
JAMBA, the First Powerful Hybrid Model is Here
Toward a Subquadratic Future

For almost six years, nothing has beaten the Transformer, the heart of all Generative AI models.
However, due to its excessive costs, many have tried to dethrone it, to no avail.
But we can finally hear the winds of change.
Not to substitute the Transformer, but to create hybrids, a new generation of Large Language Models that offer the best of both worlds, ultra performance with high efficiency.
And we finally have our very first production-grade model, Jamba.
This insight and others have mostly been previously shared in my weekly newsletter, TheTechOasis.
If you want to be up-to-date with the frenetic world of AI while also feeling inspired to take action or, at the very least, to be well-prepared for the future ahead of us, this is for you.
🏝Subscribe below🏝
A Quadratic Nightmare
In technology, there’s always a trade-off. And in the case of the Transformer, it’s a big one.
And although we aren’t going into the technical details of the Transformer for the sake of the length, here’s the gist.
Good, but Very Expensive
Models like ChatGPT, Gemini, or Claude are all based on a concatenation of Transformer blocks:
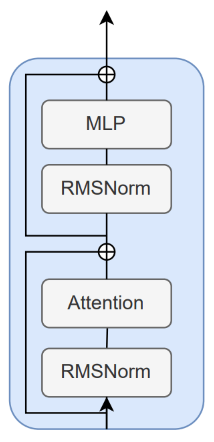
Each of these blocks contains two things:
- An attention layer
- A Feedforward layer (MLP in the image)
The former enforces the renowned attention mechanism, a mixing operation that processes the input sequence and helps each word in the sequence pay attention to the words that matter (verbs into nouns, adverbs to verbs, pronouns to nouns, and so on).
Click here for a full review of the attention mechanism.
The latter is a feedforward layer, which helps in extracting key features and relationships from the data.
FFNs also add non-linearity to the overall model, which is essential for the LLM to be capable of approximating non-linear functions, a fundamental requisite to work with complex data like text.
RMSNorm normalizes the layer weights to stabilize training, which is important in Transformer training but fundamental in more unstable operators like Mamba or Hyena.
But attention has a problem: it has quadratic cost complexity. In layman’s terms, if the input sequence is doubled, the cost of processing it quadruples.
In practice, for short sequences, this isn’t much of an issue, but for longer sequences, the computation and memory requirements both skyrocket, especially due to the KV Cache.
ChatGPT’s best try at having memory
The KV Cache is the closest thing models like ChatGPT have to memory, as it stores the attention scores avoiding having to recompute them, causing massive compute savings.
The biggest issue with the KV Cache, however, is that Transformers are notorious for not having a compressed state. In layman’s terms, they store the previous context but do not compress it, which essentially means that the longer the sequence, the larger the cache gets.
They may seem harmless at first (for short sequences model size is the limiting factor) but for longer sequences, things change.
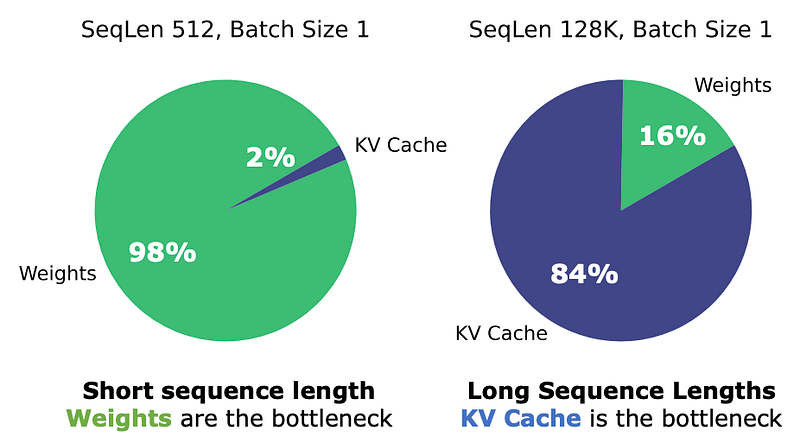
For reference, if we look at popular models like LLaMa-2 7B or Mistral-7B, despite their small size, for a sequence of 256k tokens (approximately 192k words) they require 128GB and 32GB respectively to handle the KV Cache size, despite the latter using Grouped-Query Attention.
For a full in-depth review, click the following link: KV Cache.
And the incredible thing is that all this time we have been referring to one single sequence.
For this reason, for years, the Transformer has been incapable of scaling to larger sequence lengths due to its prohibitive costs.
And despite some newsworthy innovations like Ring Attention facilitating things by reducing communication overhead between GPUs, it still doesn’t solve the ‘quadratic barrier’.
And this takes us to Jamba, which comes packed with many surprises and the promise of solving the quadratic problem without compromising quality.
Mamba, Attention, and MoE
Jamba, an open-source model created by AI21 labs, is an LLM that looks too good to be true.
Instead of just using Transformer blocks, it includes another piece in the puzzle, Mamba blocks.
But why?
Mamba is an alternative architecture to the Transformer whose main difference is that it’s a stateful architecture.
In other words, while the Transformer has to consider the entire context every single time, as we mentioned earlier, Mamba has fixed-sized memory, or state.
Imagine you are writing a book, and you are writing page 101. But for every single new word you write, you have to reread all the previous pages every time to get the context.
That’s how Transformers work, as they don’t have the capacity to keep an updated state of the previous context.
On the flip side, Mamba architectures keep an updatable but compressed memory of all previous context.
As this state is fixed in size (much more computationally efficient unlike the KV Cache, which grows with sequence length), for every single new input the Mamba block has to decide if it’s relevant for context or not.
For instance, if the next word is ‘um’, you probably don’t want to update your memory.
Sadly, the reality is that Mamba underperforms Transformers quality-wise, so researchers still need to keep the Transformer somehow.
Although not fully proven, it seems that the reason Mamba underperforms is due to its incapacity to create induction heads, the capability of ‘copy & pasting’ patterns from data that is thought to being the key to in-context learning, LLMs’ main superpower.
Additionally, Jamba incorporates one added feature, mixture-of-experts.
In simple terms, for every prediction, only a fraction of the model runs, allowing researchers to scale to huge sizes while reducing computation fairly.
For more on MoEs, read my deep-dive on what Mixture-of-Experts is.
In the case of Jamba, that means that even though it has 52 billion parameters, only 12 billion are activated for every single prediction.
This, added to the fact that Jamba has a 1:7 ratio between Transformer and Mamba blocks, means that the required cache is very small in comparison.

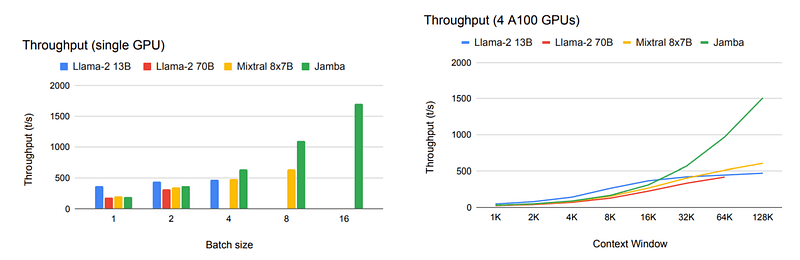
Also, the combined effects of using Mamba and MoE allow it to have insane throughputs (tokens per second prediction), much higher than much smaller models like LLaMa2 13B despite being much larger:
And despite the considerable reduction in compute and memory requirements, the model is perfectly competitive with standard, attention-based models:
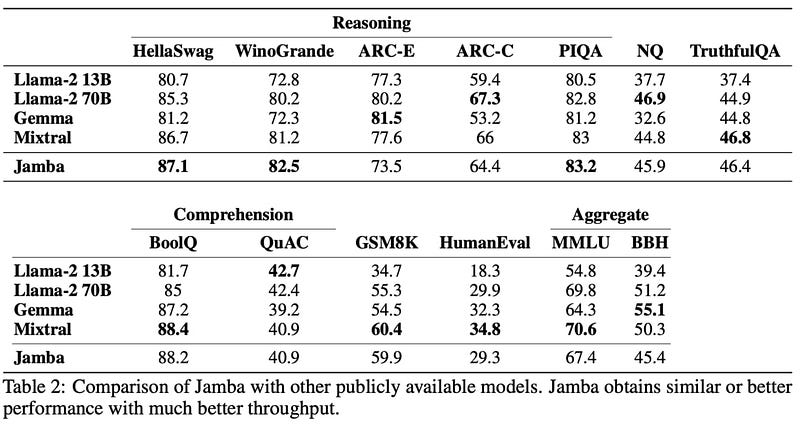
Remember, Jamba isn’t hear to set a new state-of-the-art, but to prove that models that are much efficient to run can match the performance of standard LLMs, which had not been achieved until now.
Jamba, are you real?
Overall, Jamba looks really good, almost too good to be true.
However, it’s a very clever clusterization of several advancements in the field that, together, show great potential for setting new standards, at least when it comes to making AI scalable.
In my humble opinion, it’s a matter of time before hybrid architectures become the golden standard, and Jamba seems to be the first one that truly exemplifies this trend.
On a final note, if you have enjoyed this article, I share similar thoughts in a more comprehensive and simplified manner for free on my LinkedIn.
If preferable, you can connect with me through X.
Looking forward to connecting with you.




