated not only through the entire LLM, but also through the retriever, so that the entire system, as a unison, learns from the training data.

And the results undeniably show for it:
Despite using what is almost guaranteed a worse standalone model than GPT-4, this new methodology outperforms every other possible RAG 1.0 combination between GPT-4 and other retrieval systems.
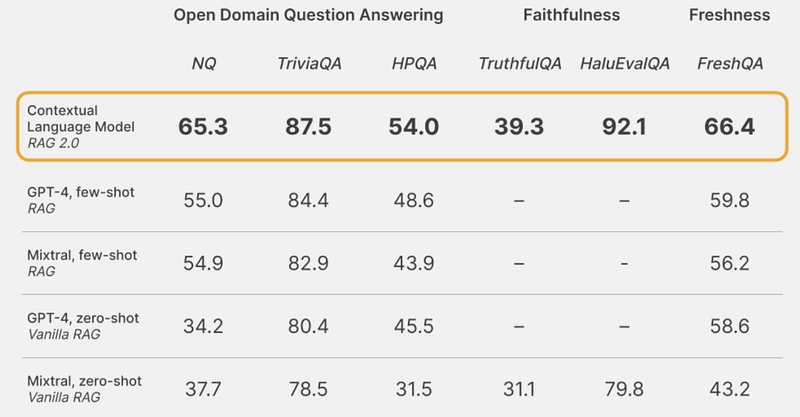
The reason is simple: In RAG 1.0 we train things separately, stitch them together, and hope for the best. But in RAG 2.0, things are much different, as all components are together from the very beginning.
In more technical terms, stitching together two separately trained systems is a receipt for disaster, especially if the learned representations aren’t equal.
It’s akin to an English person using a Japanese database; the context is there, but it’s not interpretable by the English person.
But even though RAG 2.0’s advantages are clear, one big question remains.
The Real Question is Still Unanswered
Although it seems RAG 2.0 might become the enterprise standard shortly due to its design that is specifically aimed at companies unwilling to share confidential data with the LLM providers, there’s a reason to believe that RAG, no matter the version, won’t eventually be required at all.
The Arrival of Huge Sequence Length
I’m sure you are very aware of the fact that our frontier models today, models like Gemini 1.5 or Claude 3, have huge context windows that go up to a million tokens (750k words) in their production-released models and up to 10 million tokens (7.5 million words) in the research labs.
In layman’s terms, this means that these models can be fed absurdly long sequences of text in every single prompt.
For reference, The Lord of The Rings books have a total of 576,459 words, and Harry Potter's entire book saga has around 1,084,170 words. Therefore, a 7.5-million-word context window could fit both stories together, five-fold, in every single prompt.
In that scenario, do we really need a knowledge retriever knowledge base instead of just feeding the information in every prompt?
One reason to discard this option could be accuracy. The longer the sequence, the harder it should be for the model to retrieve the correct context, right?
On the other hand, instead of feeding the entire context in every prompt, the RAG process allows for the selection of only the semantically relevant data, thus making it a more efficient process overall.
However, as proven by Google, accuracy isn’t impacted in long sequences, as they have shown almost 100% accuracy even at 10-million-tokens-long contexts for the Needle-in-the-Haystack task, where a small, sometimes unrelated fact is hidden in the depths of the prompt to see if the model retrieves it correctly.
And boy it does:
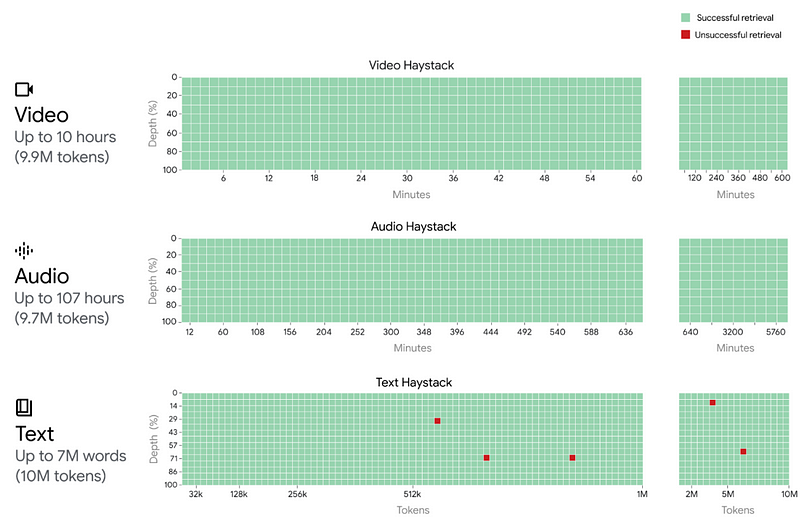
But how is this possible?
The technical reason behind such an amazing no-matter-the-length performance is that the underlying operator behind these models, the attention mechanism, has absolute global context, as the attention mechanism forces every single token (aka a word or subword) to attend to every single other previous word in the sequence.
This ensures that no matter how long-range the dependency is, and no matter how small the signal is (the key information could be stored in one single word millions of words away) the model should be able — and it’s able — to detect it.
Consequently, in my opinion, whether RAG eventually survives or not will not depend on accuracy, but on another key factor that goes beyond technology:
Cost.
Better Business Case, or Death
Today, due to the Transformer’s inability to compress context, longer sequences not only imply a quadratic increase in cost (a 2x on the sequence means a 4x in computations, or a 3x increase means a 9x in computation cost) but also imply memory requirements to explode due to the increase of the KV Cache’s size.
The KV Cache is the ‘cached memory’ of the model, avoiding having to recompute huge amounts of redundant attention data that would otherwise make the process economically unfeasible. Here’s an in-depth review of what the KV Cache is and how it works.
In short, running very long sequences is absurdly expensive, to the point that for modalities that have extremely long sequence lengths, like DNA, Transformers aren’t even considered.
Indeed, in DNA models like EVO, the researchers used the Hyena operator instead of attention to avoid the previously mentioned quadratic relationship. Hyena operators use long convolutions instead of attention to capture long-range dependencies with a subquadratic cost.
But wait, isn’t convolution a quadratic operation too?
Yes but, while standard convolution is indeed quadratic in cost, by applying the convolution theorem that states that the Fourier Transform of a convolution between two functions is the point-wise product (Hadamard product) of their respective Fourier transforms, you can perform the operation in subquadratic time and cost, an operation going by the name of ‘fast convolution’.
Essentially, although you are calculating a convolution in the time domain, you are computing it as a point-wise product in the frequency domain, which is faster and cheaper.
Other alternatives aim for a hybrid approach that, instead of ditching attention altogether, finds the sweet spot between attention and other operators to maintain performance with lower costs.
Recent examples include Jamba, which cleverly mixes Transformers with other, more efficient architectures like Mamba.
Mamba, Hyena, Attention… you are probably thinking I’m just name-dropping fancy words to prove a point.
But forget about the different weird names, at the end of the day it all boils down to the same principle: they are different ways to uncover patterns in language to help our AI models understand text.
Attention fuels 99% of models today, and the rest are simply trying to find cheaper ways with the minimal performance degradation possible to make LLMs more inexpensive.
All in all, we should soon see extremely long sequences being processed by a fraction of a fraction of the current price, which should increase skepticism over the need for RAG architectures.
When that time comes, which we can almost guarantee will happen, will we still rely on RAG? I don’t know, but there’s a chance we are beating a dead horse at this point.
On a final note, if you have enjoyed this article, I share similar thoughts in a more comprehensive and simplified manner for free on my LinkedIn.
If preferable, you can connect with me through X.
Looking forward to connecting with you.





